一种基于改进信息检索算法的工艺知识规范化方法及系统
本发明属于先进制造技术智能化信息,具体涉及一种基于改进信息检索算法的工艺知识规范化方法及系统。
背景技术:
1、复杂零件加工对精度要求高且涉及繁琐的加工过程,其参数决策过程需要考虑零件整个生命周期中涉及的多类实体和多种关系,具有多粒度和多意图的特点。为了正确地推荐工艺人员所需的知识,必须对复杂工艺问题进行情景分析,获取约束条件,进而构建查询语句来完成工艺知识的推荐。然而,机械加工工艺实体通常具有多样性的特点,同一个工艺实体可能有多个不同的称呼。当工艺人员使用信息检索系统查找工艺知识时,由于从业时间和个人习惯的不同,对于同一个工艺实体的表达方式往往不一致,不同用户可能使用不同的方式来描述相同的事物或问题。此外,目前的命名实体识别模型在细粒度实体识别方面仍存在精度不高的问题,识别出的工艺实体可能是非规范实体,可能存在错字、漏字等问题,无法直接与知识图谱中的规范实体对应。为了进一步完成后续的工艺知识推荐任务,向工艺人员提供正确的工艺知识,需要对这类非规范实体进行规范化处理,将其与知识图谱中的规范实体进行映射。
2、为了实现非规范实体到规范实体的映射,并完成工艺实体规范化任务,本发明将该任务定义为短文本相似度匹配任务。短文本相似度匹配任务是自然语言处理领域的一项重要任务,旨在度量两个短文本之间的相似度或相关性。其目标是对给定的两个短文本进行比较,并确定它们之间的相似度得分或相似度等级。为了解决短文本相似度匹配任务,通常采用机器学习方法和深度学习技术。在传统机器学习方法中,可以利用各种特征表示方法,如词袋模型、词频-逆向文件频率(term frequency–inverse document frequency,tf-idf)算法、best matching 25(bm25)算法等,通过计算特征之间的相似度分数来确定文本相似度。而在基于深度学习的方法中,常用的神经网络模型包括卷积神经网络(convolutional neural network,cnn)、循环神经网络(recurrent neural network,rnn)以及基于转化器的双向编码表征(bidirectional encoder representation fromtransformers,bert)等。
3、然而,采用传统的机器学习方法,如tf-idf和bm25等,在文本相似度匹配任务上的准确率较低,需要针对特定内容进行进一步改进优化。而基于深度学习的方法则需要大量的训练数据才能获得良好的匹配效果,此外,其计算过程更加复杂,对计算资源的需求较高。因此,在工艺实体规范化任务中,需要综合考虑准确率和计算资源消耗的平衡。本发明将探索针对该任务的优化方法,以提高文本相似度匹配的准确性,并在计算资源消耗方面做出适当的权衡。
技术实现思路
1、本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于改进信息检索算法的工艺知识规范化方法及系统,将工艺问题中的非规范实体映射到知识图谱中的规范实体,用于解决由于模型识别误差、文本输入失误以及工艺实体多样性等原因导致的非规范实体无法直接与知识图谱中的规范实体对应的技术问题,以便进行后续的工艺知识推荐和处理。
2、本发明采用以下技术方案:
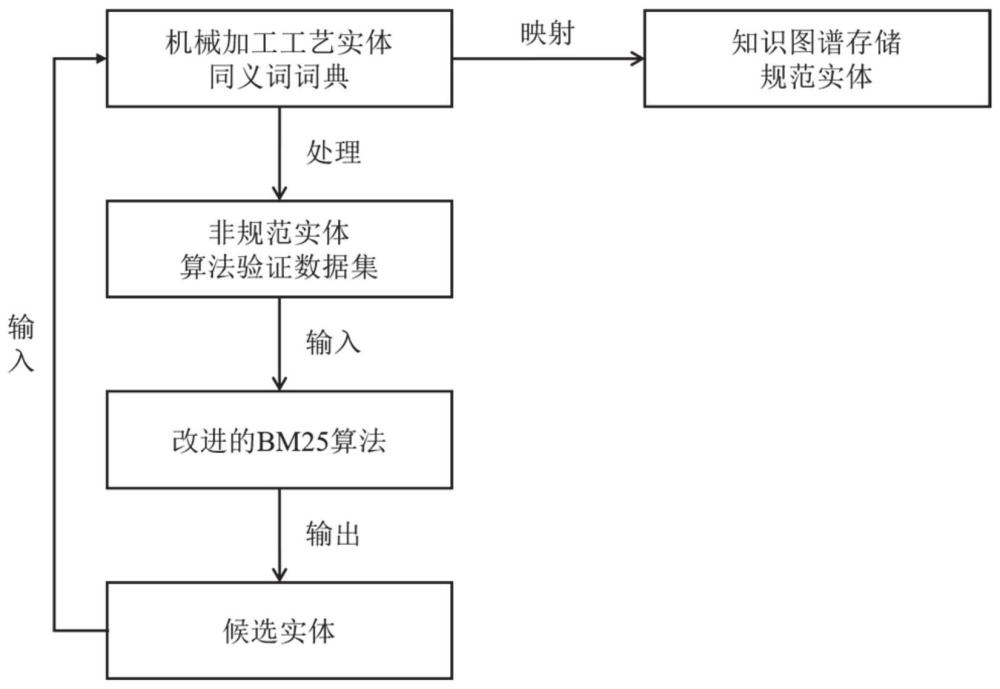
3、一种基于改进信息检索算法的工艺知识规范化方法,包括以下步骤:
4、s1、基于知识图谱中的规范实体,构建工艺实体同义词词典;
5、s2、基于步骤s1构建的工艺实体同义词词典结合工艺问题中非规范实体特点,构建验证数据集;
6、s3、基于改进的bm25算法计算验证数据集中不规范实体与词典中规范实体的相似度分数;
7、s4、将步骤s3得到的候选实体与步骤s1构建的工艺实体同义词词典进行映射,获得知识图谱中唯一表示的规范实体,完成工艺知识规范化处理。
8、优选地,工艺实体同义词词典包括以下实体类型:
9、零件材料、零件类型、加工特征、加工工序、机床、刀具、夹具、切削液、粗糙度和精度,同一实体的不同指称包括中文全称、中文别名、英文全称和英文缩写。
10、优选地,通过随机删除字符、随机增加字符、随机替换字符以及随机替换同音字符的方式构建验证数据集。
11、优选地,改进的bm25算法具体为:
12、s301、将不规范实体使用1-gram方法切分,将每个实体切分为单个字符的形式,基于词频计算非规范实体中每个字符与实体库中规范实体的相关性系数,计算单个字符的分数;
13、s302、计算每个字符的逆文档频率;
14、s303、计算每个字符的位置权重因子;
15、s304、得到非规范实体的中每个字符与对比工艺实体的相似度分数后,将其累加,获得当前对比工艺实体最终的相似度分数,重复上述计算过程,计算非规范实体与字典中所有工艺实体的相似度分数,将分数最高的工艺实体作为候选实体。
16、更优选地,步骤s301中,每个字符的词频分数tf(w,d)计算如下:
17、
18、其中,c(w,d)表示字符w在当前工艺实体d中出现的次数;dl表示当前工艺实体长度;avgdl表示知识图谱中所有工艺实体的平均长度;k1、b表示可调参数。
19、更优选地,步骤s302中,每个字符的逆文档频率idf(w,b)计算如下:
20、
21、其中,|b|表示整个实体库中所有工艺实体的字符长度总和;c(w,b)表示字符w在整个实体库中出现的次数。
22、更优选地,步骤s303中,每个字符的位置权重因子计算如下:
23、δ=ci
24、其中,δ表示位置权重因子,c表示可调参数,i表示字符在查询q中的位置。
25、更优选地,步骤s304中,非规范实体最终的相似度分数bm25(q,d,b)计算如下:
26、
27、其中,q表示查询,即使用实体识别技术得到的不规范工艺实体;w表示对q进行1-gram切分,得到的单个字符。
28、第二方面,本发明实施例提供了一种基于改进信息检索算法的工艺知识规范化系统,包括:
29、词典模块,基于知识图谱中的规范实体,构建工艺实体同义词词典;
30、数据集模块,基于词典模块构建的工艺实体同义词词典结合工艺问题中非规范实体特点,构建验证数据集;
31、对比模块,基于改进的bm25算法计算验证数据集中不规范实体与词典中规范实体的相似度分数;
32、输出模块,将对比模块得到的候选实体与词典模块构建的工艺实体同义词词典进行映射,获得知识图谱中唯一表示的规范实体,完成工艺知识规范化处理。
33、优选地,对比模块具体为:
34、将不规范实体使用1-gram方法切分,将每个实体切分为单个字符的形式,基于词频计算非规范实体中每个字符与实体库中规范实体的相关性系数,计算单个字符的分数如下:
35、
36、其中,c(w,d)表示字符w在当前工艺实体d中出现的次数;dl表示当前工艺实体长度;avgdl表示知识图谱中所有工艺实体的平均长度;k1、b表示可调参数;
37、计算每个字符的逆文档频率如下:
38、
39、其中,|b|表示整个实体库中所有工艺实体的字符长度总和;c(w,b)表示字符w在整个实体库中出现的次数;
40、计算每个字符的位置权重因子如下:
41、δ=ci
42、其中,δ表示位置权重因子,在计算过程增加了工艺实体位置靠后的字符的权重,c表示可调参数,i表示字符在查询q中的位置;
43、得到非规范实体q中每个字符与对比工艺实体d的相似度分数后,将其累加,获得当前对比工艺实体最终的相似度分数,非规范实体最终的相似度分数计算如下:
44、
45、其中,q表示查询,即使用实体识别技术得到的不规范工艺实体;w表示对q进行1-gram切分得到的单个字符,重复上述计算过程,计算非规范实体q与字典中所有工艺实体的相似度分数,将分数最高的工艺实体作为候选实体。
46、与现有技术相比,本发明至少具有以下有益效果:
47、一种基于改进信息检索算法的工艺知识规范化方法,通过构建工艺实体同义词词典,将不同的指称映射为规范实体,从而确保系统在语义识别和信息检索过程中能够准确理解用户的查询意图,并提供一致和准确的结果,从而解决了工艺实体多样性问题。为了验证算法的有效性,构建了一个包含四种非规范实体错误类型的算法验证数据集,以模拟实际工艺问题中的情况。通过这个数据集,我们可以全面评估不同算法在工艺实体文本相似度匹配任务中的性能。在优化改进过程中,以bm25算法为基础原型,并对其进行改进以提高其在工艺实体文本相似度匹配任务中的性能。通过优化改进后的算法,我们提高了模型的识别精度,并降低了计算成本,使其更适用于机械加工工艺实体的短文本相似度匹配任务。通过这项研究,我们为机械加工领域的工艺实体规范化提供了一种有效的方法,从而提升了系统的性能和可用性;解决当前模型识别误差和人工输入失误导致的非规范实体问题。
48、进一步的,当考虑到不同工艺人员的习惯和输入文本的不可控性时,工艺实体的多样性可能对信息处理产生负面影响。为了消除这种多样性的影响,建立一个同义词词典是必要的,特别是针对那些具有多指称的工艺实体。同义词词典的目标是确保实体的名称一致性,使系统能够将不同的指称映射到同一实体上。通过建立统一的实体命名规范,系统可以提高对工艺实体的识别和理解能力,从而提供更准确、一致的信息检索和处理服务。
49、进一步的,为了验证本方法在机械加工工艺实体规范化任务中的优越性,对同义词词典中的工艺实体进行了进一步处理。通过对工艺实体的字符进行随机替换、删除和增加操作,模拟了实际工艺问题中存在的非规范实体情况。通过这种方式构建的算法验证数据集可以更有效地评估改进的bm25算法在机械加工工艺实体规范化任务中的鲁棒性和准确性。这样的评估将有助于验证方法的有效性,并提供指导改进的方向,以进一步提高系统在处理非规范实体情况时的性能。
50、进一步的,通过对词频调整的改进,bm25算法能够更精确地衡量文档中词条的重要性。相比传统的词频调整方法,bm25考虑了文档长度以及平均文档长度等因素,通过引入可调参数,使得算法能够根据具体情况进行灵活调节,以获得更好的性能。这种灵活性使得bm25算法在不同的信息检索任务中都能发挥出色,提高了检索结果的准确性和可用性。本发明在此基础上,添加了位置权重因子,增加了位置靠后的字符的权重,有效提高了工艺知识规范化的准确率。并基于非规范实体特点,删除了字符与查询的相关性系数。
51、可以理解的是,上述第二方面的有益效果可以参见上述第一方面中的相关描述,在此不再赘述。
52、综上所述,本发明提高了机械加工工艺决策的自动化水平和信息处理效率,通过构建同义词词典,系统能够准确理解工艺实体的不同指称,并将其映射为同一实体,从而提供一致而可靠的知识支持;同时,通过对bm25算法的优化,进一步提高了系统在工艺知识规范化任务中的性能。
53、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!