一种基于ST-GCN和YOLOv5n的驾驶员吸烟检测算法
本发明属于检测算法,具体涉及一种基于st-gcn和yolov5n的驾驶员吸烟检测算法。
背景技术:
1、驾驶过程是一种复杂的控制与信息交互过程,驾驶员极易受到自身及外界环境的影响。根据以往的数据统计,绝大部分交通事故都是由驾驶员自身精神状态、注意力不集中、驾驶行为不规范所导致。其中驾驶过程中吸烟行为普遍存在,一方面,它会降低驾驶员的应急反应能力、色彩识别能力和肢体协调能力,存在较大安全隐患;另一方面,驾驶员吐出的烟雾也可能对车内其他人造成二手烟危害。虽然国家没有明文规定开车抽烟是违法行为,但由于吸烟行为而导致的不规范行驶或造成的交通事故都会受到处罚,这也导致对驾驶员吸烟行为的监管被严重忽略。
2、目前,吸烟检测的相关研究可分为基于硬件设备和基于计算机视觉的检测方法。其中硬件设备包括烟雾探测器和惯性传感器等可穿戴设备,它们主要利用呼出烟雾的浓度和吸烟动作产生惯性动量的方式检测吸烟行为。但在车辆行驶过程中往往会打开车窗或空调,导致烟雾扩散迅速,使得烟雾探测器失效。并且穿戴复杂的设备会给驾驶员带来强烈的不适感。针对这些局限性,近年来基于计算机视觉的方法被广泛应用,主要研究关于车载监控视频的吸烟检测方案。其中基于烟雾多特征的检测方法利用图像处理技术,通过提取烟雾颜色、外观和运动等特征分类判别烟雾。利用吸烟烟雾在不同颜色空间下特有的颜色特征提取疑似烟雾区域;通过计算烟雾凸包周长与轮廓周长的比值、烟雾轮廓内外接矩形面积比代表烟雾的外观特征;分析烟雾飘动特性,采用离散运动党向搜索和主运动方向编码的方式获取烟雾运动特征。虽然这类方法提供了丰富的早期烟雾视觉信息,但依然无法解决烟雾扩散迅速的问题。而烟支目标检测是目前使用较为广泛的方法,它主要利用单阶段或两阶段目标检测算法提取图像中的烟支目标特征。尽管目标检测模型更新迭代迅速,但依然存在误检或漏检问题,而且仅依靠单帧图像提取吸烟特征的约束性较强,主要表现为只要烟支出现在检测范围内就会被判定为吸烟行为。针对该问题已有研究提出相应解决办法,利用吸烟动作检测加以约束。但吸烟动作特征都是基于人为主观构建,不能很好的表征整个吸烟动作状态,导致模型的泛化能力不强。
技术实现思路
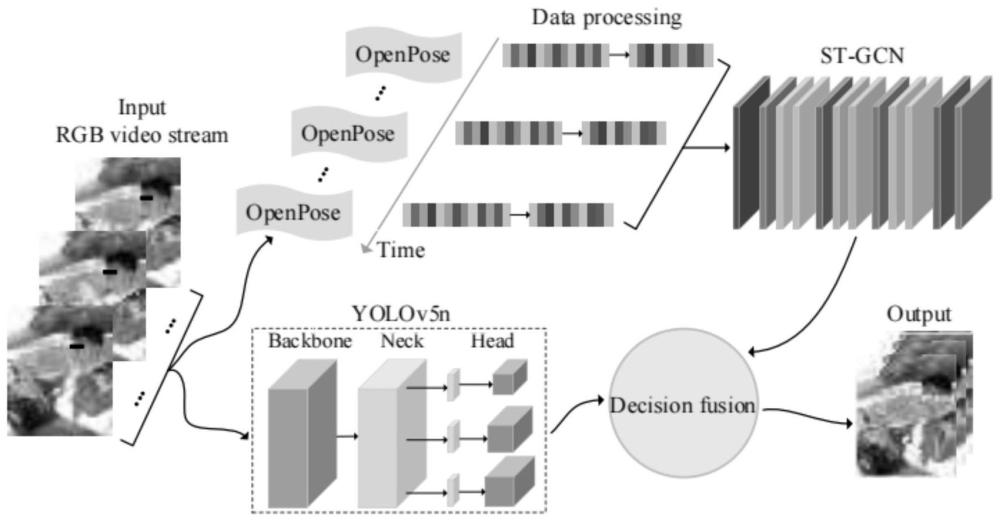
1、针对上述吸烟动作特征都是基于人为主观构建,不能很好的表征整个吸烟动作状态,导致模型的泛化能力不强的技术问题,本发明提供了一种基于st-gcn和yolov5n的驾驶员吸烟检测算法,将处理后的关键点以拓扑图形式按帧输入基于深度学习的行为识别网络st-gcn中,完成基于骨架的吸烟动作识别,结合yolov5n算法检测图像中的烟支目标做进一步判别,最后根据两个网络的输出进行加权融合,综合考虑驾驶员是否存在吸烟行为。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种基于st-gcn和yolov5n的驾驶员吸烟检测算法,包括下列步骤:
4、s1、人体骨骼关键点检测:通过检测出人体主要关节,识别并获取关键点在图像中的坐标数据,以此来对人体的动作行为进行描述;
5、s2、关键点数据优化:误检关键点处理、无关关键点处理以及缺失关键点处理;
6、s3、将同一个人的人体关键点按照特定的空间关系连接起来,形成人体骨骼图,将同一个人的人体骨骼图按照时间关系把对应关键点连接起来,形成一个空间边和时间边都表达空间关系的时空骨架图;
7、s4、基于预训练st-gcn进行时空特征提取;
8、s5、引入yolov5n网络来检测烟支目标对象;
9、s6、通过注意力机制模块为每个通道的特征映射分配不同的权重;
10、s7、通过解耦头decoupled head分离目标分类和定位;
11、s8、据吸烟动作识别网络和烟支目标检测网络的检测结果,利用权重融合策略,设计联合置信度计算公式,对驾驶员吸烟行为做最终判别。
12、所述s1中人体骨骼关键点检测的方法为:采用openpose模型,模型整体网络架构由两分支、多阶段结构的vgg为骨架;第一分支用于预测置信图,每个置信图表示人体骨架图的特定部件;第二分支预测部分亲和域,表示部件之间的关联程度;同时,细化每个分支的预测,采用多级级联连续重复在每个阶段设置损失函数,优化预测结果。
13、所述s2中误检关键点处理的方法为:每帧中人体骨骼信息pose是按照置信度排序的,由于视频的焦点在驾驶员身上,对于整张输入图像驾驶员的骨架最为明显,置信度也最高,因此只保留结果文件中每帧的第一个pose信息;
14、所述s2中无关关键点处理的方法为:针对驾驶员吸烟行为检测来说,吸烟动作主要通过手臂和头部相关的关节点来体现,行为运动主要集中在驾驶员上半身,将无需处理的关键点删除以避免无关数据的干扰。
15、所述s2中缺失关键点处理的方法为:
16、针对现有的关键点,将其分为静态关节点和动态关节点;
17、静态关节点即位置几乎保持不变的关节点,取所有帧中未遗漏的该关节点坐标数据的平均值来替换所有缺失的关节点坐标:
18、
19、其中:x和y表示关节点的横纵坐标值,j表示某个静态关节点,m表示未丢失j关节点的视频帧,m表示未丢失j关节点的视频帧总数;
20、对于动态关节点即频繁变化的关节点,对于单帧的数据缺失,利用缺失帧的前后1帧数据的平均值来表示:
21、
22、其中:j表示某个动态关节点,i表示第j个关节点的缺失帧,和为第i帧中第j个关节点的横纵坐标值;对于连续丢失n帧的数据缺失补充方式如下,利用丢失前一帧的数据加上连续丢失n帧后数据的平均值代替;
23、
24、
25、如果吸烟动作序列首帧和末帧关节点数据丢失,则取所有未丢失的关节点坐标数据帧的平均值补充到该帧;
26、通过关键点数据预处理得到的数据格式为:每段视频经过openpose输出为一个json文件,其中包含所有视频帧索引frame_index,每个帧索引中仅包含置信度最高的单人骨骼数据pose和置信度score,其中除无关关键点外其余均为实数。
27、所述s3中构建时空骨架图的方法为:以每k帧为一组形成时空骨架图,首先对获得的人体骨骼图进行层次构建,建立一个由人体关节点构成的无向时空图g=(v,e);
28、关节点集合定义:设定一个包含18个关节点的节点集合v={vki∣k=1,...,k,i=1,...,18}作为st-gcn行为识别网络的输入,其中对于每个关节点的特征向量f(vki),都由关节点i在k帧上的坐标向量和置信度构成;
29、空间边和时间边定义:实际上时空骨架图的边有两个子集构成。其中空间边根据人体结构的连通性构建,表示为es={vkivkj∣(i,j)∈h},h是自然连接的人体关节点的集合;时间边利用连续两帧之间相同关节点的变换构建,表示为ef={vkiv(k+1)i},对于每个关节点的ef中对应的所有边都将代表轨迹。
30、所述s4中基于预训练st-gcn进行时空特征提取的方法为:st-gcn网络首先对输入的时空骨架图进行bn批处理,进一步规范化输入数据,处理后的数据会经过9个st-gcn单元,网络按照每3个单元为一组,每组输出通道数分别为64、128、256;然后对输出的特征向量进行全局平均池化处理,其目的是将不同特征图转换为相同大小;最后通过softmax分类器对结果进行分类;其中每个st-gcn基本单元都由一个空间图卷积子模块gcn和一个时间图卷积子模块tcn两部分构成;在每个卷积层后添加一个bn层和relu激活函数层;在每个子模块结束后还要进行0.5丢失率的dropout操作;为了使训练更稳定对每个单元均采用了残差结构;
31、在kinetics-skeleton大规模人类动作数据集上训练st-gcn模型,意在使用自建吸烟动作数据集将迁移学习应用于驾驶员吸烟检测领域;首先从头训练st-gcn网络,使得模型可以学习到一般人类的运动特征;接着使用自建吸烟动作数据集进行微调,选择冻结预训练模型的网络前4层,保留底层特征提取通用低级特征;使得权重再反向传播过程中保持不变,以便神经网络可以学习kinetics-skeleton数据集和自制的吸烟动作数据集两个任务的共享特征,最后修改输出层维度为新的类别以获取最终模型。
32、所述s5中引入yolov5n网络来检测烟支目标对象的方法为:yolov5n网络结构由input、backbone、neck和head四部分组成,input延续了yolov4中的mosaic数据增强,以自适应锚帧和图像缩放的形式对输入图像进行随机裁剪和排列;backbone部分作为骨干网络,由卷积模块cbs、空间金字塔池化模块和csp模块,它的作用是结合不同层次的信息,通过增加相当的深度来提高准确率;neck部分位于backbone和head的中间位置,使用了自顶向下和自底向上的特征金字塔结构fpn+pan并进行多尺度融合;head部分主要包括边界框的损失计算函数clou_loss和非极大值抑制nms;
33、使用三维无参注意力机制simam对空间位置特征和通道信息进行全面评估,关注重点神经元,改善网络特征提取能力,替换yolov5n的head部分为decoupledhead,通过分离目标位置与类别信息方式,进一步提高模型准确率和收敛速度。
34、所述s6中通过注意力机制模块为每个通道的特征映射分配不同的权重的方法为:三维无参注意力机制模块simam通过能量函数为每个神经元分配一个唯一的权重,评估每个神经元的重要性,能量函数定义为:
35、
36、
37、其中:λ为常数,xi为输入特征,i为空间维度上的索引,m=h×w为该通道上的神经元数量,和表示均值和方差;
38、由上式可知,能量函数值越低,神经元t与周围神经元的区别越大,对视觉处理的重要性也就越大;因此,每个神经元的重要性可由得到,simam注意力机制模块在不增加网络参数的前提下,能有效地增强卷积神经网络的表征能力;
39、将simam注意力机制模块集成到backbone和neck部分,使simam在具有全局视野的同时,进一步融合不同尺寸的特征图。
40、所述s7中通过解耦头decoupled head分离目标分类和定位的方法为:decoupledhead对于输入特征层,为了降低参数量,首先通过1×1卷积降维,然后增加两个并行分支分离目标分类、目标定位和置信度任务,每个通道均采用两个3×3卷积以降低解耦头的复杂度,提高模型收敛速度;yolov5n融入解耦头后得到三个输出分支:cls_output对目标框的类别预测分数;reg_output对目标框坐标信息(x,y,w,h)进行预测;obj_output用于判断目标框为前景或背景,最后融合三个输出得到最终检测结果。
41、所述s8中权重融合策略的方法为:获取视频图像数据源,设定模型网络权重、置信度阈值等参数进行逐帧检测;输入图像分别经过st-gcn吸烟动作识别网络和yolov5n烟支目标检测网络,每帧图像得到两个不同的置信度输出,其中st-gcn从包含该帧骨架时空图的前10帧计算输出;将两个网络的输出作为联合置信度公式输入,最终输出联合置信度,公式为:
42、o=-0.2cos(π*x)-0.3cos(π*y)+0.5
43、其中,当程序检测到的某个视频帧时,st-gcn网络吸烟类别置信度输出记为x,置信度权重为a,yolov5n网络输出的置信度记为y,置信度权重为b;自变量x和y和因变量o均为取值范围[0,1]内的实数,最终设置权重a=0.2,b=0.3,联合置信度还满足以下性质:
44、归一化:当行为识别网络的置信度x输出为0.5,且目标检测网络的置信度y输出也为0.5时,联合置信度o也是0.5;当x和y为0时o为0;当x和y为1时o为1,满足置信度归一化的要求;
45、单调性:随着自变量x和y在区间上增加,因变量o也随之增加,反之也会随之减小,符合吸烟行为检测实际情况要求;
46、非线性:当x和y的值从1开始减小时,o的减小速率由慢到快再到慢。即当两种独立识别模式的置信度极高或极低时,对应的联合置信度接近饱和,变化率趋于0;当两种独立识别模式的置信度约为一半时,在不饱和情况下,对应的联合置信度变化迅速,满足预测模型要求。
47、本发明与现有技术相比,具有的有益效果是:
48、本发明不仅依赖于图像空间纹理特征,还能有效提取驾驶员吸烟动作序列中的时空特征。本发明通过结合人体姿态估计算法openpose和深度学习行为识别网络st-gcn,实现了基于骨架的吸烟动作识别。同时,本发明利用改进的yolov5n算法检测图像中的烟支目标做进一步判别,最终根据两个网络的输出进行加权融合,得到最终驾驶员吸烟概率。
- 还没有人留言评论。精彩留言会获得点赞!