基于句子主干的稀缺资源神经机器翻译的数据增强方法
本发明属于神经机器翻译,尤其涉及基于句子主干的稀缺资源神经机器翻译的数据增强方法。
背景技术:
1、近年来,神经机器翻译模型以端到端的方式对自然语言的翻译过程进行建模,取得了显著的进展。其中,以transformer为代表的端到端神经机器翻译(nmt)模型在各类翻译任务中展现了卓越的性能。transformer作为当前性能卓越的神经机器翻译模型,在学术界和企业界备受推崇并广泛使用。它遵循端到端的深度学习模型架构,由编码器和解码器两部分组成,完全依赖于注意力机制对文本序列进行建模,从而有效的解决长距离文本遗忘问题。
2、然而,nmt系统的质量在很大程度上依赖于大量的双语平行数据。对于稀缺资源语言对的翻译,如越南语→英语,缺乏足够的双语平行数据,成为限制翻译系统性能的瓶颈。人工构建高质量的双语数据不仅成本高昂,而且难以满足大规模训练的需求。因此,如何有效解决稀缺资源语言对的翻译问题,成为了学术界和工业界共同面临的挑战。在这样的背景下,许多学者已经对稀缺资源翻译任务进行了广泛而深入的探索,旨在克服数据稀缺的困境,推动nmt模型在更多语言对上的应用。
3、数据增强是通过生成额外的训练数据进而提升深度学习模型性能重要技巧,已广泛应用于许多领域。例如在计算机视觉领域中,通过对训练样本进行裁剪、翻转和调整大小等方式进行数据增强。由于自然语言的复杂性,这些方式并不直接适用于神经机器翻译。在神经机器翻译领域,数据增强用于产生更多的噪声数据提高模型的鲁棒性,或生成更多样化的训练样本以提升模型的翻译性能。目前,该领域的数据增强方法主要分为两大类:
4、一类为基于词替换方法,目前现有的词级数据增强方法主要包括随机词替换和删除。该类方法是建立在具备一定规模的双语数据的基础上,分别替换源语言和目标语言中的词扩展双语数据。fadaee等学者在“data augmentation for low-resource neuralmachine translation”中提出一种新颖的词替换方法,该方法通过模型预测高频词位置,并利用低频词进行替换,从而调整词汇的频率分布。同时,他们还利用词对齐所生成的双语词典完成源语言端词替换。这种简单的词汇替换方式在实验中取得了较好的效果。wang等学者在“an efficient data augmentation algorithm for neural machinetranslation”中提出了一种独立采样词汇表,通过词汇表替换源语言和目标语种的词汇。xie等学者在“data noising as smoothing in neural network language models”中则提出了两种给句子添加噪音的方法,分别是使用占位符随机替换句子中的词和使用具有相似概率分布的词替换其他词。artetxe等学者在“unsupervised neural machinetranslation”中提出一种文本内相近词随机替换的方法,通过替换相近词增加数据多样性。此外,杨丹等学者在“基于数据增强的藏汉神经机器翻译研究”中提出同义词替换和反向翻译的策略进行数据增强。尤丛丛等学者在“基于同义词数据增强的汉越神经机器翻译方法”中提出了通过单语词向量寻找低频词的同义词,进而通过同义词替换扩充双语语料。然而,这类基于词替换的数据增强方法存在一定的弊端,即可能导致语义发生重大变化甚至语义错误的现象。
5、另一类方法引入了单语数据来进行数据增强。在源语言单语数据的基础上,zhang等学者在“exploiting source-side monolingual data in neural machinetranslation”中提出了一种自学习的方法,利用源语言的单语数据,通过翻译生成目标语言端的句子,从而扩充训练集并提高模型翻译性能。而sennrich等学者在“improvingneural machine translation models with monolingual data”中则提出了一种称为反向翻译的数据增强方法,该方法将目标端单语句子翻译成源语言端句子,以此扩充原始训练集,这种方法在许多工作中都证明了有效性。在反向翻译的基础上,he等学者在“duallearning for machine translation”中进一步扩展了该方法,同时使用源语言端和目标语言端的单语数据对数据集进行扩充。另外,lmamura等学者在“enhancement of encoderand attention using target monolingual corpora in neural machine translation”中提出了一种随机采样源语言端句子的方法,这种方法通过随机选择源语言端的句子来对目标端进行数据增强。这些方法都取得了一定的提升效果,但都需要引入额外的单语数据。
6、与先前的数据增强方法不同,本发明提出基于句子主干的数据增强方法不需要引入额外的资源,仅通过解析句法树构造伪数据,并以此扩充原始训练集。
技术实现思路
1、本发明的目的在于提供基于句子主干的稀缺资源神经机器翻译的数据增强方法,以解决上述背景技术中提出的现有技术中神经机器翻译领域的数据增强方法存在不足,解决基于词替换的数据增强方法可能导致语义发生重大变化甚至语义错误的现象,和引入单语数据的数据增强方法都需要引入额外的单语数据等问题。
2、为实现上述目的,本发明采用以下技术方案实现:
3、基于句子主干的稀缺资源神经机器翻译的数据增强方法,包括以下步骤:
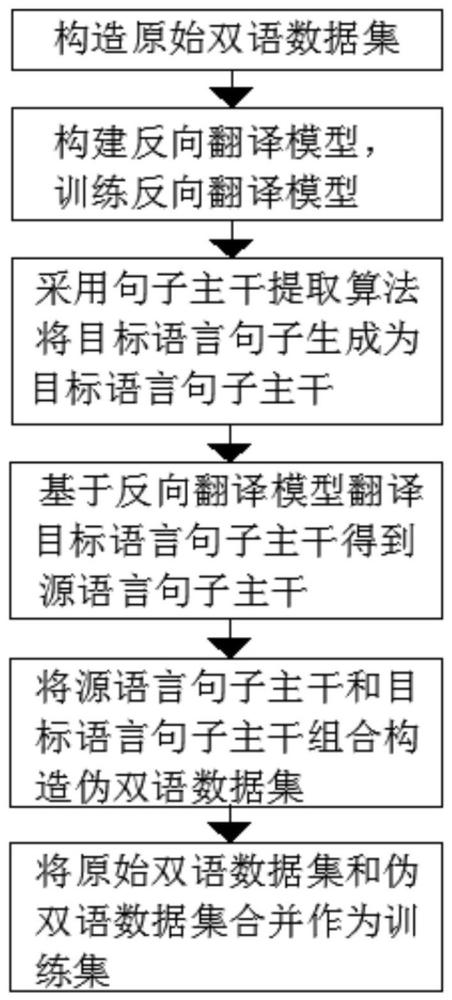
4、s1、构造原始双语数据集d={s,t},原始双语数据集d包括源语言句子s和目标语言句子t;
5、s2、构建反向翻译模型,采用原始双语数据集d训练反向翻译模型;
6、s3、采用句子主干提取算法将目标语言句子t生成为目标语言句子主干t′;
7、s4、基于反向翻译模型翻译目标语言句子主干t′得到源语言句子主干s′;
8、s5、将源语言句子主干s′和目标语言句子主干t′组合构造伪双语数据集d′={s′,t′};
9、s6、将原始双语数据集d和伪双语数据集d′合并,作为神经机器翻译模型的训练集。
10、优选地,所述s3中句子主干提取算法基于句法分析树实现,句法分析树由叶子结点和非叶子节点组成,句子中的所有词构成句法分析树的叶子节点,句子的成分属性词构成句法分析树的非叶子结点;
11、使用corenlp工具对句子s构建句法分析树,叶子节点表示为集合l={s},非叶子节点表示为集合n={vp,vc,np,vv,...,nn};
12、其中,vp代表动词短语,np代表名词短语,vv代表动词,nn代表常用名词,vc代表是。
13、优选地,所述s3中句子主干提取算法,具体如下:
14、输入:句子s的句法分析树t;
15、输出:句子s主干;
16、a)候选集合s={}
17、b)设置深度d=depth(x)
18、c)将t中所有深度为d的节点加入s
19、d)对于s中的节点所有非叶子节点x
20、x’=x的第一个nn节点,如果x是np节点
21、x’=x的第一个叶子节点,如果x是非np节点
22、x’=x的叶子节点,如果x有且仅有一个叶子节点
23、将x’节点替换s中的x节点
24、e)将s中的各个节点连接,组成句子主干st;
25、其中,x为最顶层的叶子节点。
26、优选地,所述s2中反向翻译模型采用transformer模型,所述反向翻译模型是由原始双语数据集d训练的从目标语言到源语言的翻译模型。
27、一种应用上述数据增强方法的基于句子主干的稀缺资源神经机器翻译方法,包括以下步骤:
28、s1、构建神经机器翻译模型;
29、s2、构造数据集,采用数据增强方法对数据集进行数据增强;
30、s3、采用数据增强后的数据集作为训练集,利用训练集对神经机器翻译模型进行训练;
31、s4、将训练后的神经机器翻译模型进行稀缺资源翻译。
32、优选地,所述神经机器翻译模型采用transformer模型,所述transformer模型包含编码器和解码器;
33、所述编码器由n个相同的神经网络层堆叠组成,每个神经网络层都包含两个子层:多头注意力子层和前馈神经网络层;
34、所述解码器由n个相同的神经网络层组成,每个神经网络层由三个子层组成;第一个子层为掩码多头注意力子层,第二个子层为编码器-解码器多头自注意力机制层,第三个子层是前馈神经网络层;
35、在编码器和解码器的子层之间,还应用残差连接和层归一化技术。
36、优选地,注意力机制是一种将输入词向量为d映射到查询q、键k和值v的向量输出的技术;这组向量输出经过点积操作后,通过softmax函数计算权重,最终返回值的加权和;这一过程能够捕捉输入序列中的关键信息,并对其进行有效地建模和表示,计算方法如下:
37、
38、其中,dk为词向量的维度;
39、多头注意力机制则采用h个注意力头表示输入信息,将多头注意力的输出拼接后乘以权重矩阵得到向量输出,公式如下:
40、multihead(q,k,v)=concat(head1,…,headh)wo
41、
42、其中h代表多头注意力机制中头的数量。
43、优选地,前馈神经网络层由两个线性变换组成,在两次线性变换中应用一次relu激活函数,公式如下:
44、ffn(x)=max(0,xw1+b1)w2+b2 (3)。
45、优选地,所述编码器的多头注意力子层接入源语端,所述解码器的掩码多头注意力机制接入目标语端。
46、优选地,将句子主干提取算法应用于目标语端,基于此进行数据增强。
47、与现有技术相比,本发明的有益效果是:
48、(1)、本发明中基于句子主干的稀缺资源神经机器翻译的数据增强方法通过目标语端句子主干和反向翻译模型生成伪平行数据,从而扩充训练数据。通过该方法,可以更加充分地利用现有数据,增加训练样本的多样性,提升模型的翻译质量。
49、(2)、本发明中方法以原始双语数据集为基础,通过使用句子主干和反向翻译生成伪双语数据,由于句子主干源于原始数据集中的目标端句子,其长度通常小于原始句子,因此生成的伪双语句对的长度也会相应减少,构造的伪双语数据集的平均长度小于原始数据集的平均长度。因此,这种方法生成的伪平行句对在源语言端和目标语言端都表现出长度简洁和结构完整的特点,形成更简洁且结构完整的伪平行数据。
- 还没有人留言评论。精彩留言会获得点赞!