构建数据库、评测大模型的方法及装置与流程
本说明书一个或多个实施例涉及大模型评测,尤其涉及一种构建数据库的方法及装置、一种基于构建好的数据库对大模型进行评测的方法及装置、一种计算机可读存储介质,以及一种计算设备。
背景技术:
1、在人工智能领域,大模型一般是指具有大量参数(如上百亿或上千亿量级参数)和复杂结构的机器学习模型,在利用海量数据对其进行训练后,能够用于完成多种复杂任务,例如,将自然语言(natural language)转换成结构化标准查询语言(structured querylanguage)的生成式任务,简称nl2sql或text-to-sql类任务。nl2sql是数据库查询的一种新兴方式,它可以帮助非技术人员轻松地查询数据库,同时也可以提高开发人员的工作效率。
2、大模型的训练难度较高,对数据、算法和算力等都提出了较高要求,当投入了高昂的人力、财力、物力训练出模型后,如何对大模型的质量进行评测,是大模型领域面临的问题。
3、然而,目前针对nl2sql任务的大模型评测方案,难以满足实际应用中的更高要求。
技术实现思路
1、本说明书实施例描述一种构建数据库的方法及装置,以及一种评测大模型的方法及装置,可以实现针对nl2sql任务的大模型自动化客观评测,满足实际应用中的更高要求,例如,提高评测效率,提升评测结果的准确度和可用性等。其中客观评测是指评价者不考虑自己的主观看法或感受,而是采用一套固定的标准和方法,通过实际数据的量化分析来评价和比较不同的事物。
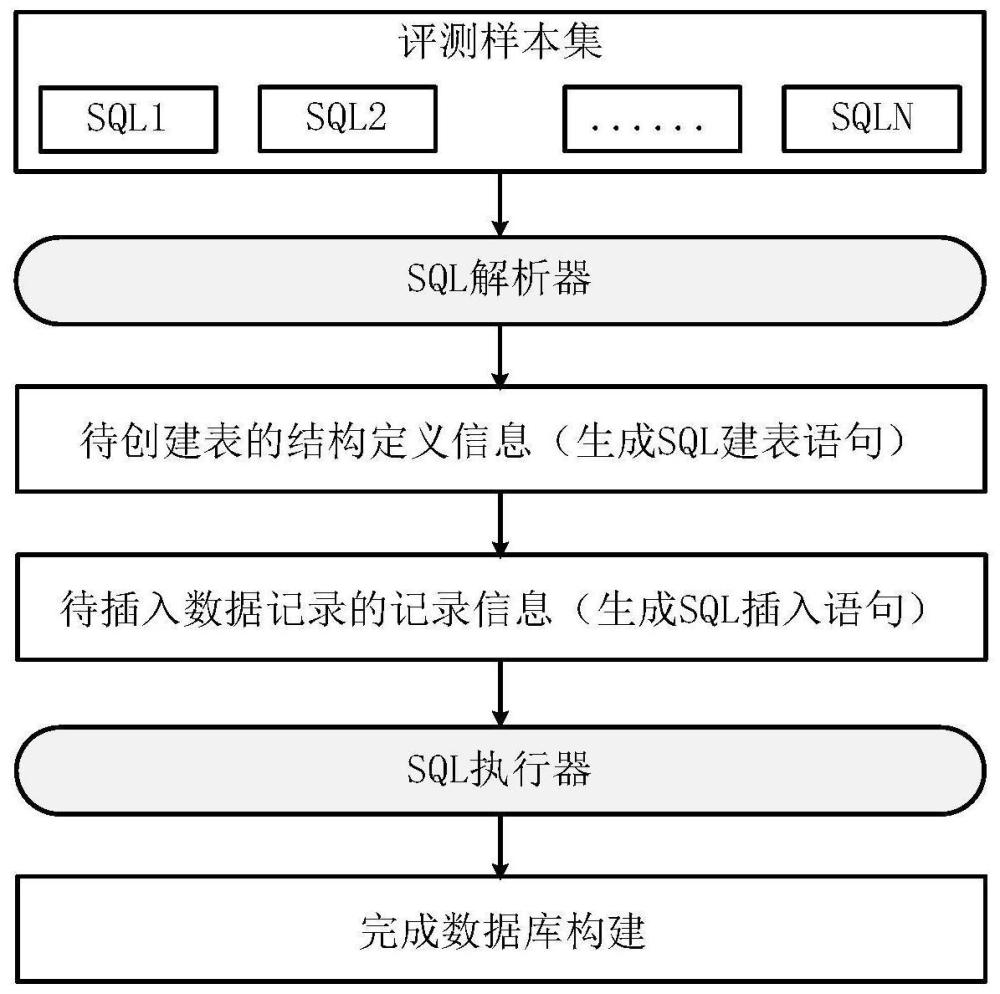
2、根据第一方面,提供一种构建数据库的方法,构建出的数据库用于评测大模型针对目标任务的执行性能,所述目标任务意图将自然语言查询文本转换成sql查询语句。所述方法包括:
3、获取评测样本集,其中各个评测样本包括自然语言查询文本和对应的推荐sql查询语句;针对所述评测样本集创建目标数据库;通过对所述评测样本集涉及的多个推荐sql查询语句进行语法解析,确定若干表结构的定义信息,以及其中各个表结构下待插入的数据记录的记录信息;通过执行基于所述定义信息生成的sql建表语句,在所述目标数据库中创建若干目标表,所述若干目标表对应具有所述若干表结构;通过执行基于所述记录信息生成的sql插入语句,在各个目标表中插入对应的数据记录。
4、在一个实施例中,获取评测样本集,包括:获取针对所述大模型的通用数据集;从所述通用数据集中筛选出与所述目标任务相匹配的样本,归入所述评测样本集。
5、在一个具体的实施例中,从所述通用数据集中筛选出与所述目标任务对应的样本,包括:针对所述通用数据集中的各个样本,利用预先训练好的意图识别模型处理其中包含的用户输入文本,得到意图预测结果,指示是否匹配所述目标任务的意图。
6、在一个实施例中,通过对所述评测样本集涉及的多个推荐sql查询语句进行语法解析,确定若干表结构的定义信息,以及其中各个表结构下待插入的数据记录的记录信息,包括:对所述多个推荐sql查询语句分别进行语法解析,对应得到多个sql抽象语法树;基于所述多个sql抽象语法树,确定所述定义信息和所述记录信息。
7、在一个具体的实施例中,基于所述多个sql抽象语法树,确定所述定义信息和所述记录信息,包括:基于所述多个sql抽象语法树,确定其中所有的表名,以及各个表名下的表字段和对应的字段类型,共同归入所述定义信息;基于所述多个sql抽象语法树,提取其中的sql关键字和表字段的字段值;根据所述sql关键字对应的语法规则和所述字段值,生成所述记录信息。
8、在一个实施例中,所述评测样本集的数量为多个,针对多个评测样本集分别构建有目标数据库。
9、进一步,在一个具体的实施例中,所述多个评测样本集中包括不同语种的评测样本集,和/或,不同sql复杂度的评测样本集。
10、根据第二方面,提供一种评测大模型的方法。该方法包括:
11、针对评测样本集中的各个评测样本,将其中的提示文本输入大模型,得到该评测样本对应的预测sql查询语句;所述提示文本中包括自然语言查询文本。基于针对所述评测样本集构建出的目标数据库,分别执行所述预测sql查询语句和对应的推荐sql查询语句,得到执行结果对;所述目标数据库采用权利要求1所述的方法而构建。基于所述各个评测样本对应的执行结果对,统计所述大模型针对所述评测样本集的执行正确率,归入所述大模型的评测结果。
12、在一个实施例中,在得到该评测样本对应的预测sql查询语句之后,所述方法还包括:分别对所述预测sql查询语句和推荐sql查询语句进行语法解析,得到解析结果对;基于所述各个评测样本对应的解析结果对,统计所述大模型针对所述评测样本集的语法正确率,归入所述大模型的评测结果。
13、在一个具体的实施例中,所述解析结果对包括对应多个解析项的多对解析值;其中,基于所述各个评测样本对应的解析结果对,统计所述大模型针对所述评测样本集的语法正确率,包括:根据针对所述多个解析项对应设定的多个匹配规则,确定所述多对解析值是否各自在对内都成功匹配;在都成功匹配的情况下,判定相对应评测样本的预测sql查询语句的语法正确。
14、进一步,在一个更具体的实施例中,所述多个匹配规则中包括针对第一解析项的第一匹配规则,所述第一匹配规则包括等效匹配子规则。
15、在一个例子中,所述第一解析项包括查询字段、关键字或函数名,所述等效匹配子规则包括字母的大小写等效。
16、在另一个例子中,所述第一解析项包括查询条件,所述等效匹配子规则包括查询条件中逻辑运算符的不同操作数在不同排列顺序下等效。
17、在一个实施例中,所述评测样本集的数量为多个,针对多个评测样本集分别构建有目标数据库,所述评测结果包括所述大模型针对所述多个评测样本集的多个评测子结果。
18、在一个具体的实施例中,所述多个评测样本集中包括不同语种的评测样本集,和/或,不同sql复杂度的评测样本集。
19、在一个实施例中,所述大模型的数量为多个,所述评测结果包括多个大模型各自针对同一评测样本集的评测子结果。
20、在一个实施例中,所述方法还包括:对所述评测结果进行可视化展示。
21、根据第三方面,提供一种构建数据库的装置,构建出的数据库用于评测大模型针对目标任务的执行性能,所述目标任务意图将自然语言查询文本转换成sql查询语句;所述装置包括:
22、样本集获取模块,配置为获取评测样本集,其中各个评测样本包括自然语言查询文本和对应的推荐sql查询语句。数据库创建模块,配置为针对所述评测样本集创建目标数据库。语法解析模块,配置为通过对所述评测样本集涉及的多个推荐sql查询语句进行语法解析,确定若干表结构的定义信息,以及其中各个表结构下待插入的数据记录的记录信息。建表模块,配置为通过执行基于所述定义信息生成的sql建表语句,在所述目标数据库中创建若干目标表,所述若干目标表对应具有所述若干表结构。记录插入模块,配置为通过执行基于所述记录信息生成的sql插入语句,在各个目标表中插入对应的数据记录。
23、根据第四方面,提供一种预测模块,配置为针对评测样本集中的各个评测样本,将其中的提示文本输入大模型,得到该评测样本对应的预测sql查询语句;所述提示文本中包括自然语言查询文本。执行模块,配置为基于针对所述评测样本集构建出的目标数据库,分别执行所述预测sql查询语句和对应的推荐sql查询语句,得到执行结果对;所述目标数据库由第三方面提供的装置构建;统计模块,配置为基于所述各个评测样本对应的执行结果对,统计所述大模型针对所述评测样本集的执行正确率,归入所述大模型的评测结果。
24、根据第五方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面或第二方面提供的方法。
25、根据第六方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,该处理器执行所述可执行代码时,实现第一方面或第二方面提供的方法。
26、综上,采用本说明书实施例披露的上述方法或装置,设计执行正确率和语法正确率作为评测指标,可以更加客观的评价text-to-sql的生成式任务。同时,通过全自动化评测流程,可以大幅提高评测效率。以wikisql中的8万多条查询数据为例,本方案可以把评测时间控制在小时级别(包括评测环境的构建、评测指标的执行),其中在评测环境构建构建好以后,评测指标的执行在分钟级别。
- 还没有人留言评论。精彩留言会获得点赞!