一种面向垂直领域的实体关系联合抽取方法和系统与流程
本发明涉及实体关系抽取,特别是涉及一种面向垂直领域的实体关系联合抽取方法和系统。
背景技术:
1、近年来,大数据技术发展迅速,数据呈现出规模庞大、来源众多、类型复杂等特征。如何将庞杂的数据进行快速提炼,使其知识化、结构化构建知识图谱,成为各行业向信息化、智能化发展的关键因素。但是在一些数据量小,数据类型复杂的垂直领域中,如果能构建出该领域的知识图谱,对该领域从业者利用知识图谱进行推荐、数据分析以及帮助外界快速了解该领域知识都有极大帮助。
2、实体关系抽取是将数据结构化变成知识的方法,主要用于从非结构化文本数据中识别实体对象及实体间语义关系,将非结构化的文本数据转化为结构化的知识。一般实体关系抽取任务采用的是流水线模式,用训练好的一个模型去识别非结构化文本中的实体对象,接着用另一个模型抽取实体间的语义关系。但是流水线模式的实体关系抽取存在误差累积的问题,实体识别时产生的误差会继而影响关系抽取的效果。同时,流水线模式由于分开处理的结构,忽略了实体和关系间存在的内在联系。
3、除此之外,通用领域上的实体关系抽取模型应用于垂直领域时,会存在一些问题。例如:在某些垂直领域进行实体关系抽取时,其非结构化文本数据存在专业名词较多、各名词之间关系复杂,但实体出现频次低、总体训练数据量不足,这会导致实体关系抽取任务出现出文本结构特征表示不足,缺乏语法结构等信息,导致最终抽取效果不佳。
4、鉴于此,克服该现有技术所存在的缺陷是本技术领域亟待解决的问题。
技术实现思路
1、本发明要解决的技术问题是:在垂直领域中如何将实体抽取步骤与关系抽取步骤相结合。
2、本发明采用如下技术方案:
3、第一方面,提供了一种面向垂直领域的实体关系联合抽取方法,包括:
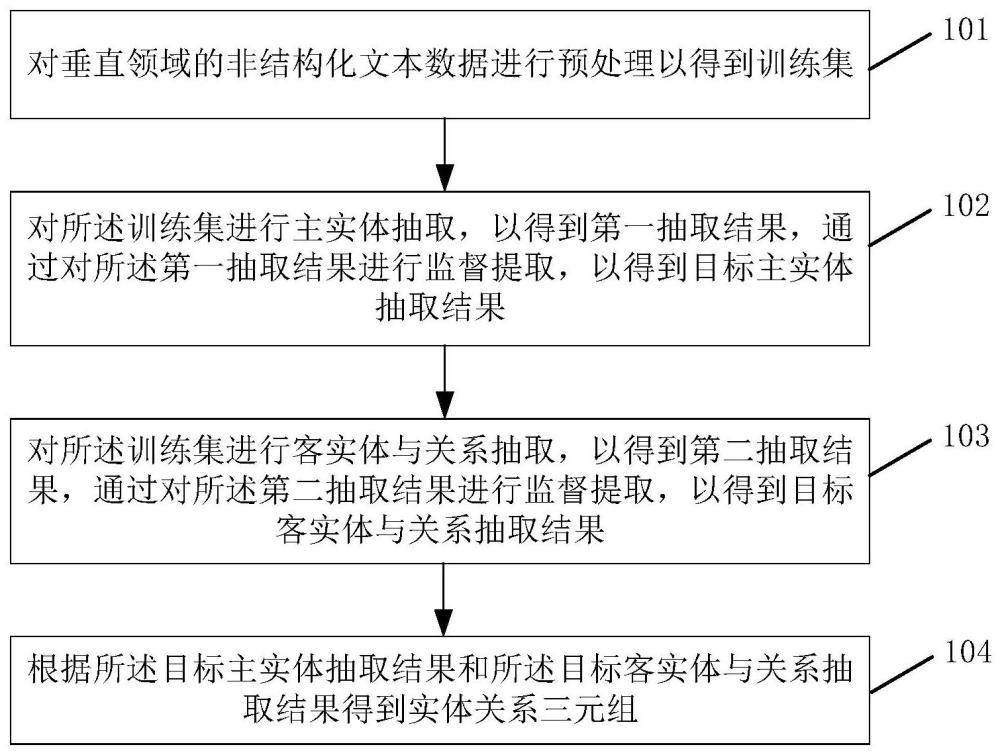
4、对垂直领域的非结构化文本数据进行预处理以得到训练集;
5、对所述训练集进行主实体抽取,以得到第一抽取结果,通过对所述第一抽取结果进行监督提取,以得到目标主实体抽取结果;
6、对所述训练集进行客实体与关系抽取,以得到第二抽取结果,通过对所述第二抽取结果进行监督提取,以得到目标客实体与关系抽取结果;
7、根据所述目标主实体抽取结果和所述目标客实体与关系抽取结果得到实体关系三元组。
8、优选的,所述对所述训练集进行主实体抽取,以得到第一抽取结果,通过对所述第一抽取结果进行监督提取,以得到目标主实体抽取结果包括:
9、根据第一模型和第二模型对所述训练集的主实体抽取,以得到第一主实体集合;
10、根据预设规则对所述训练集的主实体进行抽取,以得到第二主实体集合;
11、通过对所述第一主实体集合和所述第二主实体集合进行监督提取,以得到所述目标主实体抽取结果。
12、优选的,所述根据第一模型和第二模型对所述训练集的主实体抽取,以得到第一主实体集合包括:
13、将所述训练集中每个token进行向量化,包括字和词向量化、文本分句向量化以及每个token的位置向量化,以得到token序列x;
14、构建第一模型,并将所述token序列x输入所述第一模型;
15、在所述第一模型中通过双向transformer对所述token序列x进行特征提取,以得到具有字、词之间的依赖信息的新token序列xroberta;
16、构建第二模型,并将所述新token序列xroberta输入所述第二模型,以得到实体标签序列xcrf,在所述实体标签序列xcrf中筛选出实体作为主实体,所有主实体所在的句子构成所述第一主实体集合。
17、优选的,所述根据预设规则对所述训练集的主实体进行抽取,以得到第二主实体集合包括:
18、结合当前垂直领域知识编写正则表达式库,所述正则表达式库中的每条规则知识包括实体类型和抽取规则;
19、通过所述正则表达式库对所述训练集进行匹配,抽取所述训练集中符合正则表达式的实体,所有符合抽取规则的主实体所在的句子组成所述第二主实体集合。
20、优选的,所述通过对所述第一主实体集合和所述第二主实体集合进行监督提取,以得到所述目标主实体抽取结果包括:
21、将存在于所述第二主实体集合中而不存在于所述第一主实体集合中的句子加入所述第一主实体集合,得到第三主实体集合;
22、将所述第三主实体集合与所述正则表达式库中的抽取规则进行匹配,将符合抽取规则的实体所在的句子组成所述目标主实体抽取结果,当出现不符合抽取规则的实体时,将该实体所在的句子加入到监督删除库中,并根据预设判定条件重新判断。
23、优选的,所述对所述训练集进行客实体与关系抽取,以得到第二抽取结果,通过对所述第二抽取结果进行监督提取,以得到目标客实体与关系抽取结果包括:
24、根据语言模型结果与增强实体影响对所述训练集的客实体与关系联合抽取,以得到第一客实体与关系集合;
25、根据预设规则对所述训练集的客实体与关系进行抽取,以得到第二客实体与关系集合;
26、通过对所述第一客实体与关系集合和所述第二客实体与关系集合进行监督提取,以得到所述目标客实体与关系抽取结果。
27、优选的,所述语言模型结果包括新token序列xroberta,所述根据语言模型结果与增强实体影响对所述训练集的客实体与关系联合抽取,以得到第一客实体与关系集合包括:
28、从所述新token序列xroberta切割出单独的句子的token序列xsentence;
29、对所述token序列xsentence中的实体的标签进行更改,得到新序列xnew;
30、将所述新序列xnew导入增强实体影响模块,增强实体影响模块的工作流程如下:
31、增强实体影响模块接收新序列xnew;
32、对所述新序列xnew中所有的主实体subjecti中所有token向量做求和平均得到实体影响系数ai;
33、将实体影响系数ai加到新序列xnew中每一个token的向量上,生成subjecti的增强实体影响序列xsubjecti;
34、通过对所述增强实体影响序列xsubjecti进行双向编码,以获得上下文信息;
35、通过self-attention自注意力机制模型对上下文信息进行处理,得到特征向量序列xendi;
36、使用softmax函数对所述特征向量序列xendi中每一个非主实体的token进行二分类处理,以预测在句子中是否是主实体n种关系中任意关系的客实体的起始点或终止点;
37、如果该token属于起始点或终止点则该token标记为1,不是则标记为0,以此构造实体关系三元组的句子,连同三元组中的主实体、关系、客实体一同储存进所述第一客实体与关系集合中。
38、优选的,所述根据预设规则对所述训练集的客实体与关系进行抽取,以得到第二客实体与关系集合包括:
39、基于垂直领域的抽取需求,利用主实体和客实体的类型、主实体和客实体间的字符距离约束、表达不同语义关系的关键性字和词设计正则表达式库;
40、通过所述正则表达式库对所述训练集进行匹配,抽取所述训练集中符合正则表达式的实体,所有符合抽取规则的客实体与关系所在的句子组成所述第二客实体与关系集合。
41、优选的,所述通过对所述第一客实体与关系集合和所述第二客实体与关系集合进行监督提取,以得到所述目标客实体与关系抽取结果包括:
42、将存在于所述第二客实体与关系集合中而不存在于所述第一客实体与关系集合中的句子加入所述第一客实体与关系集合中,得到第三客实体与关系集合;
43、将所述第三客实体与关系集合与所述正则表达式库中的抽取规则进行匹配,将符合抽取规则的实体所在的句子组成所述目标客实体与关系抽取结果,当出现不符合抽取规则的实体时,将该实体所在的句子加入到监督删除库中,并根据预设判定条件重新判断。
44、第二方面,提供了一种面向垂直领域的实体关系联合抽取系统,所述系统包括预处理模块、主实体抽取模块、客实体与关系抽取模块以及获得模块;
45、所述预处理模块用于对垂直领域的非结构化文本数据进行预处理以得到训练集;
46、所述主实体抽取模块用于对所述训练集进行主实体抽取,以得到第一抽取结果,通过对所述第一抽取结果进行监督提取,以得到目标主实体抽取结果;
47、所述客实体与关系抽取模块用于对所述训练集进行客实体与关系抽取,以得到第二抽取结果,通过对所述第二抽取结果进行监督提取,以得到目标客实体与关系抽取结果;
48、所述获得模块用于根据所述目标主实体抽取结果和所述目标客实体与关系抽取结果得到实体关系三元组。
49、与现有技术相比,本发明的有益效果在于:
50、本发明对垂直领域的非结构化文本数据进行预处理以得到训练集,并对所述训练集进行主实体抽取,以得到第一抽取结果,通过对所述第一抽取结果进行监督提取,以得到目标主实体抽取结果,以及对所述训练集进行客实体与关系抽取,以得到第二抽取结果,通过对所述第二抽取结果进行监督提取,以得到目标客实体与关系抽取结果,根据所述目标主实体抽取结果和所述目标客实体与关系抽取结果得到实体关系三元组。本发明将实体抽取步骤与关系抽取步骤相结合,并通过强领域性规则与监督提取的方式更高效地完成在垂直领域的实体关系抽取任务。
- 还没有人留言评论。精彩留言会获得点赞!