数据处理方法、装置、计算机设备及存储介质与流程
本技术涉及计算机,特别涉及一种数据处理方法、装置、计算机设备及存储介质。
背景技术:
1、在大语言模型的预训练过程中,样本文本数据的质量直接影响着大语言模型的预训练效果。样本文本数据往往包含一些噪声数据,如敏感词、垃圾文本甚至不当言论等。因此,如何清洗样本文本数据中的噪声数据,以保证大语言模型的预训练效果,是一个需要解决的技术问题。
2、相关技术中,通常通过预定义的词库来去除样本文本数据中的噪声数据。例如,使用敏感词库匹配样本文本数据中的敏感词,使用停用词库匹配样本文本数据中的停用词。然后,将敏感词和停用词从样本文本数据中去除,从而实现清洗样本文本数据中的噪声数据。
3、但是,采用上述方法,只能对词库中已经收录的噪声数据进行清洗,无法清洗词库中尚未收录的噪声数据,导致数据清洗的准确率较低,具有一定的局限性。
技术实现思路
1、本技术实施例提供了一种数据处理方法、装置、计算机设备及存储介质,能够高效、全面地识别并去除样本数据集中的噪声文本,不会受到预设词库的限制。所述技术方案如下:
2、一方面,提供了一种数据处理方法,所述方法包括:
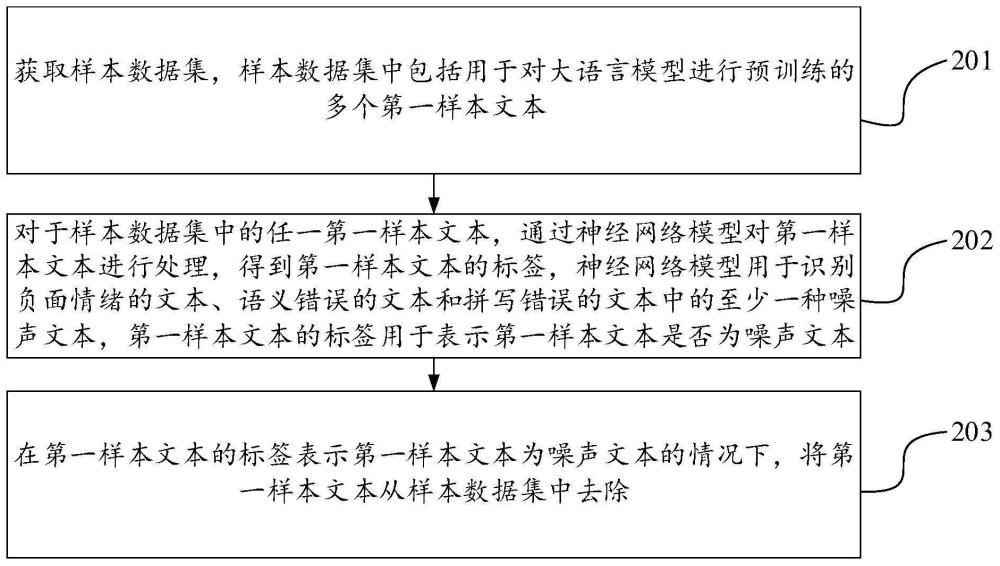
3、获取样本数据集,所述样本数据集中包括用于对大语言模型进行预训练的多个第一样本文本;
4、对于任一第一样本文本,通过神经网络模型对所述第一样本文本进行处理,得到所述第一样本文本的标签,所述神经网络模型用于识别负面情绪的文本、语义错误的文本和拼写错误的文本中的至少一种噪声文本,所述第一样本文本的标签用于表示所述第一样本文本是否为噪声文本;
5、在所述第一样本文本的标签表示所述第一样本文本为噪声文本的情况下,将所述第一样本文本从所述样本数据集中去除。
6、另一方面,提供了一种数据处理装置,所述装置包括:
7、第一获取模块,用于获取样本数据集,所述样本数据集中包括用于对大语言模型进行预训练的多个第一样本文本;
8、识别模块,用于对于任一第一样本文本,通过神经网络模型对所述第一样本文本进行处理,得到所述第一样本文本的标签,所述神经网络模型用于识别负面情绪的文本、语义错误的文本和拼写错误的文本中的至少一种噪声文本,所述第一样本文本的标签用于表示所述第一样本文本是否为噪声文本;
9、去除模块,用于在所述第一样本文本的标签表示所述第一样本文本为噪声文本的情况下,将所述第一样本文本从所述样本数据集中去除。
10、在一些实施例中,所述识别模块,包括:
11、确定单元,用于对于任一第一样本文本,通过所述神经网络模型确定所述第一样本文本的第一概率、第二概率和第三概率中的至少一种概率,所述第一概率为所述第一样本文本为负面情绪的文本的概率,所述第二概率为所述第一样本文本为语义错误的文本的概率,所述第三概率为所述第一样本文本为拼写错误的文本的概率;
12、生成单元,用于通过所述神经网络模型,根据所述第一样本文本的第一概率、第二概率和第三概率中的至少一种概率,生成所述第一样本文本的标签。
13、在一些实施例中,所述神经网络模型包括情绪识别模块和字符检测模块中的至少一种,所述情绪识别模块用于对输入的样本文本进行语义分析和情绪识别,所述字符检测模块用于对输入的样本文本进行字符检测;
14、所述确定单元,用于对于任一第一样本文本,在所述神经网络模型包括所述情绪识别模块的情况下,通过所述情绪识别模块,对所述第一样本文本进行语义分析,得到所述第一样本文本的语义,并根据所述第一样本文本的语义,确定所述第一样本文本的第二概率;通过所述情绪识别模块,根据所述第一样本文本的语义,对所述第一样本文本进行情感极性的识别,得到所述第一样本文本的第一概率,所述情感极性包括正面情绪、负面情绪以及中性情绪;对于任一第一样本文本,在所述神经网络模型包括所述字符检测模块的情况下,通过所述字符检测模块对所述第一样本文本中的多个字符进行检测,得到所述第一样本文本的第三概率。
15、在一些实施例中,所述生成单元,用于在所述至少一种概率中存在任一概率大于预设概率的情况下,通过所述神经网络模型生成第一标签,所述第一标签用于表示所述第一样本文本为噪声文本;在所述至少一种概率均不大于所述预设概率的情况下,通过所述神经网络模型生成第二标签,所述第二标签用于表示所述第一样本文本为非噪声文本。
16、在一些实施例中,所述装置还包括:
17、确定模块,用于在所述第一样本文本的至少一种概率均不大于预设概率的情况下,分别确定所述至少一种概率与所述预设概率之间的差值;
18、输出模块,用于对于所述至少一种概率中的任一概率,在所述概率与所述预设概率之间的差值小于差值阈值的情况下,输出所述第一样本文本和提示信息,所述提示信息用于提示是否在所述样本数据集中去除所述第一样本文本;
19、所述去除模块,还用于响应于接收到对所述提示信息的确认操作,将所述第一样本文本从所述样本数据集中去除。
20、在一些实施例中,所述神经网络模型还包括字符纠正模块,所述字符纠正模块用于纠正拼写错误的文本;
21、所述识别模块,还用于对于任一第一样本文本,在所述第一样本文本的第一概率和第二概率均不大于预设概率,所述第一样本文本的第三概率大于所述预设概率的情况下,通过所述字符纠正模块,对所述第一样本文本中的至少一个字符进行纠正操作,得到目标样本文本,所述纠正操作包括插入字符、删除字符、替换字符和更改字符位置中的至少一项;通过所述神经网络模型,确定所述目标样本文本的第一概率、第二概率和第三概率中的至少一种,并生成所述目标样本文本的标签。
22、在一些实施例中,所述装置还包括:
23、添加模块,用于在所述目标样本文本的标签表示所述目标样本文本为非噪声文本的情况下,将所述目标样本文本添加到所述样本数据集。
24、在一些实施例中,所述装置还包括:
25、第二获取模块,用于获取原始数据集,所述原始数据集中包括多个第二样本文本;
26、预处理模块,用于对于所述原始数据集中的任一第二样本文本,对所述第二样本文本进行预处理,得到所述样本数据集中对应的第一样本文本,所述预处理包括分词处理、去除停用词和去除标点符号中的至少一项。
27、在一些实施例中,所述装置还包括:
28、训练模块,用于获取第三样本文本和所述第三样本文本的真实标签,所述真实标签用于表示所述第三样本文本是否为负面情绪的文本、语义错误的文本和拼写错误的文本中任一类型的噪声文本;通过所述神经网络模型对所述第三样本文本进行处理,得到所述第三样本文本的预测标签;基于所述真实标签和所述预测标签,确定所述神经网络模型的训练损失;基于所述训练损失,训练所述神经网络模型。
29、另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器用于存储至少一段计算机程序,所述至少一段计算机程序由所述处理器加载并执行以实现本技术实施例中的数据处理方法。
30、另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一段计算机程序,所述至少一段计算机程序由处理器加载并执行以实现本技术实施例中的数据处理方法。
31、另一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行以实现本技术实施例中的数据处理方法。
32、本技术实施例提供了一种数据处理方法,由于样本文本的质量直接影响着大语言模型的预训练效果。因此,在预训练大语言模型之前,先通过神经网络模型对样本文本进行识别,确定样本文本是否为负面情绪文本、语义不当的文本或者拼写错误的文本等噪声文本。在样本文本为噪声文本的情况下,该样本文本不利于大语言模型的预训练。因此,将该样本文本从样本数据集中去除。通过上述方法,能够高效、全面地识别并去除样本数据集中的噪声文本,不会受到预设词库的限制,从而提高通过样本数据集对大语言模型进行预训练的训练效率和训练质量。
- 还没有人留言评论。精彩留言会获得点赞!