基于时空增强三维注意力重参数化的视频分类方法及装置与流程
本发明属于视频分析与模式识别,尤其涉及基于时空增强三维注意力重参数化的视频分类方法及装置。
背景技术:
1、视频分类任务在机器人、人机交互等领域有广泛的应用价值。大量基于卷积神经网络的视频分类方法(比如c3d、i3d和slowfast等)取得了一定的进展,但它们仍然受到卷积操作缺乏长程建模能力的制约。近年来,随着transformer在自然语言处理领域的成功,很多基于transformer的视频分类方法得到了提出。比如timesformer和vivit探索利用空间和时间注意力操作将视频建模解耦为表观和运动建模;uniformer通过在transformer网络的浅层和深层分别学习局部和全局关联关系,以达到运算开销与分类效果的折中;mvit则参考卷积神经网络的设计,通过在网络的不同阶段逐渐降低特征的空间维度并增加其通道维度,学习得到多尺度特征金字塔。尽管基于transformer的视频分类方法表现出了出色的效果,但是较高的时间复杂度影响限制了其实际应用范围。重参数化技术是一种将训练和测试阶段网络结构进行解耦的技术。acnet、repvgg和repmlp等工作将重参数化技术与卷积神经网络和多层感知机相结合,针对图像分类任务在提升网络训练效果的同时,保持了模型测试时的运算开销,但是在视频分类任务上重参数化技术尚未得到有效应用。
技术实现思路
1、本发明为了解决上述技术问题,提供基于时空增强三维注意力重参数化的视频分类方法及装置。
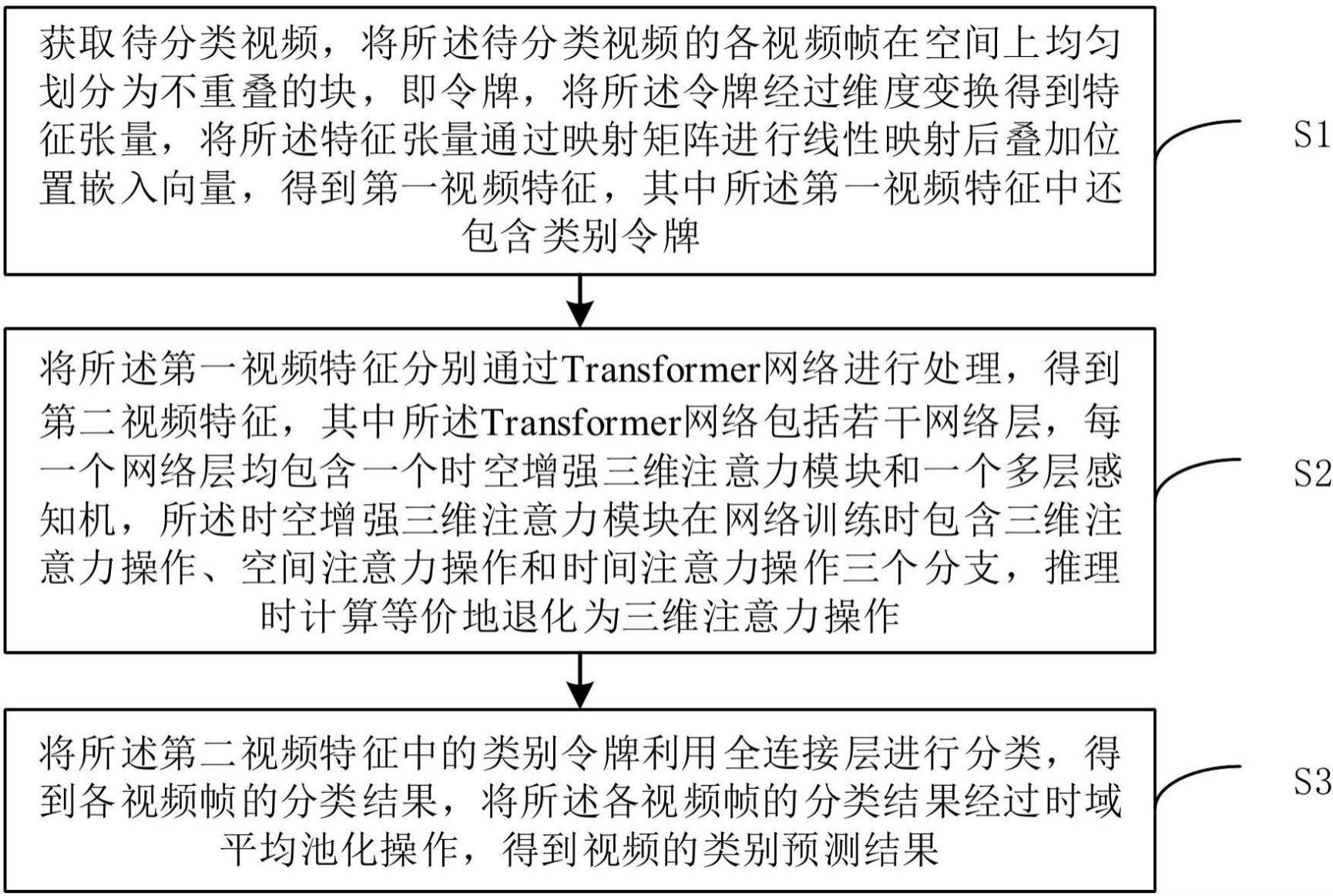
2、根据本技术实施例的第一方面,提供一种基于时空增强三维注意力重参数化的视频分类方法,包括:
3、获取待分类视频,将所述待分类视频的各视频帧在空间上均匀划分为不重叠的块,即令牌,将所述令牌经过维度变换得到特征张量,将所述特征张量通过映射矩阵进行线性映射后叠加位置嵌入向量,得到第一视频特征,其中所述第一视频特征中还包含类别令牌;
4、将所述第一视频特征分别通过transformer网络进行处理,得到第二视频特征,其中所述transformer网络包括若干网络层,每一个网络层均包含一个时空增强三维注意力模块和一个多层感知机,所述时空增强三维注意力模块在网络训练时包含三维注意力操作、空间注意力操作和时间注意力操作三个分支,推理时计算等价地退化为三维注意力操作;
5、将所述第二视频特征中的类别令牌利用全连接层进行分类,得到各视频帧的分类结果,将所述各视频帧的分类结果经过时域平均池化操作,得到视频的类别预测结果。
6、进一步地,所述第一视频特征,其中为所述张量,e为所述映射矩阵,为所述位置嵌入向量,所述类别令牌连接到上。
7、进一步地,在模型训练过程中:
8、将第n层的时空增强三维注意力模块的输入经过嵌入矩阵进行线性映射,得到三维注意力操作的查询张量、键张量和值张量;
9、对所述三维注意力操作的查询张量、键张量和值张量进行变形操作,对应得到空间注意力操作以及时间注意力操作的查询张量、键张量和值张量;
10、由三维注意力操作、空间注意力操作和时间注意力操作对应的查询张量和键张量,计算得到各注意力操作的注意力矩阵;
11、将各注意力操作的注意力矩阵经过softmax操作后作用于对应的值张量,并将结果利用可学习的各注意力分支的权重进行加权累加,得到混合注意力操作的结果。
12、进一步地,各注意力操作的注意力矩阵,和通过下式计算:
13、
14、其中,表示归一化因子,、、为三维注意力操作、空间注意力操作和时间注意力操作对应的查询张量,、、为三维注意力操作、空间注意力操作和时间注意力操作对应的键张量。
15、进一步地,在模型推理过程中:
16、将第n层的时空增强三维注意力模块的输入经过嵌入矩阵进行线性映射,得到三维注意力操作的查询张量、键张量和值张量;
17、由所述三维注意力操作的查询张量、键张量,计算三维注意力操作的注意力矩阵;
18、从所述三维注意力操作的注意力矩阵中,提取空间注意力和时间注意力操作的注意力矩阵;
19、将所述空间注意力操作和时间注意力操作的注意力矩阵与三维注意力操作的注意力矩阵对齐到相同维度,将对齐后的各注意力操作的注意力矩阵经过softmax操作后,利用训练阶段学习到的各注意力分支的权重进行加权累加,将累加结果作用于三维注意力操作的值张量,得到混合注意力操作的结果;或,
20、将所述空间注意力操作和时间注意力操作的注意力矩阵经过softmax操作后,利用训练阶段学习到的各注意力分支的权重,加权叠加到经过softmax操作的三维注意力操作的注意力矩阵的相应区域,然后将累加结果作用于三维注意力操作的值张量,得到混合注意力操作的结果。
21、进一步地,由所述三维注意力操作的查询张量、键张量,通过下式计算三维注意力操作的注意力矩阵:
22、
23、其中表示归一化因子。
24、进一步地,经过维度扩张操作,即对扩张区域补零,将空间注意力操作和时间注意力操作的注意力矩阵对齐到与三维注意力操作的注意力矩阵相同维度。
25、根据本技术实施例的第二方面,提供一种基于时空增强三维注意力重参数化的视频分类装置,包括:
26、特征获取模块,用于获取待分类视频,将所述待分类视频的各视频帧在空间上均匀划分为不重叠的块,即令牌,将所述令牌经过维度变换得到特征张量,将所述特征张量通过映射矩阵进行线性映射后叠加位置嵌入向量,得到第一视频特征,其中所述第一视频特征中还包含类别令牌;
27、特征转换模块,用于将所述第一视频特征分别通过transformer网络进行处理,得到第二视频特征,其中所述transformer网络包括若干网络层,每一个网络层均包含一个时空增强三维注意力模块和一个多层感知机,所述时空增强三维注意力模块在网络训练时包含三维注意力操作、空间注意力操作和时间注意力操作三个分支,推理时计算等价地退化为三维注意力操作;
28、分类模块,用于将所述第二视频特征中的类别令牌利用全连接层进行分类,得到各视频帧的分类结果,将所述各视频帧的分类结果经过时域平均池化操作,得到视频的类别预测结果。
29、根据本技术实施例的第三方面,提供一种电子设备,包括:
30、一个或多个处理器;
31、存储器,用于存储一个或多个程序;
32、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的方法。
33、根据本技术实施例的第三方面,提供一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现如第一方面所述方法的步骤。
34、本技术的实施例提供的技术方案可以包括以下有益效果:
35、由上述实施例可知,本技术针对基于transformer网络的视频分类方法运算开销较高的问题,提出了一种基于时空增强三维注意力重参数化的视频分类方法。在训练阶段,采用包含三维注意力、空间注意力和时间注意力的三分支结构,自适应地增强具有时空关联的令牌之间的依赖关系,提升了模型的训练效果;在测试阶段,将空间注意力和时间注意力分支融合到三维注意力分支中,从而相对于三维注意力操作只增加了很少的推理开销,提高了模型的实际应用价值。
36、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!