一种文档关键要素识别方法、装置、设备及介质与流程
本发明涉及数据处理,尤其是涉及一种文档关键要素识别方法、装置、设备及介质。
背景技术:
1、对于pdf文件中文本内容的提取,现有技术多采用机器学习或者深度学习中小规模模型,或者ocr模型来实现。然而,这些模型只针对固定样式的文本有较高的召回率和准确率,对于不定格式样本,泛化能力较弱。此外,针对复杂文档格式,包含文字、段落、图、表、页眉页脚等混合格式的样本,元素提取召回率较低,模型适用的泛化能力不足。尤其是,当待识别的页面中存在跨页元素时,缺少一种通用的能够快速、准确实现跨页元素识别与拼接的方法。
2、cn116665236a公开了一种跨页段落识别拼接方法及装置,该方法通过定位当前页文件和下一页文件中的待拼接句子,从而根据语义依存特性分析待拼接句子是否为一句完整语句来确认当前页文件和下一页文件中是否存在跨页段落。该方法需要依据段落间的语义依存特性来判断是否属于完整语句,因此该方法仅限于跨页段落的识别拼接,而难以应对其他元素的跨页识别。
3、cn107844468a公开了一种表格信息跨页识别方法,通过获取前一表格文字内容的位置信息、标签信息和下一表格文字内容的位置信息、标签信息,并比对下一表格每列文字的左边沿坐标与前一表格对应每列文字的左边沿坐标实现跨页表格识别;当下一表格每列文字的左边沿坐标与前一表格对应每列文字的左边沿坐标都相同时,比对下一表格每行文字的页码与前一表格每行文字的页码;若下一表格每行文字的页码与前一表格每行文字的页码存在不同,则判定下一表格与前一表格为存在跨页情形的同一表格。该方法需要确定表格中每列文字的左边沿坐标和每一行文字的页码,需要获取的相关信息较多,需要逐行逐列进行比对,方法复杂,且同样不适用于其他跨页元素的识别。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种文档关键要素识别方法、装置、设备及介质,解决复杂样本的模型输入不确定性,提高识别模型的召回率和准确率,实现跨页元素的通用性识别与合并,加强文本元素提取的适用性和泛化能力。
2、本发明的目的可以通过以下技术方案来实现:
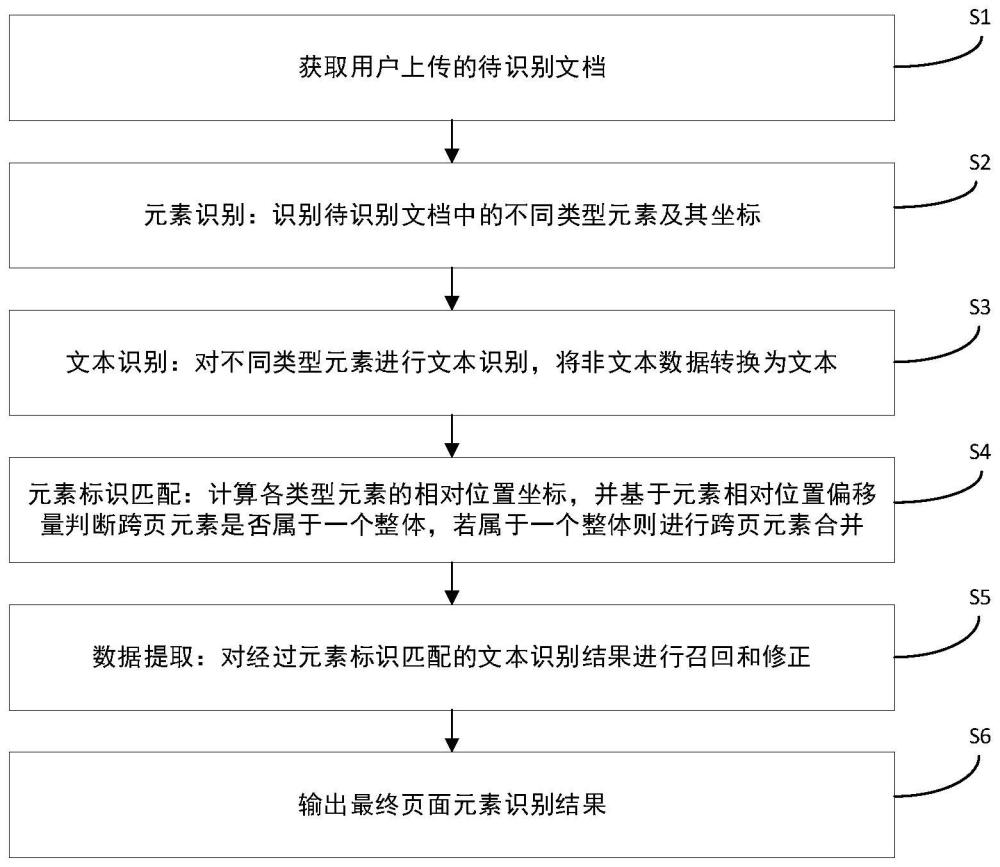
3、根据本发明的第一方面,提供了一种文档关键要素识别方法,该方法包括以下步骤:
4、s1、获取用户上传的待识别文档;
5、s2、元素识别:识别待识别文档中的不同类型元素及其坐标;
6、s3、文本识别:对不同类型元素进行文本识别,将非文本数据转换为文本;
7、s4、元素标识匹配:计算各类型元素的相对位置坐标,并基于元素相对位置偏移量判断跨页元素是否属于一个整体,若属于一个整体则进行跨页元素合并;
8、s5、数据提取:对经过元素标识匹配的文本识别结果进行召回和修正;
9、s6、输出最终页面元素识别结果。
10、作为优选的技术方案,所述的步骤s2中,元素识别具体为:
11、对于页眉页脚,按照文档的部署尺寸,确定坐标定位前预设距离和后预设距离位置上的元素为页眉和页脚;
12、对于图片、盖章和手写体,利用ocr技术,确认区域内的像素合集特征为图片、盖章、手写体的内容;
13、对于表格,利用线条识别,确定区域内的线条及文字内容为表格;
14、对于文字段落,根据文档中文字的缩进和换行确定文字段落。
15、作为优选的技术方案,所述的步骤s4中,根据文档页面信息与元素的坐标信息确定元素在页面的相对位置坐标,具体为:
16、将前后两个尺寸不同的页面上的元素坐标映射到归一化空间,其中,元素在原空间中的位置以三元组表示,所述三元组由页面位置标识符和平面坐标组成,当页面位置标识符表明当前元素在前一页时,将页面元素的原始平面坐标除以前一页页面长度得到映射到归一化空间的新坐标;当页面位置标识符表明当前元素在后一页时,将页面元素的原始平面x轴坐标值除以后一页页面长度,得到映射到归一化空间的新x轴坐标,将页面元素的原始平面y轴坐标值除以后一页页面长度后,与前一页页面的宽度与长度的比值相加,作为映射到归一化空间后的新y轴坐标。
17、作为优选的技术方案,所述元素相对位置偏移量的计算方法为:计算归一化后的目标元素相对位置坐标之间的偏置曼哈顿距离,作为元素相对位置偏移量,其中,偏置曼哈顿距离为两个坐标之间横坐标差的绝对值乘以偏置系数后,加上纵坐标差的绝对值,其中,偏置系数的设定目标为放大水平方向上的位置差距以提高垂直方向上的近距优先级。
18、作为优选的技术方案,所述的步骤s4中,对于跨页表格,将连续两页文本中,识别出的前一页底部表格与后一页顶部表格,排除已打标的页眉与页脚内容,按照表格的相对位置偏移量计算结果,判断两段表格是否为一个整体,若为同一整体,则将两段表格的页面坐标合并。
19、作为优选的技术方案,所述的步骤s4中,对于跨页段落将连续两页文本中,识别出的前一页底部段落的文字与后一页顶部段落的文字,排除已打标的页眉与页脚内容,按照段落的相对位置偏移量计算结果,判断两段文字是否为一个整体,若为同一整体,则将两段文字的页面坐标合并。
20、作为优选的技术方案,所述的步骤s5包括以下步骤:
21、s51、识别结果召回:将经过元素标识匹配的文本识别结果输入语义识别模型,召回识别元素内容;
22、s52、识别结果修正:利用预处理的元素类型标识和元素坐标,过滤误识别结果。
23、根据本发明的第二方面,提供了一种文档关键要素识别装置,该装置包括:
24、输入模块,用于获取用户上传的待识别文档;
25、元素识别模块,用于识别待识别文档中的不同类型元素及其坐标;
26、文本识别模块,用于对不同类型元素进行文本识别,将非文本数据转换为文本;
27、元素标识匹配模块,用于计算各类型元素的相对位置坐标,并基于元素相对位置偏移量判断跨页元素是否属于一个整体,若属于一个整体则进行跨页元素合并;
28、数据提取模块,用于对经过元素标识匹配的文本识别结果进行召回和修正;
29、输出模块,用于输出最终页面元素识别结果。
30、根据本发明的第三方面,提供了一种电子设备,包括存储器和处理器,所述存储器上存储有计算机程序,所述处理器执行所述程序时实现所述的方法。
31、根据本发明的第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现所述的方法。
32、与现有技术相比,本发明具有以下有益效果:
33、(1)相对于传统模式,本发明在通过文档的识别结构中,补充了文本格式的元素类型信息,如段落、表格、图片、页眉页脚、手写、盖章等元素,将文字本身内容的相关性更为集中体现,文字关联关系加强,可有效提高识别模型的对输出结果的召回率及准确率。
34、(2)本发明通过元素标识匹配,识别文本结构的上下页所属关系的关联,解决因为跨页数据的切分及不完整问题,实现跨页元素的通用性识别与匹配。
- 还没有人留言评论。精彩留言会获得点赞!