一种基于遮挡修复的多步态识别方法
本发明涉及计算机视觉与模式识别,具体涉及一种基于遮挡修复的多步态识别方法,主要涉及包括生物特征识别、身份识别、图像处理、深度图像和遮挡修复的多步态识别。
背景技术:
1、由于步态识别是最关键的远距离生物特征识别技术之一,在学术界和工业界越来越受欢迎。基于黑白轮廓的步态识别方法大致可以分为三种类型,即基于模板的方法、基于集合的方法和基于视频的方法。一般来说,基于模板的方法首先聚合序列的所有时间信息以生成模板。基于集合的方法以步态序列的每一帧为单位提取步态特征。基于视频的方法直接使用3d cnn从步态序列中提取时空特征以达到识别目的。
2、基于姿势的步态识别方法首先提取人体的2d姿势或3d姿势,然后使用基于深度学习的框架来生成特征表示。由于人体的关键姿势非常有限,现阶段基于姿势的步态识别方法不能在真实步态数据集中生成有区别的特征表示。
3、尽管现在单人步态识别上取得了重大进展,但许多证据表明,多人步态识别是步态识别领域中更加具有挑战性的任务,因为多人同行时会产生严重的人体遮挡,这增加了识别的难度。
技术实现思路
1、本发明的目的是为了解决当前多步态识别方法在实际应用场景中由于人体遮挡问题所导致的识别精度显著下降的难题,提供一种基于遮挡修复的多步态识别方法。
2、本发明的目的可以通过采取如下技术方案达到:
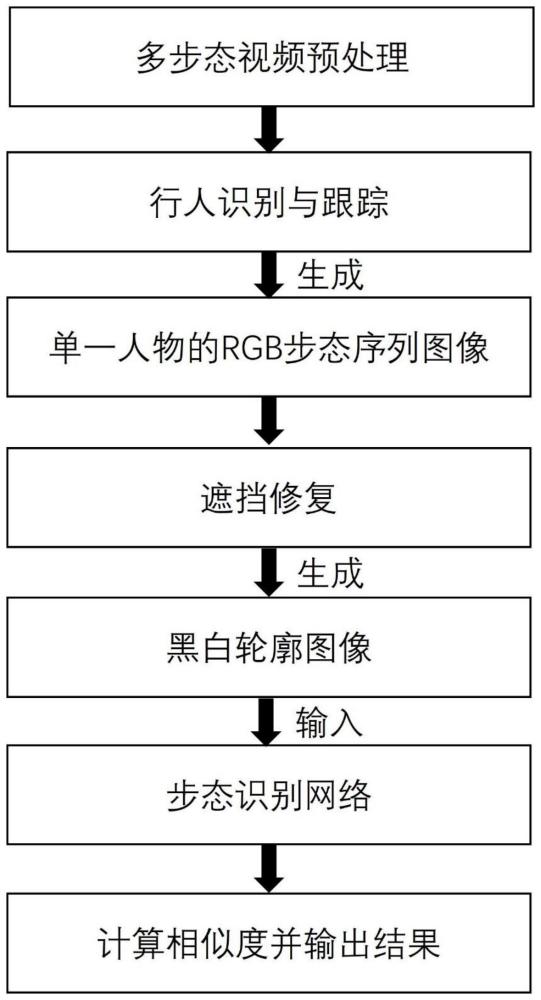
3、一种基于遮挡修复的多步态识别方法,所述步态识别方法包括以下步骤:
4、s1、在室内场景下收集并整理多人同行步态视频,采集多个视角下1人、2人和3人共同行走视频,得到步态视频序列,将步态视频序列作为多步态数据集,并分为训练集和测试集两部分;
5、s2、从步态视频序列中提取单一人物的rgb步态序列图像;
6、s3、从所述单一人物的rgb步态序列图像中提取人物3d姿态,得到被遮挡的3d姿态步态序列;
7、s4、训练运动填充器,并利用运动填充器,补充所述被遮挡的3d姿态步态序列,得到无遮挡的3d姿态步态序列,其中,所述运动填充器采用transformer架构,包括识别网络、生成网络和条件网络,所述识别网络使用transformer编码器将非连续3d姿势编码为上下文序列;所述生成网络通过transformer解码器和多层感知器mlp使用潜在码和上下文序列生成无遮挡运动,所述条件网络生成潜在码z的高斯分布;
8、s5、对所述无遮挡的3d姿态步态序列降维,生成二维的黑白轮廓步态序列图像;
9、s6、将所述黑白轮廓图像输入步态识别网络进行特征提取得到二维图像步态特征;
10、s7、将步骤s6得到的二维图像步态特征与多步态数据集中不同步态视频序列进行特征相似度计算,同时用损失函数l显示预测值和实际值之间的差距,并通过反向传播更新参数对步态识别网络进行训练,当损失函数l的取值小于设定阈值,完成训练;
11、s8、采集行人步态视频执行步骤s2-s6得到二维图像步态特征,计算二维图像步态特征与多步态数据集中不同步态视频序列特征相似度,以相似度最高的步态视频序列对应的样本id作为多步态识别结果。
12、进一步地,所述步骤s1中收集并整理多人同行步态视频,过程如下:在室内场景下四个角度同时采集1人、2人和3人的行走视频,其中,四个视角为以行人行走直线为直径的半圆上,以45度角为间隔的四个拍摄视角。利用多角度步态数据可以让步态识别网络学习到不同角度下的步态特征,提升模型精度和鲁棒性。
13、进一步地,所述步骤s2中提取单一人物的步态序列rgb图像,过程如下:
14、利用yolov3对步态视频序列进行人物检测和跟踪,将多人同行视频序列中的每个人物进行裁剪,得到单一人物的rgb步态序列图像。从多人同行情况下截取单人步态和多人步态,有利于步态识别网络学习单人步态和多人步态之间不变的高维特征。yolov3模型属于现有技术,出自yolov3:an incremental improvement论文,joseph redmon,alifarhadi作者。
15、进一步地,所述步骤s3中提取被遮挡的3d姿态步态序列,过程如下:
16、将单一人物的rgb步态序列图像作为输入,由3d姿态估计模型hybrik从步态序列图像中识别出人体姿态,得到基于3d骨骼关节点重建的人体网格。3d骨骼关节点包括了:头顶、鼻子、脖子、左肩、右肩、左肘、右肘、左腕、右腕、左手、右手、左臀、右臀、左膝、右膝、左踝、右踝、左脚跟、右脚跟等29个人体骨骼关节点,用于重建人体网格。3d姿态估计模型hybrik属于现有技术,出自hybrik:a hybrid analytical-neural inverse kinematicssolution for 3d human pose and shape estimation论文,li,jiefeng and xu,chaoand chen,zhicun and bian,siyuan and yang,lixin and lu,cewu作者。
17、进一步地,所述步骤s4中训练运动填充器,过程如下:
18、运动填充器的整体网络设计采用transformer架构,它由三部分组成:(1)识别网络。使用transformer编码器将非连续3d姿势编码为上下文序列;(2)生成网络。通过transformer解码器和多层感知器(mlp)使用潜在码和上下文序列生成无遮挡运动;(3)条件网络。生成潜在码z的高斯分布。整体网络流程为:将非连续3d姿态作为输入,经过识别网络生成上下文序列,再将上下文序列和连续3d姿态输入到条件网络中,生成潜在码。最后将潜在码和上下文序列输入到生成网络中,生成连续的3d姿态。
19、识别网络结构为顺序连接的全连接层-1、全连接层-2、transformer编码器-1。
20、生成网络结构为顺序连接的全连接层-1、全连接层-2、transformer解码器-1、多层感知机mlp。
21、条件网络结构为顺序连接的全连接层-1、全连接层-2、transformer解码器-1。
22、利用运动捕捉数据集amass训练运动填充器。对于数据集中连续的m帧真实运动状态,随机遮挡[n,m-n]帧中的真实运动状态,并保留前n帧和后n帧作为运动填充器识别网络的输入,连续的m帧真实运动状态作为运动填充器条件网络的输入,并用学习率为0.001的adma优化器降低梯度值。训练周期为2000,批大小为128。amass数据集属于现有技术,出自amass:archive of motion capture as surface shapes论文,naureen mahmood,nimaghorbani,nikolaus f.troje,gerard pons-moll,michael j.black作者。
23、进一步地,所述步骤s4中利用运动填充器,补充被遮挡的3d姿态步态序列,得到无遮挡的3d姿态步态序列,过程如下:
24、将步骤s3得到的有遮挡的3d姿态步态序列输入到上述运动填充器中进行推理,生成连续的、非缺失的完整3d姿态步态序列。
25、进一步地,所述步骤s5中生成二维的黑白轮廓步态序列图像,过程为:
26、先获取完整3d姿态步态序列中每一帧3d姿态顶点信息和位移信息,利用pytorch3d库生成渲染后的图像掩膜,提取图像掩膜中的有效像素,保留为白色像素,而背景保存为黑色像素,形成人体为白色、背景为黑色的黑白轮廓图。在pytorch3d中,将3d人体姿态转换为二维图像的过程如下:
27、r1、投影:pytorch3d使用相机投影将3d点投影到2d图像平面。相机投影可以使用透视投影矩阵来表示,其中包括相机的旋转、平移和内部参数(如焦距和主点)。表达式为:
28、pose2d=kⅹrⅹ(verts-t)
29、其中,verts是3d姿态的顶点坐标,r是相机的旋转矩阵,t是相机的平移矩阵,k是相机的内参矩阵。
30、r2、光栅化:将投影后的3d点映射到图像平面上的过程,即光栅化。这包括确定每个像素受到哪个3d点的影响,以及在该像素处的颜色等。这个过程可以表示为:
31、image=f(pose2d,faces)
32、其中,pose2d是投影后的姿态坐标,faces是3d姿态的面信息,f()是光栅化函数。
33、r3、着色:渲染过程中,可以对光栅化后的图像进行着色。着色的方式取决于使用的着色器(shader)的类型。这一步可以表示为:
34、image2d=s(image,lights)
35、image是光栅化后的图像,lights是光源信息,s()是着色器。将输出的image2d输出为白色像素,背景像素设为黑色,即得到黑白轮廓图像。
36、进一步地,所述步骤s6中提取得到二维图像步态特征,过程为:所述步态识别网络结构为顺序连接的卷积层conv-1、卷积层conv-2、卷积层conv-3、池化层maxpool-1、卷积层conv-4、卷积层conv-5、池化层maxpool-2、卷积层conv-6、卷积层conv-7,卷积层conv-3输出浅层阶段的步态特征,卷积层conv-5输出中层阶段的步态特征,卷积层conv-7输出深层阶段的步态特征。以卷积层conv-7的输出作为二维图像步态特征。
37、进一步地,所述损失函数l=ltri+lcla,其中ltri表示三元损失函数,lcla表示交叉熵损失函数,三元损失函数ltri的表达式为:
38、ltri=max(d(x1,x2)-d(x1,x3)+margin,0)
39、其中d(.,.)表示向量之间的欧式距离,margin表示调整因子,max()表示求两个数的最大值,x1、x2、x3分别代表输入的三个步态特征;
40、交叉熵损失函数lcla的表达式为:
41、
42、其中d(yx|x)表示完整步态特征x对应的预测标签为yx的概率,yx表示完整步态特征x对应的真实标签,n表示步态序列的数目。
43、进一步地,所述多步态识别方法还包括测试步骤,过程如下:
44、t1、将测试集分为画廊和探针两部分,以单人行走步态数据为画廊序列,画廊序列数量为6个。以多人同行步态数据为探针序列,探针序列数量为4个,画廊序列的每个标签都是不一样的;
45、t2、分别将探针序列和画廊序列的步态数据输入到步态识别网络中,分别得到探针步态向量和画廊步态向量;
46、t3、分别计算探针步态向量和画廊步态向量的欧式距离,并求其最小值,得到与探针步态向量相似度最高的画廊步态向量,即完成多步态识别。
47、本发明相对于现有技术具有如下的优点及效果:
48、1、本发明对多人同行情况下的步态识别做出了识别定义,从多人步态图像中抽取单一个体的步态图像序列,并从中提取黑白轮廓图像和人体骨骼关节点数据。测试过程是以单人行走步态数据作为画廊,以多人同行步态数据作为探针,将两种行走状态进行对比以达到识别同行人中单一个体的身份。
49、2、本发明充分考虑到了实际环境中多位同行人行走的步态情况,拍摄符合实际情况的多步态数据集,为基于遮挡修复的多步态识别做好了数据支撑。
50、3、本发明结合遮挡修复和步态识别技术,为解决多人同行状态下的步态识别问题提供一个全新的解决思路和方法。目前多步态研究都是利用有遮挡的、残缺的步态特征进行步态识别,导致现有步态识别模型在多步态中识别率低。本发明提出的方法能够有效提取行人完整的步态特征,并且在降低穿戴影响的同时,提高多步态识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!