一种数据处理方法、装置、电子设备及存储介质与流程
本公开涉及计算机,尤其涉及一种数据处理方法、装置、电子设备及存储介质。
背景技术:
1、随着人工智能(artificial intelligence,ai)技术的不断发展,各类ai模型在不同领域得到了广泛应用,同时也对硬件的计算架构提出了新要求。卷积、全连接和矩阵乘运算是各类深度学习网络中最基本、计算量最大的算子,因此基于深度学习网络进行数据处理的电子设备其数据处理效率与这些算子的运算效率息息相关。
2、目前,电子设备在基于深度学习网络进行数据处理时会基于img2col(image tocolumn)进行通用矩阵乘法(general matrix multiplication,gemm)运算,然而相关技术中电子设备基于深度学习网络的数据处理效率较低,无法满足相关业务的业务需求。
技术实现思路
1、本公开提供一种数据处理方法、装置及系统,以至少解决相关技术中电子设备基于深度学习网络的数据处理效率较低的问题。本公开的技术方案如下:
2、根据本公开实施例的第一方面,提供一种数据处理方法,包括:
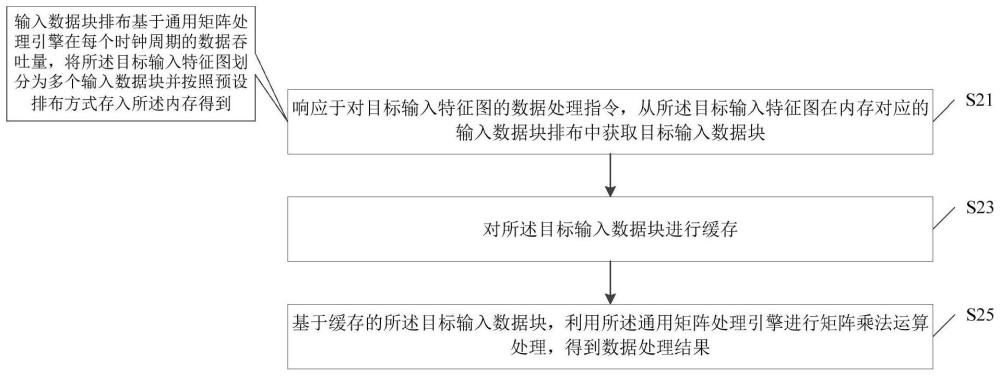
3、响应于对目标输入特征图的数据处理指令,从所述目标输入特征图在内存中对应的输入数据块排布中获取目标输入数据块;所述输入数据块排布基于通用矩阵处理引擎在每个时钟周期的数据吞吐量,将所述目标输入特征图划分为多个输入数据块并按照预设排布方式存入所述内存得到;
4、对所述目标输入数据块进行缓存;
5、基于缓存的所述目标输入数据块,利用所述通用矩阵处理引擎进行矩阵乘法运算处理,得到数据处理结果。
6、在一示例性的实施方式中,所述基于缓存的所述目标输入数据块,利用所述通用矩阵处理引擎进行矩阵乘法运算处理,得到数据处理结果包括:
7、根据当前卷积层的卷积参数,对缓存的所述目标输入数据块进行矩阵转换;
8、在确定完成对所述目标输入数据块的矩阵转换时,将经所述矩阵转换得到的特征块矩阵输出到通用矩阵处理引擎中,以使得所述通用矩阵处理引擎进行矩阵乘法运算处理,得到数据处理结果。
9、在一示例性的实施方式中,所述响应于对于目标输入特征图的数据处理指令,从所述目标输入特征图在内存中对应的输入数据块排布中获取目标输入数据块,包括:
10、响应于对所述目标输入特征图的数据处理指令,由空闲状态进入等待状态;
11、在所述等待状态下向所述内存发送读数据请求,由所述等待状态进入准备状态;所述读数据请求用于请求获取所述输入数据块排布中的输入数据块;
12、在接收到所述内存基于所述读数据请求返回的目标输入数据块时,进入矩阵转换工作状态;所述目标输入数据块包括所述输入数据块排布在行方向上的一组输入数据块。
13、在一示例性的实施方式中,所述根据当前卷积层的卷积参数,对缓存的所述目标输入数据块进行矩阵转换,包括:
14、根据所述目标输入特征图的特征图尺寸参数、所述卷积参数和所述输入数据块的块大小,确定地址偏移信息;所述特征图尺寸参数包括特征图宽度、特征图高度和特征图通道数;
15、根据所述地址偏移信息从缓存的所述目标输入数据块中获取当前的待处理输入数据块;
16、根据所述卷积参数对所述当前的待处理输入数据块进行矩阵展开,得到展开后的块矩阵,对所述展开后的块矩阵进行转置,得到所述特征块矩阵;
17、在所述当前的待处理输入数据块非所述目标输入数据块中的最后一个输入数据块的情况下,执行所述根据所述地址偏移信息从缓存的所述目标输入数据块中获取当前的待处理输入数据块以及所述矩阵展开的步骤,直至所述当前的待处理输入数据块为所述目标输入数据块中的最后一个输入数据块,确定完成对所述目标输入数据块的矩阵转换,并由所述矩阵转换工作状态进入完成状态。
18、在一示例性的实施方式中,所述方法还包括:
19、若所述输入数据块排布在列方向上还存在未经矩阵转换的输入数据块,则由所述完成状态再次进入所述等待状态;
20、执行所述在所述等待状态下向所述内存发送读数据请求的步骤,直至所述输入数据块排布在列方向上不存在未经矩阵转换的输入数据块,由所述完成状态进入所述空闲状态。
21、在一示例性的实施方式中,所述根据所述卷积参数对所述当前的待处理输入数据块进行矩阵展开,包括:
22、根据所述卷积参数中滑窗的移动步长,确定相邻滑窗在所述待处理输入数据块中对应的重叠数据;
23、按照通道维度暂存所述重叠数据,作为待复用数据;
24、从滑窗在所述待处理输入数据块所对应的数据中,获取待转换数据,所述待转换数据不包括所述重叠数据;
25、基于所述待复用数据和所述待转换数据进行矩阵展开。
26、在一示例性的实施方式中,在响应于对目标输入特征图的数据处理指令,从所述目标输入特征图在内存中对应的输入数据块排布中获取目标输入数据块之前,所述方法还包括:
27、将所述目标输入特征图在所述内存中转换为输入数据;所述输入数据的高度为所述目标输入特征图的长乘以宽,所述输入数据的宽度为所述目标输入特征图的通道数;
28、获取所述通用矩阵处理引擎在每个时钟周期的数据吞吐量;
29、基于所述通用矩阵处理引擎在每个时钟周期的数据吞吐量,将所述输入数据划分为多个输入数据块,每个所述输入数据块的数据量为所述数据吞吐量,每个所述输入数据块的内部数据为z型排布,所述输入数据块之间在通道方向上连续。
30、在一示例性的实施方式中,所述基于所述通用矩阵处理引擎在每个时钟周期的数据吞吐量,将所述输入数据划分为多个输入数据块,包括:
31、在所述输入数据的尺寸非所述数据吞吐量所指示尺寸的整数倍的情况下,对所述输入数据进行数据补齐处理,得到补齐后输入数据;所述补齐后输入数据的尺寸为所述数据吞吐量所指示尺寸的整数倍;
32、基于所述通用矩阵处理引擎在每个时钟周期的数据吞吐量,将所述补齐后输入数据划分为所述多个输入数据块。
33、根据本公开实施例的第二方面,提供一种数据处理装置,包括:
34、输入数据块获取单元,被配置为执行响应于对目标输入特征图的数据处理指令,从所述目标输入特征图在内存中对应的输入数据块排布中获取目标输入数据块;所述输入数据块排布基于通用矩阵处理引擎在每个时钟周期的数据吞吐量,将所述目标输入特征图划分为多个输入数据块并按照预设排布方式存入所述内存得到;
35、输入数据块缓存单元,被配置为执行对所述目标输入数据块进行缓存;
36、数据处理模块,被配置为执行基于缓存的所述目标输入数据块,利用所述通用矩阵处理引擎进行矩阵乘法运算处理,得到数据处理结果。
37、在一示例性的实施方式中,所述数据处理模块包括:
38、矩阵转换单元,被配置为执行根据当前卷积层的卷积参数,对缓存的所述目标输入数据块进行矩阵转换;
39、特征块矩阵输出单元,被配置为执行在确定完成对所述目标输入数据块的矩阵转换时,将经所述矩阵转换得到的特征块矩阵输出到通用矩阵处理引擎中,以使得所述通用矩阵处理引擎进行矩阵乘法计算。
40、在一示例性的实施方式中,所述输入数据块获取单元包括:
41、第一状态转换单元,被配置为执行响应于对所述目标输入特征图的数据处理指令,由空闲状态进入等待状态;
42、第二状态转换单元,被配置为执行在所述等待状态下向所述内存发送读数据请求,由所述等待状态进入准备状态;所述读数据请求用于请求获取所述输入数据块排布中的输入数据块;
43、第三状态转换单元,被配置为执行在接收到所述内存基于所述读数据请求返回的目标输入数据块时,进入矩阵转换工作状态;所述目标输入数据块包括所述输入数据块排布在行方向上的一组输入数据块。
44、在一示例性的实施方式中,所述矩阵转换单元包括:
45、地址偏移确定单元,被配置为执行根据所述目标输入特征图的特征图尺寸参数、所述卷积参数和所述输入数据块的块大小,确定地址偏移信息;所述特征图尺寸参数包括特征图宽度、特征图高度和特征图通道数;
46、缓存获取单元,被配置为执行根据所述地址偏移信息从缓存的所述目标输入数据块中,获取当前的待处理输入数据块;
47、矩阵展开单元,被配置为执行根据所述卷积参数对所述当前的待处理输入数据块进行矩阵展开,得到展开后的块矩阵,对所述展开后的块矩阵进行转置,得到所述特征块矩阵;
48、第四状态转换单元,被配置为执行在所述当前的待处理输入数据块非所述目标输入数据块中的最后一个输入数据块的情况下,执行所述根据所述地址偏移信息从缓存的所述目标输入数据块中获取当前的待处理输入数据块以及所述矩阵展开的步骤,直至所述当前的待处理输入数据块为所述目标输入数据块中的最后一个输入数据块,确定完成对所述目标输入数据块的矩阵转换,并由所述矩阵转换工作状态进入完成状态。
49、在一示例性的实施方式中,所述矩阵转换单元还包括:
50、第五状态转换单元,被配置为执行若所述输入数据块排布在列方向上还存在未经矩阵转换的输入数据块,则由所述完成状态再次进入所述等待状态;
51、第六状态转换单元,被配置为执行所述在所述等待状态下向所述内存发送读数据请求的步骤,直至所述输入数据块排布在列方向上不存在未经矩阵转换的输入数据块,由所述完成状态进入所述空闲状态。
52、在一示例性的实施方式中,所述矩阵展开单元包括:
53、重叠数据确定单元,被配置为执行根据所述卷积参数中滑窗的移动步长,确定相邻滑窗在所述待处理输入数据块中对应的重叠数据;
54、重叠数据暂存单元,被配置为执行按照通道维度暂存所述重叠数据,作为待复用数据;
55、待转换数据获取单元,被配置为执行从滑窗在所述待处理输入数据块所对应的数据中,获取待转换数据,所述待转换数据不包括所述重叠数据;
56、矩阵展开子单元,被配置为执行基于所述待复用数据和所述待转换数据进行矩阵展开。
57、在一示例性的实施方式中,所述装置还包括:
58、输入转换单元,被配置为执行将所述目标输入特征图在所述内存中转换为输入数据;所述输入数据的高度为所述目标输入特征图的长乘以宽,所述输入数据的宽度为所述目标输入特征图的通道数;
59、吞吐量获取单元,被配置为执行获取所述通用矩阵处理引擎在每个时钟周期的数据吞吐量;
60、数据块划分单元,被配置为执行基于所述通用矩阵处理引擎在每个时钟周期的数据吞吐量,将所述输入数据划分为多个输入数据块,每个所述输入数据块的数据量为所述数据吞吐量,每个所述输入数据块的内部数据为z型排布,所述输入数据块之间在通道方向上连续。
61、在一示例性的实施方式中,所述数据块划分单元包括:
62、数据补齐单元,被配置为执行在所述输入数据的尺寸非所述数据吞吐量所指示尺寸的整数倍的情况下,对所述输入数据进行数据补齐处理,得到补齐后输入数据;所述补齐后输入数据的尺寸为所述数据吞吐量所指示尺寸的整数倍;
63、数据块划分子单元,被配置为执行基于所述通用矩阵处理引擎在每个时钟周期的数据吞吐量,将所述补齐后输入数据划分为所述多个输入数据块。
64、根据本公开实施例的第三方面,提供一种电子设备,包括:
65、处理器;
66、用于存储所述处理器可执行指令的存储器;
67、其中,所述处理器被配置为执行所述指令,以实现上述第一方面的数据处理方法。
68、根据本公开实施例的第四方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行上述第一方面的数据处理方法。
69、根据本公开实施例的第五方面,提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现上述第一方面的数据处理方法。
70、本公开的实施例提供的技术方案至少带来以下有益效果:
71、通过响应于对目标输入特征图的数据处理指令,从该目标输入特征图在内存对应的输入数据排布中获取目标输入数据块,该输入数据排布基于通用矩阵处理引擎在每个时钟周期的数据吞吐量,将目标输入特征图划分为多个输入数据并按照预设排布方式存入内存得到,进而对目标输入数据块进行缓存,并基于缓存的目标输入数据块,利用通用矩阵处理引擎进行矩阵乘法运算处理得到数据处理结果,从而实现了规则内存访问、提升了数据访问效率,大大提高了基于img2col的数据处理效率,进而提高了电子设备基于深度学习网络的数据处理效率。
72、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!