基于Spark框架下的IPV6地址数据处理方法、系统及设备与流程
本公开涉及数据处理领域,具体涉及一种基于spark框架下的ipv6地址数据处理方法、系统、设备及存储介质。
背景技术:
1、随着互联网技术的不断发展,ipv6地址作为新一代的互联网协议地址,正在逐渐取代ipv4地址。同时,spark作为一个快速,通用的大数据处理引擎,它允许在内存中以集群的方式处理大规模的数据集。spark基于scala语言开发,并具有java、scala及python等语言的api接口。spark提供了包括sql查询、流处理、机器学习、图处理等在内的一体化的数据湖解决方案。然而,随着网站的ipv6活跃地址访问数据日益增加,传统的采集与数据处理手段存在各种问题,首先在处理海量数据时存在处理时间较长和响应慢的问题,以及在做一些复杂处理时需要反复进行数据的读取操作,其次在容错方面,当出现一些数据问题时需要人工判断错误数据的来源,导致处理效率低下。
技术实现思路
1、(一)要解决的技术问题
2、鉴于上述问题,本公开提供了一种基于spark框架下的ipv6地址数据处理方法、系统、设备及存储介质,以至少部分解决数据处理时效率低,反应时间长,实时数据处理不够及时等问题。
3、(二)技术方案
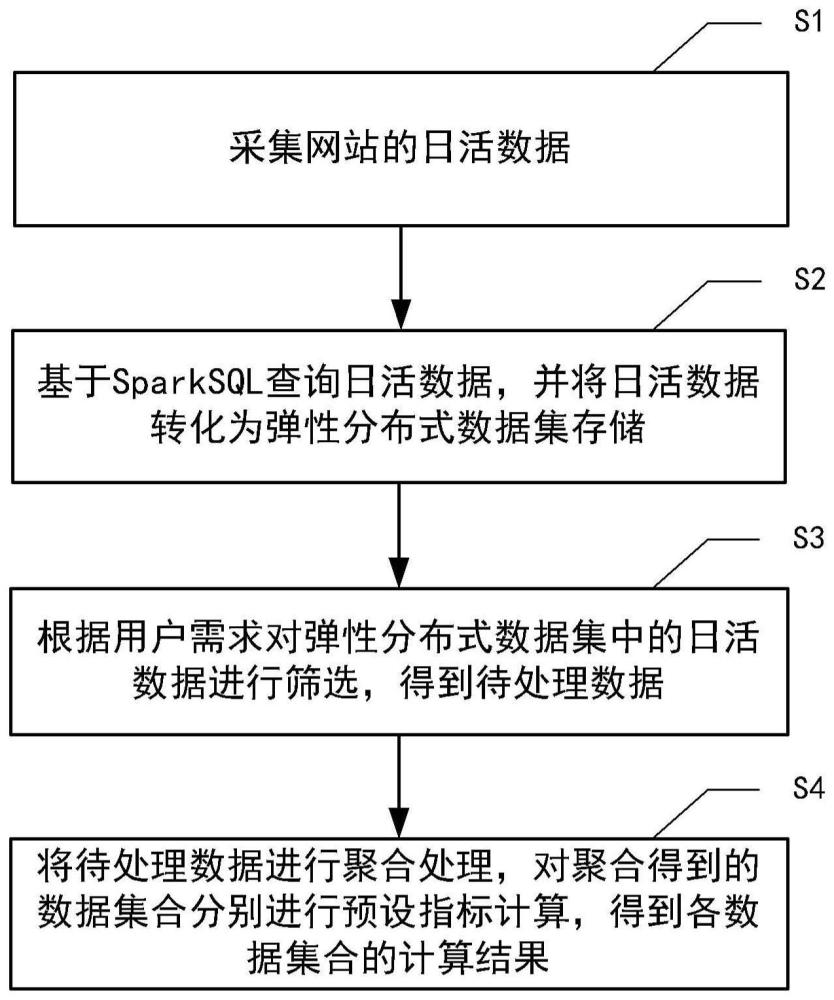
4、本公开的第一方面提供一种基于spark框架下的ipv6地址数据处理方法,包括:采集网站的日活数据;基于sparksql查询所述日活数据,并将所述日活数据转化为弹性分布式数据集存储;根据用户需求对弹性分布式数据集中的所述日活数据进行筛选,得到待处理数据;将所述待处理数据进行聚合处理,对聚合得到的数据集合分别进行预设指标计算,得到各所述数据集合的计算结果。
5、根据本公开的实施例,所述采集网站的日活数据包括:从各种数据源获取数据和/或动态监听数据库的变化并记录所述数据,其中,所述数据源包括数据库整表和源文件;对所述数据进行清洗,得到符合要求的所述日活数据。
6、根据本公开的实施例,所述对所述数据进行清洗,得到符合要求的所述日活数据包括:对所述数据进行特征分析,去除与网站无关的第一流量数据,得到第二流量数据;分析所述第二流量数据中各字段的特征,从所述第二流量数据中筛选出符合预设字段条件的所述日活数据。
7、根据本公开的实施例,所述分析所述第二流量数据中各字段的特征,从所述第二流量数据中筛选出符合预设字段条件的所述日活数据包括:通过地址库将所述第二流量数据划分为入网流量和出网流量;基于所述入网流量和出网流量,分别比较各字段的特征,以筛选出符合预设字段条件的所述日活数据。
8、根据本公开的实施例,所述采集网站的日活数据之后,所述方法包括:根据所述日活数据中各字段的特征,将所述日活数据存储进对应的数据库表中。
9、根据本公开的实施例,所述基于sparksql查询所述日活数据,并将所述日活数据转化为弹性分布式数据集存储包括:将所述弹性分布式数据集提交到分布式集群,以并行处理所述弹性分布式数据集中的日活数据。
10、根据本公开的实施例,还包括:将所述日活数据进行可视化和图形化,并以多种图形化的方式展示所述日活数据。
11、本公开的第二方面提供了一种基于spark框架下的ipv6地址数据处理系统,包括:采集模块,用于采集网站的日活数据;查询和存储模块,用于基于sparksql查询所述日活数据,并将所述日活数据转化为弹性分布式数据集存储;筛选模块,用于根据用户需求对弹性分布式数据集中的所述日活数据进行筛选,得到待处理数据;计算模块,用于将所述待处理数据进行聚合处理,对聚合得到的数据集合分别进行预设指标计算,得到各所述数据集合的计算结果。
12、本公开的第三方面提供了一种电子设备,包括:存储器,处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时,实现所述的ipv6地址数据处理方法中的各个步骤。
13、本公开的第四方面提供了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现所述的ipv6地址数据处理方法中的各个步骤。
14、(三)有益效果
15、本公开提供的基于spark框架下的ipv6地址数据处理方法、系统、设备及存储介质,基于spark框架将一些中间数据存储在内存中,以对数据进行迭代计算,极大的提高了数据处理的效率。并且,采用rdd数据集,可以自动从节点失败中恢复过来,即如果某个节点上的rdd分区,因为节点故障,导致数据丢失,会自动通过自己的数据来源重新计算该分区。
技术特征:
1.一种基于spark框架下的ipv6地址数据处理方法,其特征在于,包括:
2.根据权利要求1所述的基于spark框架下的ipv6地址数据处理方法,其特征在于,所述采集网站的日活数据包括:
3.根据权利要求2所述的基于spark框架下的ipv6地址数据处理方法,其特征在于,所述对所述数据进行清洗,得到符合要求的所述日活数据包括:
4.根据权利要求3所述的基于spark框架下的ipv6地址数据处理方法,其特征在于,所述分析所述第二流量数据中各字段的特征,从所述第二流量数据中筛选出符合预设字段条件的所述日活数据包括:
5.根据权利要求1所述的基于spark框架下的ipv6地址数据处理方法,其特征在于,所述采集网站的日活数据之后,所述方法包括:
6.根据权利要求1所述的基于spark框架下的ipv6地址数据处理方法,其特征在于,所述基于sparksql查询所述日活数据,并将所述日活数据转化为弹性分布式数据集存储包括:
7.根据权利要求1所述的基于spark框架下的ipv6地址数据处理方法,其特征在于,还包括:
8.一种基于spark框架下的ipv6地址数据处理系统,其特征在于,包括:
9.一种电子设备,包括:存储器,处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时,实现权利要求1至7中的任一项所述的ipv6地址数据处理方法中的各个步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现权利要求1至7中的任一项所述的ipv6地址数据处理方法中的各个步骤。
技术总结
本公开提供了一种基于Spark框架下的IPV6地址数据处理方法、系统、设备及介质,该方法包括:采集网站的日活数据;基于SparkSQL查询日活数据,并将日活数据转化为弹性分布式数据集存储;根据用户需求对弹性分布式数据集中的日活数据进行筛选,得到待处理数据;将待处理数据进行聚合处理,对聚合得到的数据集合分别进行预设指标计算,得到各数据集合的计算结果。
技术研发人员:王显,李星,吴建平,刘知刚,李腾,陶敬东,李朴,谢华
受保护的技术使用者:赛尔网络有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!