一种基于数据血缘关系亲密度的分级分类方法和装置与流程
本发明涉及数据分级分类,尤其涉及一种基于数据血缘关系亲密度的分级分类方法和装置。
背景技术:
1、现有的数据分类分级方法没有考虑数据表之间元数据的关联关系,规则比较僵硬,规则单一,不能配置,不能设置权重值或者阈值区间,不够灵活,不能通过数据表的亲密度关系进行关联和修正。由于未进行数据表元数据血缘关系的挖掘,有可能导致最终的分类分级结果不准确,没有将潜在的敏感数据表有效分类分级管理,造成潜在的数据安全风险。
技术实现思路
1、本发明针对上述问题,提出一种基于数据血缘关系亲密度的分级分类方法和装置,通过将分类分级的过程同数据表的亲密度结合起来,使得分类分级结果更合理。同时分类分级过程可以根据不同行业的不同场景和业务需求进行模型的选取,参数的设定,模型的训练等,使得分类分级更加灵活和通用。
2、为了实现上述目的,本发明采用以下技术方案:
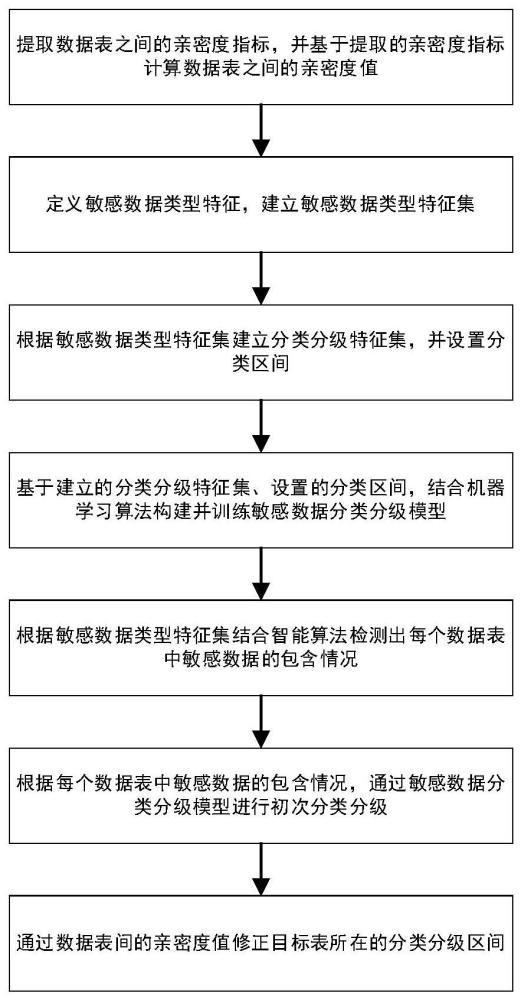
3、本发明一方面提出一种基于数据血缘关系亲密度的分级分类方法,包括:
4、步骤1,提取数据表之间的亲密度指标,并基于提取的亲密度指标计算数据表之间的亲密度值;
5、步骤2,定义敏感数据类型特征,建立敏感数据类型特征集;
6、步骤3,根据敏感数据类型特征集建立分类分级特征集,并设置分类区间;
7、步骤4,基于建立的分类分级特征集、设置的分类区间,结合机器学习算法构建并训练敏感数据分类分级模型;
8、步骤5,根据敏感数据类型特征集结合智能算法检测出每个数据表中敏感数据的包含情况;
9、步骤6,根据每个数据表中敏感数据的包含情况,通过敏感数据分类分级模型进行初次分类分级;
10、步骤7,通过数据表间的亲密度值修正目标表所在的分类分级区间。
11、进一步地,所述亲密度指标包括:是否存在主外键的关联约束,是否有触发器维护两个表之间的关系,是否有视图维护两个表之间的关系,是否有存储过程维护两个表之间的关系,查询语句中是否有join关键字维护两表之间的关系,两个表之间元数据的相似性。
12、进一步地,通过将提取的各亲密度指标进行加权求和计算数据表之间的亲密度值,各亲密度指标的权重分别为:0.1,0.1,0.2,0.2,0.2,0.2。
13、进一步地,所述步骤3包括:
14、根据实际业务需要设定需要分类的等级、每个等级对应的敏感数据类型特征集合及阈值;
15、设置分类区间,区间的间隔根据实际要分的类型数量而定。
16、进一步地,所述步骤4还包括:
17、采用网格搜索的方式,对影响模型精准度的参数进行测试,以便获得最优参数;
18、将模型训练好后,进行保存,以供后续加载使用。
19、进一步地,所述步骤5包括:
20、针对一张数据表,按照相应比例进行随机采样,根据敏感数据类型特征集,结合nlp算法或者正则方法检测出该数据表中包含的敏感字段的类型及数量。
21、进一步地,所述步骤6包括:
22、根据每个数据表中敏感数据的包含情况,得出每个数据表对应的敏感数据类型特征集合,并将其输入训练好的模型进行分类分级预测,得出针对目标表的分类分级预测结果,并记录对应关系。
23、进一步地,所述步骤7包括:
24、在坐标轴的第一象限中根据实际的分类数量将第一象限平均分;
25、将待修正的表按照预测的分类类型标注在该分类的角度的中点位置;
26、根据亲密度关系列表查找到与待修正的表有亲密关系的表,并根据该表的分类决定待修正表的移动方向,移动的角度通过亲密度值乘以每个分类的夹角及相差分类的间隔来确定。
27、本发明另一方面提出一种基于数据血缘关系亲密度的分级分类装置,包括:
28、亲密度值得出模块,用于提取数据表之间的亲密度指标,并基于提取的亲密度指标计算数据表之间的亲密度值;
29、敏感数据类型特征集构建模块,用于定义敏感数据类型特征,建立敏感数据类型特征集;
30、分类分级特征集构建模块,用于根据敏感数据类型特征集建立分类分级特征集,并设置分类区间;
31、模型构建及训练模块,用于基于建立的分类分级特征集、设置的分类区间,结合机器学习算法构建并训练敏感数据分类分级模型;
32、敏感数据获取模块,用于根据敏感数据类型特征集结合智能算法检测出每个数据表中敏感数据的包含情况;
33、分类分级模块,用于根据每个数据表中敏感数据的包含情况,通过敏感数据分类分级模型进行初次分类分级;
34、分类分级修正模块,用于通过数据表间的亲密度值修正目标表所在的分类分级区间。
35、进一步地,所述亲密度指标包括:是否存在主外键的关联约束,是否有触发器维护两个表之间的关系,是否有视图维护两个表之间的关系,是否有存储过程维护两个表之间的关系,查询语句中是否有join关键字维护两表之间的关系,两个表之间元数据的相似性。
36、进一步地,通过将提取的各亲密度指标进行加权求和计算数据表之间的亲密度值,各亲密度指标的权重分别为:0.1,0.1,0.2,0.2,0.2,0.2。
37、进一步地,所述分类分级特征集构建模块具体用于:
38、根据实际业务需要设定需要分类的等级、每个等级对应的敏感数据类型特征集合及阈值;
39、设置分类区间,区间的间隔根据实际要分的类型数量而定。
40、进一步地,所述模型构建及训练模块还用于:
41、采用网格搜索的方式,对影响模型精准度的参数进行测试,以便获得最优参数;
42、将模型训练好后,进行保存,以供后续加载使用。
43、进一步地,所述敏感数据获取模块具体用于:
44、针对一张数据表,按照相应比例进行随机采样,根据敏感数据类型特征集,结合nlp算法或者正则方法检测出该数据表中包含的敏感字段的类型及数量。
45、进一步地,所述分类分级模块具体用于:
46、根据每个数据表中敏感数据的包含情况,得出每个数据表对应的敏感数据类型特征集合,并将其输入训练好的模型进行分类分级预测,得出针对目标表的分类分级预测结果,并记录对应关系。
47、进一步地,所述分类分级修正模块具体用于:
48、在坐标轴的第一象限中根据实际的分类数量将第一象限平均分;
49、将待修正的表按照预测的分类类型标注在该分类的角度的中点位置;
50、根据亲密度关系列表查找到与待修正的表有亲密关系的表,并根据该表的分类决定待修正表的移动方向,移动的角度通过亲密度值乘以每个分类的夹角及相差分类的间隔来确定。
51、与现有技术相比,本发明具有的有益效果:
52、本发明通过将分类分级的过程同数据表的亲密度结合起来,使得分类分级结果更合理。同时分类分级过程可以根据不同行业的不同场景和业务需求进行模型的选取,参数的设定,模型的训练等,使得分类分级更加灵活和通用。
- 还没有人留言评论。精彩留言会获得点赞!