基于指数函数阈值动态调整的半监督学习语义分割方法
本发明涉及计算机视觉、语义分割,具体而言,涉及一种基于指数函数阈值动态调整的半监督学习语义分割方法。
背景技术:
1、语义分割是计算机视觉领域中的一项重要任务,可以应用于不用的领域。语义分割的目的是预测像素级的语义标签。但是未标记数据的未充分利用、标记数据的严重短缺以及获取像素级标签需要巨大劳动力而使得语义分割任务具有挑战性。而半监督学习(ssl)方法旨在使用有限数量的标记数据和大量未标记数据做出良好的预测,使得它非常适合训练语义分割模型。
2、随着半监督语义分割的发展,目前已有多种方法可以通过其利用丰富的未标记数据。一致性正则化和自训练方法通常被用于半监督语义分割,其中图像强增强或弱增强均可以被添加到训练过程中,如cutout和cutmix的等图像级强增强也可以有助于语义分割任务。此外,基于自训练方法的伪标签方法非常有效,但生成精确的伪标签并不容易。通常情况下伪标签的质量较低,如何选择高质量的可信伪标签变得具有挑战性。如采用基于图像级标签的grad-cam来增强伪标签的质量或者将高置信度和低置信度伪标签分开进行分阶段再训练,优先考虑高置信度样本以生成更好的伪标签。
3、更便利有效的方法是设置置信度分数来作为阈值标准进行伪标签的筛选,通常过程为:在语义分割的伪标签生成过程中,当图像像素对应的分类结果中的最大置信度大于阈值时,进行该像素的损失计算。阈值的设置方式可以有多种,比如使用固定阈值来生成伪标签、使用低熵值作为每个像素预测结果的过滤标准、或在训练过程中线性增加伪标签中像素的比例,并通过特定类别像素的比例和整体置信度分布来确定阈值。但上述阈值筛选方法没有考虑到在训练过程中,模型学习有先快后慢的趋势。dash是一种半监督图像分类方法,考虑了模型学习过程的模式,并结合独特的阈值筛选过程取得很好的结果,但这个阈值筛选方法是针对图像分类任务而设置的,若使用相同的阈值对所有图像进行过滤,语义分割中的类别不平衡问题更加明显,每类像素置信度区别较大。
技术实现思路
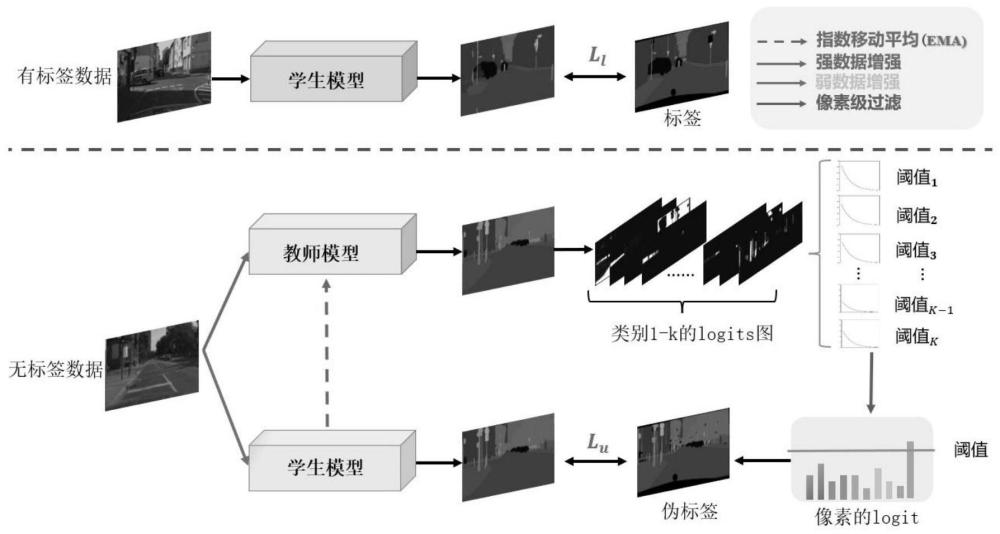
1、本发明解决的问题是如何降低减少各类别像素置信度差异以及模型预测能力随时间变化对伪标签生成的影响。
2、为解决上述问题,本发明提供一种基于指数函数阈值动态调整的半监督学习语义分割方法,包括:
3、步骤1:给定一组包含m个有标签数据集和一组包含n个无标签数据集其中,n>>m;并构建语义分割模型;
4、步骤2:采用交叉熵损失函数在利用有标签数据集对语义分割模型进行迭代训练,得到有监督损失ll;迭代训练的最后轮次中预测为第k个类别的像素的平均置信度作为第k类像素在半监督训练中生成伪标签的初始置信度阈值
5、步骤3:基于初始置信度阈值计算无监督训练中采用交叉熵损失函数训练的权值wk;
6、步骤4:将经过步骤2训练后的语义分割模型分为教师模型fteacher和学生模型fstudent;
7、步骤5:利用有标签数据集和无标签数据集对教师模型fteacher和学生模型fstudent进行半监督训练;包括:
8、a1.基于初始置信度阈值和当前迭代训练轮次cur_iter构建先快后慢下降形式的指数函数;
9、a2.判断迭代训练次数cur_iter是否小于等于迭代训练总数total_iter,若是,则进入a3;若否,则迭代训练完成,输出更新后的教师模型,并进入步骤6;
10、a3.根据指数函数求取当前迭代训练轮次cur_iter下迭代训练产生的各类伪标签的筛选阈值τk;
11、a4.将无标签数据集放入教师模型fteacher中训练产生伪标签,并根据筛选阈值τk对当前迭代训练产生的各类伪标签进行筛选过滤;
12、a5.采用有监督损失ll将有标签数据集放入学生模型fstudent进行训练,并通过将无标签数据集和经过a4筛选后的伪标签进行多标签学习训练,基于有监督损失ll和无监督损失lu训练结果对训练后的学生模型进出参数更新,生成更新后的学生模型;
13、a6.采用指数移动平均方法利用学生模型的参数更新教师模型;
14、a7.计算当前迭代训练轮次cur_iter下更新的教师模型在验证集上的评价指标值;
15、a8.判断当前迭代训练轮次cur_iter下教师模型的评价指标值是否大于迭代训练轮次cur_iter-1下教师模型的评价指标值,若是,则保留当前迭代训练次数cur_iter下教师模型的参数,cur_iter=cur_iter+1,并返回a2;若否,则保留迭代训练次数cur_iter-1下教师模型的参数,cur_iter=cur_iter+1,并返回a2;
16、步骤6:将输出的教师模型作为图像分割模型;基于所述图像分割模型执行图像分割操作,生成对应的图像分割结果。
17、本发明的有益效果:本发明通过构建先快后慢下降形式的指数函数计算动态阈值,基于半监督语义分割中标签类别之间的学习困难程度的差异,采用先快后慢的动态阈值筛选方法,在语义分割模型生成伪标签的过程中,分别处理不同类别图像中像素的阈值,将置信度不符合阈值的伪标签进行筛选,能够有效地减少错误伪标签的产生,增强伪标签的可信度;再加上采用无标签损失函数加权策略能够提升半监督语义分割的效果
18、作为优选,所述步骤2中计算有监督损失ll为:
19、
20、式中,为有语义分割模型对第i个有标签图像上第j个像素预测为第k个类别的概率,k为伪标签的总类数,pl为每个有标签图像的像素数;
21、所述步骤2中迭代训练中预测为第k个类别的像素的平均置信度作为第k类像素在半监督过程中生成伪标签的初始置信度阈值包括:
22、
23、式中,且
24、作为优选,所述步骤3基于初始置信度阈值设置无标签数据集采用交叉熵损失函数训练的权值wk,具体包括:
25、
26、作为优选,所述步骤a1中构建先快后慢下降形式的指数函数为:
27、
28、式中,初始置信度阈值c为用于缩小初始置信度阈值的常数,γ为指数函数的基数,cur_iter表示当前迭代次数,total_iter表示训练中需要执行的迭代总数,t为控制指数函数总体下降速度的系数。
29、作为预选,所述步骤a4中将无标签数据集放入教师模型fteacher中训练产生伪标签,并根据筛选阈值τk对当前迭代训练产生的各类伪标签进行筛选过滤为:
30、
31、式中,k表示为数据集的类别标签的总类数,教师模型fteacher预测第i个无标签图像上第j个像素的预测概率为对应的置信度为τ是置信度阈值,当cij的概率大于τ时,对应的像素有效,否则,对应的像素被忽略。
32、作为优选,所述步骤a5中基于有监督损失ll和无监督损失lu训练结果对训练后的学生模型进出参数更新,生成更新后的学生模型为:
33、
34、式中,t表示为当前迭代轮次cur_iter,表示为对学生模型的参数求偏导数,l为有监督损失ll和无监督损失lu的计量总和,具体为:
35、
36、作为优选,所述步骤a6中采用指数移动平均方法利用学生模型的参数更新教师模型为:
37、
38、式中,ξ为控制教师模型更新的权重。
39、作为优选,所述步骤a7中计算当前迭代训练轮次cur_iter下更新的教师模型在验证集上的评价指标值,包括使用平均交并比miou作为评价指标:
40、
41、
42、式中,n表示数据标签类别的个数,iiou表示第i个标签类别的交并比,i=1,2,...,n,iiou的阈值为[0,1]。
- 还没有人留言评论。精彩留言会获得点赞!