一种科普领域命名实体识别方法、设备及介质
本技术涉及命名实体识别领域,尤其涉及一种科普领域命名实体识别方法、设备及介质。
背景技术:
1、命名实体识别(named entity recognition,ner)主要用于从非结构化文本数据中自动识别命名实体及其相应类别,通常包括人物、位置和组织等。例如关系提取、知识图谱构建和信息检索等。因此,ner任务在各个领域得到了广泛的研究,例如新闻和社交媒体等。科普领域命名实体识别指从科普文本中识别科普实体的边界并判断科普实体的类别,常见的科普实体类别包括人物、机构和古生物化石等,科普命名实体识别任务是事件抽取和关系抽取等下游任务的基础和关键,为构建科普问答系统、科普知识图谱提供了关键和基础。
2、与使用空格作为分隔符的英语等语言不同,中文存在分词的问题,即中文以词作为语义的基本单位,因此,中文ner仍然面临更大的挑战。引入词汇级特征可以提高科普领域命名实体的识别性能,各个领域的特征并不具有通用性,词汇级特征的选择应该根据具体领域语料的特点进行分析,需要确保所选取的词汇级特征与该领域相符,以提升命名实体识别任务性能。现有的相关技术与专利:
3、中国专利“一种地理学科领域命名实体识别方法,申请号为cn201710422919.3”,该专利公开了一种地理学科领域命名实体识别方法,识别地理学科核心术语类和地理区域位置类实体,主要包括三个步骤:(1)地理学科领域词典构建,采用新词发现算法无监督地识别出地理学科领域新词。(2)基于条件随机场(crf)模型和多通道卷积神经网络(mccnn)模型进行训练与测试。(3)基于规则的方法,纠错和融合模型识别出的实体。该发明采用新词发现算法无监督识别领域新词作为词典,以提高分词效果。从大规模未标注数据中无监督地学习词的语义向量,并综合词的基础特征,作为mccnn模型的输入特征,避免了手动选取和构建特征。
4、中国专利“一种医疗领域中文命名实体识别方法,申请号为cn202210268640.5”,该专利公开了一种医疗领域中文命名实体识别方法,所述方法使用bbcpr模型来识别医疗领域中文命名实体,所述bbcpr模型由单词嵌入层、bert嵌入层、pos融合层、bilstm层和crf层组成,所述单词嵌入层将给定句子转换为词嵌入,输入至bert嵌入层;所述bert嵌入层采用mcbert编码器,得到bert输出嵌入;所述pos融合层将bert输出嵌入和pos嵌入连接起来,得到融合嵌入;bilstm层对融合嵌入进行编码,得到输入序列的最终隐含表示;所述crf层对bilstm层的输出进行解码,得到标签序列并输出。该方法可以明确地学习单词边界信息,同时可以解决过拟合问题并增强模型在小数据上的稳健性。
5、在构建科普知识图谱过程中,命名实体识别是一个关键性的工作,一些现有的命名实体识别方法未针对科普领域命名实体识别面临的长实体、嵌套实体识别率低和中英文混合的问题进行优化,直接应用已有的模型在该领域上性能表现不佳,大大增加了领域知识图谱的构建难度。常规的命名实体识别方法中:中文领域的语料库词汇分布具有差异,未充分考虑这一特征分布,导致在进行中文领域命名实体识别时易产生误差。
技术实现思路
1、为了解决上述问题,本技术提供一种科普领域命名实体识别方法、设备及介质。
2、本技术的上述目的是通过以下技术方案得以实现的:
3、s1:对待识别领域的语料进行预处理,生成领域语料库;
4、s2:对所述领域语料库进行中文分词,得到领域词汇;通过tf-idf算法,计算所述领域词汇的最终权重;根据所述最终权重,确定词频权重序列表示weightinput;
5、s3:对标注实体类型的命名实体训练数据集进行采样并通过数据增强方法进行数据增强,确定模型的文本输入;
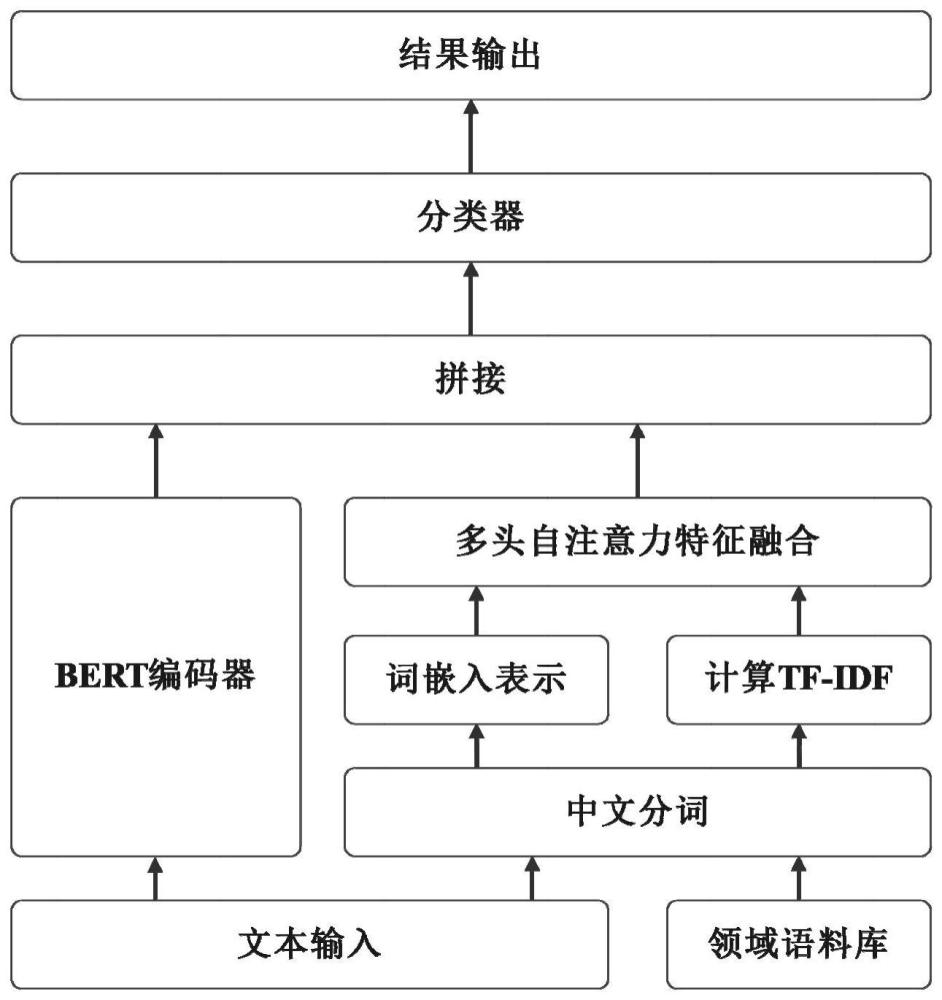
6、s4:对所述文本输入进行中文分词,得到分词表示seginput;将所述分词表示seginput映射为唯一序列表示seg_idsinput以及所述词频权重序列表示weightinput;将所述唯一序列表示seg_idsinput和词频权重序列表示weightinput进行拼接,生成领域特征输入featureinput;
7、使用多头注意力机制,对所述领域特征输入featureinput进行上下文特征融合,输出词汇级特征向量feature;
8、s5:基于mrc任务以及所述文本输入,构造输入input=“<实体类型>,<文本输入>”,将所述输入input输入至bert编码器,得到字符级向量表示embeddinginput;
9、s6:将所述字符级向量表示embeddinginput和所述词汇级特征向量feature进行拼接,得到最终输入final_input;将所述最终输入final_input输入至分类器进行处理,所述分类器的输出即为所述模型的预测输出output;
10、s7:通过损失函数计算所述预测输出output与实际值之间的损失值;根据所述损失值,调整所述模型的参数,直至收敛至预设的目标值;
11、s8:获取待识别文本,通过训练后的模型对所述待识别文本进行命名实体识别。
12、可选的,步骤s1包括:
13、将待识别领域的语料通过分句和拼接,生成n个文档,记为集合corpu;定义n=|corpus|为文档的总数量,使单个文档的字符长度在预定义最大样本长度max_seq_length个字符以内,确定所述领域语料库。
14、可选的,步骤s2包括:
15、s21:所述领域词汇包括多个术语;设术语t的最终权重weightt的计算步骤如下:
16、通过tf-idf算法,计算所述术语t在一个文档中的tf-idf得分wt,d,如下:
17、
18、其中,tft,d表示在文档d中术语t的词频;dft表示n个命名为d的文档中包含术语t的文档个数,为定值;d表示n个文档的命名简称;
19、s22:将所述术语t在第i个命名为d的文档的tf-idf得分,记为i取整数;
20、根据计算所述术语t的最终权重weightt,计算公式如下:
21、
22、s23:所述领域词汇包括多个不同的术语;所述根据各个所述术语的最终权重,确定所述领域词汇的最终权重,从而确定词频权重序列表示weightinput。
23、可选的,步骤s3包括:
24、计算一条当前采样的样本所包含的命名实体类型goldsample和全部预定义命名实体类型all的差集diffsample;
25、对所述差集进行数据增强,具体算法如下:
26、diffsample=all\goldsample
27、
28、其中,表示样本sample命名实体类型为item时,生成的增强数据;\为集合差集运算;
29、记所有的为da,将da与所述领域命名实体识别训练数据集进行合并,得到增强后的领域命名实体识别训练数据集,即所述文本输入;所述模型包括:分类器、bert编码器以及多头注意力机制。
30、可选的,步骤s4包括:
31、s41:对所述模型的输入input进行中文分词处理,并在末尾进行0填充至max_seq_length长度,得到所述模型输入input的分词表示seginput;
32、将所述分词表示seginput映射为唯一序列表示seg_idsinput,具体算法如下:
33、seginput=[input0,a,inputa+1,b,...,inputn+1,m,0,...,0]
34、f(i,j)=[i,repeatjtimes]
35、seg_idsinput
36、=[f(1,a),f{2,b-(a+1)},...,f{k,m-(n+1)},0...,0]
37、其中,inputi,j表示输入input中第i个字符到第j个字符组成的子序列表示,inputi,j表示input0,a,inputa+1,b,...,inputn+1,m;f(i,j)表示元素i重复j次;seg_idsinput为中文词汇边界信息;
38、s42:将所述分词表示seginput映射为所述词频权重序列表示weightinput,算法如下:
39、weightinput
40、=[f(w0,a,a),f{wa+1,b,b-(a+1)},...,f{wn+1,m,m-(n+1)},0,...,0)]
41、
42、其中,wi,j表示inputi,j子序列的领域词频权重,wi,j表示w0,a、wa+1,b、…、wn+1,m;
43、s43:所述拼接的算法,如下:
44、
45、其中,表示拼接函数;
46、s44:使用多头注意力机制,对所述领域特征输入featureinput进行上下文特征融合,计算所述词汇级特征向量feature的步骤如下:根据领域特征输入featureinput,构造查询query,记为q;键key,记为k和值value,记为v,如下:
47、
48、
49、其中,φ(q,k,v)表示注意力机制;softmax表示归一化指数函数;kt表示k的转置矩阵;wo为(h×dv)×dmodel维度的向量;headi=φ(qwiq,kwik,vwiv);wiq为维度为dmodel×dk的向量,wik为维度dmodel×dk的向量,wiv为维度dmodel×dv的向量;h表示多头的数量;dmodel表示输入特征向量的维度;dk表示key最后一维的维度;dv表示value最后一维的维度;mhsa(q,k,v)表示多头自注意力机制;
50、feature=mhsaparams(featureinput)
51、其中,mhsa为多头自注意力机制,params为多头注意力机制的参数。
52、可选的,所述损失函数采用bceloss损失函数。
53、一种电子设备,包括处理器、存储器、用户接口及网络接口,所述存储器用于存储指令,所述用户接口和网络接口用于给其他设备通信,所述处理器用于执行所述存储器中存储的指令,以使所述电子设备执行一种科普领域命名实体识别方法。
54、一种计算机可读存储介质,所述计算机可读存储介质存储有指令,当所述指令被执行时,执行一种科普领域命名实体识别方法。
55、本技术提供的技术方案带来的有益效果是:
56、1.通过对特定领域的语料进行预处理,生成领域语料库,通过中文分词工具对所述领域语料库进行分词,得到领域词汇,不再需要进行人工构造特征词典。依赖于领域语料中的中文分词结果和领域词汇的最终权重特征,在命名实体识别任务中融入了中文词汇的特征,提升了模型识别科普领域命名实体的性能。通过具有一定的泛化性的数据增强方法对注领域的命名实体识别训练数据集进行数据增强处理,缓解了训练与预测任务之间的差异和科普领域长实体、嵌套实体识别率低的问题。基于领域语料库,计算领域词汇的词频权重特征。由于中文词汇不具备天然的分界符,一般情况下词汇的开始或结束位置即为实体的边界,基于中文分词,在命名实体识别任务中融入中文词汇边界信息seg_idsinput和词汇权重特征weightinput,有效地解决了实体边界错误提取的问题,提高科普领域命名实体识别的准确率,从而提升了模型的整体性能。结合计算机阅读理解任务(mrc)将命名实体识别任务转换成下一句预测任务,缓解了下游任务与预训练任务之间的差异。指针标注任务将多分类任务转化为二分类任务,相比较与序列标注任务,该模型能更加有效地识别科普领域的长实,减少了长实体识别断裂现象;同时结合mrc任务能有效地识别科普领域的嵌套实体。
57、2.bceloss损失函数用于二分类任务,指针标注任务解决了常规的序列标注类模型一般是多分类任务,不能直接使用bceloss损失函数的问题。
- 还没有人留言评论。精彩留言会获得点赞!