一种基于相关性分析的抗共谋联邦学习优化方法
本发明属于联邦学习隐私保护领域,具体涉及一种基于相关性分析的抗共谋联邦学习优化方案方法。
背景技术:
1、随着人们对数据隐私的日益关注,联邦学习(fl)作为一种强大而安全的分布式机器学习范式,正在物联网(iot)中广泛使用。它被制定为多个节点之间的多轮模型训练策略。fl系统,包括一个中央服务器与多个本地客户端,共同维护全局模型,通过在服务器与本地客户端间传递模型梯度来更新模型而无需共享其私有数据集。
2、为了破坏联邦学习的隐私保护性,过去几年涌现出许多隐私攻击手段,例如2021年提出的搭便车攻击。这种类型的攻击允许fr对手上传伪造更新而获得服务器下发的正常更新,从训练有素的全局模型中受益,而无需贡献自己的私有数据集和计算资源。
3、为了对抗搭便车攻击,研究人员提出了许多应对方法,大体上可以分为三类:
4、基于更新统计:通过全局更新和局部更新之间的相似度来计算客户端的贡献。典型的代表为xu等人提出的rffl框架。该方法在搭便车攻击者比例过高(例如比例超过40%)时,会将公平客户端错误地分类为搭便车对手,并导致更高的误报率。
5、基于聚集中和:对离群值不敏感的运算符进行聚合,例如依靠中位数。该方法的缺点是仅适用于搭便车攻击者占总体客户端的比例较低的场景,一旦搭便车攻击者比例过高(例如比例超过50%),诚实客户端的更新反而被识别为异类并被独立聚合。且该方法没有删除搭便车攻击者,而仅仅是容忍攻击者带来的负面影响。
6、基于模型度量:依靠本地模型和本地数据集来进行验证。这种方法需要一个验证数据集。典型例子为jianhua wang等人提出的pass框架。该方法面对基于搭便车改进的共谋攻击时失去作用,并且在客户端数量较多且数据分布为non-iid时性能表现不佳。
7、从以上的分析可以看出,抗搭便车的三类主要方式均有着严重的缺陷。在搭便车攻击者数量较多的场景下抵抗该攻击甚至是更进一步的共谋攻击的同时保证良好的性能,依然是一个迫切需要解决的问题。
技术实现思路
1、本发明根据现有技术的不足,改良了搭便车攻击,提出了共谋攻击。该攻击可以使得基于模型度量的方法失效,并且在攻击者数量比例较多时使得基于更新统计和聚集中和的方法失效。可以攻破市面上主流的抗搭便车攻击方法。针对共谋攻击,使用分组审计与相似性分析技术,成功保护隐私数据。同时针对本发明提出的共谋攻击,提供一种基于相关性分析的抗共谋联邦学习优化方法(flca),能成功筛选出联邦学习中的共谋攻击者。在攻击者比例较高且数据non-iid(非独立分同分布)的场景下依然能发挥不错的性能。
2、本发明包括以下步骤:
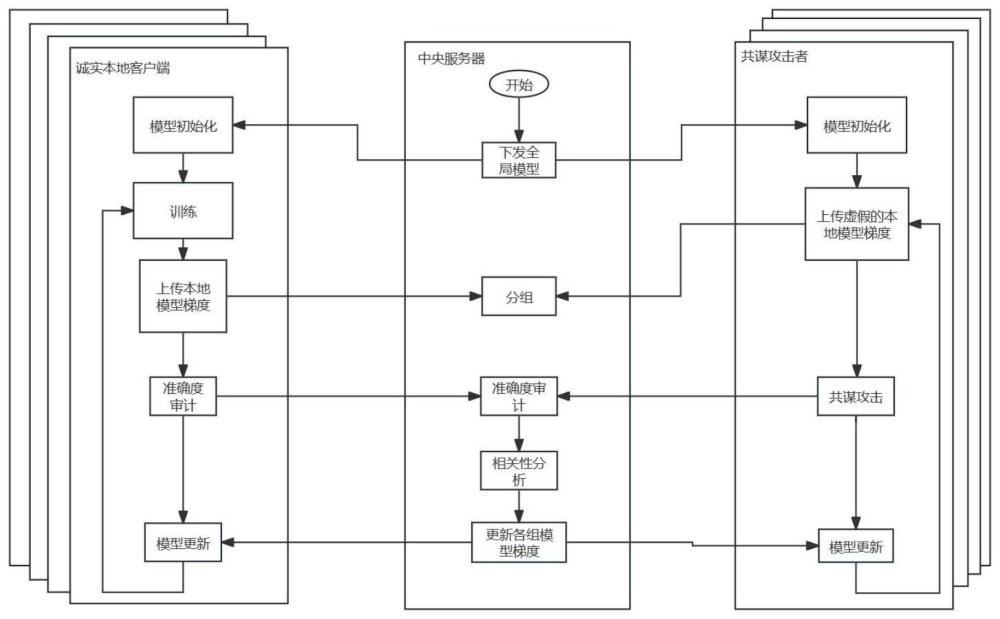
3、s1:建立一个基于中心化架构的联邦学习训练系统;所述基于中心化架构的联邦学习训练系统,由两类节点组成,分别是中央服务器和本地客户端;本地客户端又分为两类:诚实客户端与共谋攻击者;中央服务器与本地客户端均采用多进程工作方式;中央服务器进程根据功能分为六类:
4、通信进程:设有多个,数量与本地客户端节点数量相等,用于维护与各本地客户端节点之间的本地模型梯度与审计结果通信;
5、梯度聚合进程:设有一个,用于聚合各个本地客户端节点向中央服务器节点发送过来的本地模型梯度,处理全局模型梯度的更新;
6、分组进程:设有一个,根据本地客户端向中央服务器发送的本地模型梯度的相似性进行分组;
7、相关性分析进程:设有一个,根据每个审计结果变化进行相关性分析,并由此控制本地客户端的筛选;
8、准确度管理进程:设有一个,管理本地客户端的打分;
9、筛选管理进程:设有一个,根据相关性分析的结果筛选本地客户端,被选择的本地客户端继续加入系统,其它本地客户端不可继续加入联邦学习训练系统。
10、本地客户端进程根据功能可分为三类:
11、通信进程:设有多个,数量与本地客户端节点数量相等,用于维护与各本地客户端节点之间的本地模型梯度通信;
12、训练进程:利用全局模型梯度进行本地模型的训练;
13、准确度审计进程:设有一个,对其他本地客户端进行准确度审计打分;
14、联邦学习初始化客户端共n个,分组数量为m个。
15、s2:随机选择n个本地客户端成为共谋攻击者,其它本地客户端为诚实客户端。初始的中央服务器筛选管理进程选择所有本地客户端加入联邦学习训练系统,并被划分为一组,接受中央服务器下发的初始全局模型。
16、s3:所有本地客户端根据初始全局模型进行训练,并向中央服务器上传训练的模型梯度,中央服务器利用高斯噪音加密客户端上传的模型梯度。
17、如果是第一轮训练,则所有本地客户端接受中央服务器下发的全局模型进行训练;诚实本地客户端使用全局模型进行迭代训练,并向中央服务器上传训练后的本地模型梯度;共谋攻击者则不进行训练,向中央服务器上传编造的随机梯度数据。
18、如果不是迭代的第一轮,则未被筛选出系统的本地客户端接受中央服务器下发的全局模型梯度进行训练,各本地客户端计算模型准确度:中央服务器将加密后的梯度下发给各个客户端,每个客户端利用全局模型和收到的梯度在自己的本地隐私数据集计算模型准确度,并将准确度结果上传给中央服务器。
19、s4:中央服务器根据本地客户端上传的模型梯度进行分组,按组计算本地模型梯度平均数,并将本地模型梯度平均数作为该组的新全局模型梯度。
20、若不是迭代的第一轮,则将s3得到的准确度按组进行相关性分析,相关性得分低于阈值的组内所有本地客户端认定为共谋者,被筛选出联邦学习训练系统。
21、s5:诚实客户端使用新的全局模型梯度进行下一次迭代训练;共谋攻击者则不进行任何训练。
22、s6:重复步骤s3至s5,直至完成预定迭代轮数。
23、与现有的技术相比,本发明的优势在于:
24、1.第一个提出同时抵御fr攻击和共谋攻击的联邦学习优化方案。
25、2.在大规模本地客户端的场景下依然能保证较高的精度。
26、3.在大规模深度神经网络上评估了优化方案,并在本地客户端规模大、共谋攻击者比例较高的场景下,联邦学习系统依然维持了较高的准确度。
技术特征:
1.一种基于相关性分析的抗共谋联邦学习优化方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于相关性分析的抗共谋联邦学习优化方法,其特征在于,步骤s1中所述中央服务器与本地客户端均采用多进程工作方式;联邦学习初始化本地客户端共n个,分组数量为m个;
3.根据权利要求2所述的基于相关性分析的抗共谋联邦学习优化方法,其特征在于,步骤s3具体操作如下:
4.根据权利要求3所述的基于相关性分析的抗共谋联邦学习优化方法,其特征在于,所述本地客户端计算模型准确度具体为:中央服务器将加密后的梯度下发给各个客户端,每个客户端利用全局模型和收到的梯度在本地隐私数据集计算模型准确度,并将准确度结果上传给中央服务器。
5.根据权利要求4所述的基于相关性分析的抗共谋联邦学习优化方法,其特征在于,步骤s4还包括:若不是迭代的第一轮,则将s3得到的准确度按组进行相关性分析,相关性得分低于阈值的组内所有本地客户端认定为共谋者,被筛选出联邦学习训练系统。
技术总结
本发明公开了一种基于相关性分析的抗共谋联邦学习优化方法,该方法首先建立基于中心化架构的联邦学习训练系统。其次随机选择n个本地客户端为共谋攻击者,其它为诚实客户端,所有本地客户端加入训练系统,并被划分为一组,接受中央服务器下发的初始全局模型。然后所有本地客户端根据初始全局模型进行训练,并向中央服务器上传训练的模型梯度,中央服务器根据上传的模型梯度进行分组,按组计算梯度平均数,作为该组的新全局模型梯度。最后诚实客户端使用新的全局模型梯度进行下一次迭代训练;共谋攻击者则不进行任何训练。本发明能同时抵御FR攻击和共谋攻击,在大规模客户端的场景下依然能保证较高的精度。
技术研发人员:钟豪,薛梅婷,曾艳,张纪林,赵乃良,黄成创
受保护的技术使用者:杭州电子科技大学
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!