一种全渠道智能客服管理系统的制作方法
本发明涉及智能客服领域,尤其涉及一种全渠道智能客服管理系统。
背景技术:
1、随着互联网和移动互联网的快速发展,越来越多的企业将线上渠道作为与消费者互动的主要方式。在这些线上渠道中,智能客服系统成为提供快速、高效且个性化服务的重要工具。智能客服系统利用人工智能技术,如自然语言处理、机器学习等,能够对用户的问题进行准确理解,并给出相应的解答或建议。然而,由于现有的智能客服系统大多只针对单一渠道设计,例如仅支持文字对话、电话呼叫等,无法满足全渠道的客服需求。如何关联分析不同渠道环境下的用户对话,以便能够在不同渠道之间保持上下文一致性成为亟需解决的关键问题。针对该问题,本发明提出一种全渠道智能客服管理系统,实现不同渠道客户对话内容的无缝切换。
技术实现思路
1、有鉴于此,本发明提供一种全渠道智能客服管理系统,目的在于:1)采集用户在不同客服渠道的对话数据,并依据对话数据中词组的位置信息以及上下文信息进行语义信息编码处理,得到不同渠道的语义特征向量,实现全渠道的语义特征向量提取,并根据不同渠道的语义特征向量之间的注意力相关度矩阵,进行不同渠道的语义特征向量对齐,将全渠道的语义特征向量在同一维度表示,其中语义特征向量的对齐结果表征了不同渠道对话数据的对应关系,实现全渠道对话数据的表征对话数据对应关系的语义提取;2)根据语义特征向量的对齐关系,结合不同渠道的对话轮次信息对全渠道语义特征向量进行全渠道一致性合并,得到表征当前用户对话语义信息的一致性上下文语义特征向量,采用结合步长衰减迭代以及学习率衰减迭代的动量梯度迭代方式对对话生成模型进行训练,使用对话生成模型生成对话文本进行一致性客服应答,实现结合全渠道对话数据信息的客服对话生成。
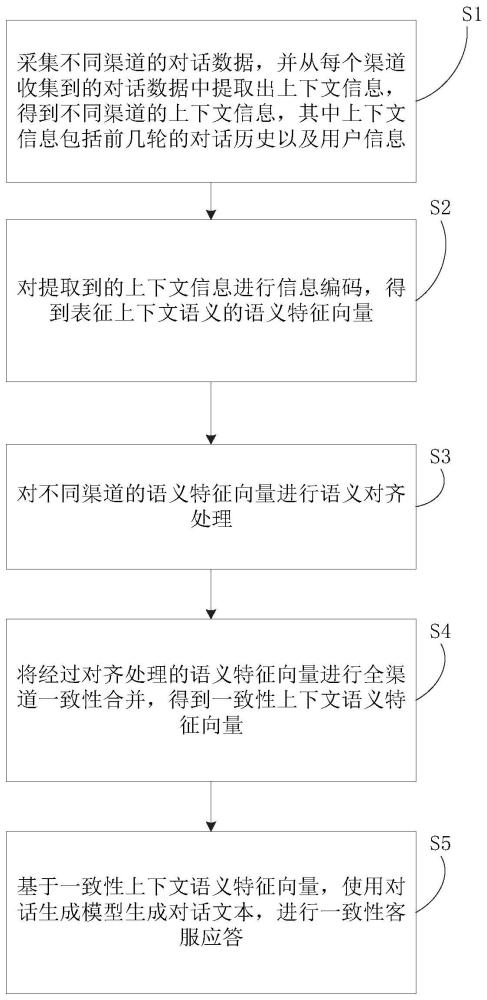
2、为实现上述目的,本发明提供的一种全渠道智能客服管理系统,包括以下步骤:
3、s1:采集不同渠道的对话数据,并从每个渠道收集到的对话数据中提取出上下文信息,得到不同渠道的上下文信息,其中上下文信息包括前几轮的对话历史以及用户信息;
4、s2:对提取到的上下文信息进行信息编码,得到表征上下文语义的语义特征向量,其中改进的transformer模型为所述信息编码的主要实施方法;
5、s3:对不同渠道的语义特征向量进行语义对齐处理,其中结合注意力机制计算语义相似度来调整各个渠道上下文的权重为所述上下文对齐的主要实施方法;
6、s4:将经过对齐处理的语义特征向量进行全渠道一致性合并,得到一致性上下文语义特征向量;
7、s5:基于一致性上下文语义特征向量,使用对话生成模型生成对话文本,进行一致性客服应答。
8、作为本发明的进一步改进方法:
9、可选地,所述s1步骤中采集不同渠道的对话数据,并从每个渠道收集到的对话数据中提取出上下文信息,包括:
10、采集不同渠道的对话数据,在本发明实施例中,所述渠道包括文字对话、电话呼叫以及视频通话,不同渠道的对话数据表示来自不同渠道的文本形式对话数据,并从每个渠道收集到的对话数据中提取出上下文信息,得到不同渠道的上下文信息,其中全渠道对话数据的上下文信息表示形式为:
11、
12、
13、其中:
14、xm表示第m种渠道对话数据的上下文信息,m表示渠道的总数;
15、表示第m种渠道获取的用户信息,表示第m种渠道获取的前numm轮历史对话数据,numm表示用户在第m种渠道的对话轮次;
16、表示历史对话数据的分词结果,表示历史对话数据中的第个词组,表示历史对话数据的词组总数。
17、可选地,所述s2步骤中对提取到的上下文信息进行信息编码,包括:
18、对提取到的全渠道对话数据的上下文信息进行信息编码,其中第m种渠道对话数据的上下文信息的信息编码流程为:
19、s21:对第m种渠道对话数据的上下文信息进行独热编码,其中的独热编码结果为:
20、
21、其中:
22、表示的独热编码结果,表示历史对话数据中第个词组的独热编码结果;
23、s22:对独热编码后的上下文信息进行词组位置信息嵌入,其中中第j个词组的词组位置信息嵌入结果为:
24、
25、其中:
26、表示中第j个词组的词组位置信息,
27、表示历史对话数据中第j个词组所在的句子数;
28、d表示词组独热编码结果的长度;
29、表示中第j个词组的词组位置信息嵌入结果;
30、构成独热编码结果的词组位置信息嵌入的编码表示结果
31、
32、s23:对词组位置信息嵌入的编码表示结果进行结合自注意力机制的语义编码表示处理,生成每个上下文信息的语义特征向量,其中编码表示结果的语义编码表示处理公式为:
33、
34、
35、
36、其中:
37、q(·)表示自编码处理,其中自编码处理包括编码层以及解码层,编码层对输入向量进行卷积降维处理,并由解码层对卷积结果进行重构,生成语义特征向量;
38、表示编码表示结果的语义特征向量;
39、t表示转置;
40、w1,w2,w3,w4,w5,w6为卷积参数;
41、⊙表示逐元素相乘运算符;
42、d∫表示词组位置信息嵌入的编码表示结果的长度;
43、表示编码表示结果的压缩表示结果;
44、sigmoid(·),softmax(·),relu(·)均为激活函数;
45、构成全渠道的语义特征向量集合:
46、
47、其中:
48、fm表示第m种渠道的语义特征向量序列。在本发明实施例中,用户信息的语义特征向量编码流程与对话数据的语义特征向量编码流程相同。
49、可选地,所述s3步骤中对不同渠道的语义特征向量进行语义对齐处理,包括:
50、对不同渠道的语义特征向量进行语义对齐处理,其中语义对齐处理流程为:
51、s31:设置语义对齐格式len,其中语义对齐格式为语义对齐处理后语义特征向量的长度;
52、s32:选取对话轮次最多的渠道的语义特征向量序列作为起始语义特征向量序列u0,并将起始语义特征向量序列扩展为长度为l的特征向量,作为该渠道下语义对齐处理后的语义特征向量;在本发明实施例中,所述语义特征向量序列的扩展处理为对语义特征向量序列进行末端补0扩展;
53、s33:计算得到任意渠道下语义特征向量序列与起始语义特征向量序列u0的注意力相关度矩阵,其中语义特征向量序列fm与起始语义特征向量序列u0的注意力相关度矩阵为:
54、cm,0=softmax(em,0)
55、
56、
57、
58、其中:
59、表示语义特征向量序列fm中语义特征向量的注意力权重,rm表示语义特征向量序列fm的注意力权重序列;
60、h0表示起始语义特征向量序列u0中不同语义特征向量的注意力权重所构成的注意力权重序列;
61、extend(·)表示对注意力权重序列进行扩展处理,使得扩展后的注意力权重序列与起始语义特征向量序列所对应注意力权重序列等长;在本发明实施例中,所述注意力权重扩展处理为对注意力权重序列进行末端补0扩展处理;
62、cm,0表示语义特征向量序列fm与起始语义特征向量序列u0的注意力相关度矩阵;
63、s34:基于注意力相关度矩阵生成不同渠道下语义特征向量序列与起始语义特征向量序列u0的语义对齐结果,其中语义特征向量序列fm与起始语义特征向量序列u0的语义对齐结果为:
64、fm=extend(fm·cm,0t)
65、其中:
66、fm表示语义特征向量序列fm的语义对齐结果;
67、extend(·)表示对语义特征向量序列的注意力对齐结果进行扩展处理;在本发明实施例中,注意力对齐结果的扩展处理为对注意力对齐结果进行末端补0,使得注意力对齐结果的长度达到语义对齐格式len;
68、构成全渠道下的经对齐处理的语义特征向量集合:{fm|m∈[1,m]}。
69、可选地,所述s4步骤中将经过对齐处理的语义特征向量进行全渠道一致性合并,包括:
70、将经过对齐处理的语义特征向量进行全渠道一致性合并,得到一致性上下文语义特征向量,其中全渠道一致性合并的流程为:
71、s41:计算不同渠道的对话轮次信息,其中第m种渠道的对话轮次信息为:
72、
73、其中:
74、hm表示第m种渠道的对话轮次信息;
75、numm表示用户在第m种渠道的对话轮次;
76、s42:根据不同渠道的对话轮次信息,进行全渠道的语义特征向量一致性合并,得到一致性上下文语义特征向量:
77、
78、其中:
79、f表示一致性上下文语义特征向量。
80、可选地,所述s5步骤中基于一致性上下文语义特征向量,使用对话生成模型生成对话文本,进行客服应答,包括:
81、将一致性上下文语义特征向量f作为对话生成模型输入,使用对话生成模型生成对话文本,并将所生成对话文本转换为用户最近使用渠道的对话形式进行客服应答,其中基于对话生成模型的对话文本生成流程为:
82、s51:构建并训练对话生成模型,所述对话生成模型包括输入层、概率计算层以及对话选取输出层;
83、s52:输入层接收一致性上下文语义特征向量f,将一致性上下文语义特征向量f输入到概率计算层;
84、s53:概率计算层计算一致性上下文语义特征向量f与对话文本库中任意对话文本的经对齐处理后语义特征向量的相似度,其中一致性上下文语义特征向量f与经对齐处理后语义特征向量f′的相似度计算公式为:
85、
86、其中:
87、||·||2表示l2范数;
88、sim(f,f′)表示一致性上下文语义特征向量f与经对齐处理后语义特征向量f′的相似度;
89、θ*表示概率计算层中的权值参数;
90、s54:对话选取输出层选取相似度最高的经对齐处理后语义特征向量所对应的对话文本进行输出。在本发明实施例中,对话文本库中任意对话文本的经对齐处理后语义特征向量的生成流程与所采集对话数据的语义特征向量提取流程相同,并对对话文本库中任意对话文本的语义特征向量进行扩展处理,得到对话文本库中任意对话文本的经对齐处理后语义特征向量。
91、可选地,所述s51步骤中构建并训练对话生成模型,包括:
92、s511:获取z组一致性上下文语义特征向量与真实应答文本的语义特征向量构成模型训练数据集data:
93、data={(gz,bz)|z∈[1,z]}
94、其中:
95、gz表示第z组一致性上下文语义特征向量;
96、bz表示一致性上下文语义特征向量gz对应的真实应答文本的语义特征向量;
97、s512:构建对话生成模型的训练目标函数:
98、
99、其中:
100、loss(θ)表示对话生成模型的训练目标函数,θ表示对话生成模型中概率计算层的待训练权值参数;
101、s513:生成初始化的待训练权值参数θ0以及参数迭代步长λ0,并设置参数的当前迭代次数为v,v的初始值为0,最大值为v;
102、s514:对第v次迭代得到的待训练权值参数θv进行迭代:
103、
104、θv+1=θv-αvλv+1
105、
106、其中:
107、λv表示第v次迭代的参数迭代步长;
108、grad(loss(θv))表示函数loss(θv)的梯度;
109、αv表示待训练权值参数在第v次迭代的学习率,α0=0.9,表示初始学习率;
110、s515:令v=v+1,返回步骤s514;
111、s516:将第v次迭代得到的待训练权值参数,作为训练得到的概率计算层中的权值参数θ*。
112、为了解决上述问题,本发明提供一种全渠道智能客服管理系统,其特征在于,所述系统包括:
113、全渠道信息采集模块,用于采集不同渠道的对话数据,并从每个渠道收集到的对话数据中提取出上下文信息,得到不同渠道的上下文信息;
114、语义特征提取模块,用于对提取到的上下文信息进行信息编码,得到表征上下文语义的语义特征向量,对不同渠道的语义特征向量进行语义对齐处理,将经过对齐处理的语义特征向量进行全渠道一致性合并,得到一致性上下文语义特征向量;
115、全渠道客服对话生成装置,用于基于一致性上下文语义特征向量,使用对话生成模型生成对话文本,进行一致性客服应答。
116、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
117、存储器,存储至少一个指令;
118、通信接口,实现电子设备通信;及
119、处理器,执行所述存储器中存储的指令以实现上述所述的一种全渠道智能客服管理系统。
120、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现上述所述的一种全渠道智能客服管理系统。
121、相对于现有技术,本发明提出一种全渠道智能客服管理系统,该技术具有以下优势:
122、首先,本方案提出一种对话数据的编码方式以及语义对齐方法,对提取到的全渠道对话数据的上下文信息进行信息编码,其中第m种渠道对话数据的上下文信息的信息编码流程为:对第m种渠道对话数据的上下文信息进行独热编码,其中的独热编码结果为:
123、
124、其中:表示的独热编码结果,表示历史对话数据中第个词组的独热编码结果;对独热编码后的上下文信息进行词组位置信息嵌入,其中中第j个词组的词组位置信息嵌入结果为:
125、
126、其中:表示中第j个词组的词组位置信息,表示历史对话数据中第j个词组所在的句子数;d表示词组独热编码结果的长度;表示中第j个词组的词组位置信息嵌入结果;构成独热编码结果的词组位置信息嵌入的编码表示结果
127、
128、对词组位置信息嵌入的编码表示结果进行结合自注意力机制的语义编码表示处理,生成每个上下文信息的语义特征向量,其中编码表示结果的语义编码表示处理公式为:
129、
130、
131、
132、其中:表示编码表示结果的语义特征向量;t表示转置;构成全渠道的语义特征向量集合:
133、
134、其中:fm表示第m种渠道的语义特征向量序列。对不同渠道的语义特征向量进行语义对齐处理,其中语义对齐处理流程为:设置语义对齐格式len,其中语义对齐格式为语义对齐处理后语义特征向量的长度;选取对话轮次最多的渠道的语义特征向量序列作为起始语义特征向量序列u0,并将起始语义特征向量序列扩展为长度为l的特征向量,作为该渠道下语义对齐处理后的语义特征向量;计算得到任意渠道下语义特征向量序列与起始语义特征向量序列u0的注意力相关度矩阵,其中语义特征向量序列fm与起始语义特征向量序列u0的注意力相关度矩阵为:
135、cm,0=softmax(em,0)
136、
137、
138、
139、基于注意力相关度矩阵生成不同渠道下语义特征向量序列与起始语义特征向量序列u0的语义对齐结果,其中语义特征向量序列fm与起始语义特征向量序列u0的语义对齐结果为:
140、fm=extend(fm·cm,0t)
141、其中:fm表示语义特征向量序列fm的语义对齐结果;extend(·)表示对语义特征向量序列的注意力对齐结果进行扩展处理。本方案采集用户在不同客服渠道的对话数据,并依据对话数据中词组的位置信息以及上下文信息进行语义信息编码处理,得到不同渠道的语义特征向量,实现全渠道的语义特征向量提取,并根据不同渠道的语义特征向量之间的注意力相关度矩阵,进行不同渠道的语义特征向量对齐,将全渠道的语义特征向量在同一维度表示,其中语义特征向量的对齐结果表征了不同渠道对话数据的对应关系,实现全渠道对话数据的表征对话数据对应关系的语义提取。
142、同时,本方案提出一种结合全渠道对话数据语义信息的对话生成方式,将经过对齐处理的语义特征向量进行全渠道一致性合并,得到一致性上下文语义特征向量,其中全渠道一致性合并的流程为:计算不同渠道的对话轮次信息,其中第m种渠道的对话轮次信息为:
143、
144、其中:hm表示第m种渠道的对话轮次信息;numm表示用户在第m种渠道的对话轮次;根据不同渠道的对话轮次信息,进行全渠道的语义特征向量一致性合并,得到一致性上下文语义特征向量:
145、
146、其中:f表示一致性上下文语义特征向量。将一致性上下文语义特征向量f作为对话生成模型输入,使用对话生成模型生成对话文本,并将所生成对话文本转换为用户最近使用渠道的对话形式进行客服应答,其中基于对话生成模型的对话文本生成流程为:构建并训练对话生成模型,所述对话生成模型包括输入层、概率计算层以及对话选取输出层;输入层接收一致性上下文语义特征向量f,将一致性上下文语义特征向量f输入到概率计算层;概率计算层计算一致性上下文语义特征向量f与对话文本库中任意对话文本的经对齐处理后语义特征向量的相似度,其中一致性上下文语义特征向量f与经对齐处理后语义特征向量f′的相似度计算公式为:
147、
148、其中:||·||2表示l2范数;sim(f,f′)表示一致性上下文语义特征向量f与经对齐处理后语义特征向量f′的相似度;θ*表示概率计算层中的权值参数;对话选取输出层选取相似度最高的经对齐处理后语义特征向量所对应的对话文本进行输出。本方案根据语义特征向量的对齐关系,结合不同渠道的对话轮次信息对全渠道语义特征向量进行全渠道一致性合并,得到表征当前用户对话语义信息的一致性上下文语义特征向量,采用结合步长衰减迭代以及学习率衰减迭代的动量梯度迭代方式对对话生成模型进行训练,使用对话生成模型生成对话文本进行一致性客服应答,实现结合全渠道对话数据信息的客服对话生成。
- 还没有人留言评论。精彩留言会获得点赞!