基于自适应联合时空图卷积的虚拟现实交互方法及系统
本发明属于虚拟现实交互,尤其涉及基于自适应联合时空图卷积的虚拟现实交互方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、虚拟现实技术利用电脑模拟产生一个三维空间的虚拟世界,提供用户关于视觉等感官的模拟。随着人工智能技术的发展,虚拟现实设备可以通过人工神经网络实时感知人类意图,实现人与虚拟世界的交互行为。
3、当前人类与虚拟现实技术交互通常需要使用手部辅助设备感知人体姿态。随着计算机计算水平的提高,外部设备也被应用与感知人体姿态,例如传感器和摄像头。与使用辅助设备相比,减少了外部设备的使用增加了用户对虚拟现实技术的沉浸感。
4、但目前基于摄像头进行虚拟现实与人类交互的方法还面临一些挑战。与传感器和外部设备相比,摄像头更加容易部署且成本较低,但识别能力和识别精度相对较低。人体骨架数据相对于单纯图像更能体现人体姿态的细节,并且对周围环境具有天然的鲁棒性。
5、现有的基于图卷积神经网络的骨架人体动作识别方法利用骨架的结构特性,将骨架构建为图数据结构,通过图卷积神经网络提取聚合相邻关节点之间的特征,获取人类动作。当前基于图神经卷积网络的骨架人体动作识别方法分开提取骨架时空关系,这忽略了跨时空关系导致部分动作难以被区别。此外,现有方法由于网络层数过深导致实时性较差,难以应用于现实场景。
技术实现思路
1、为了解决上述背景技术中存在的至少一项技术问题,本发明提供基于自适应联合时空图卷积的虚拟现实交互方法及系统,其使用rgb摄像头作为感知源,通过骨架估计算法实时提取人体骨架,提出了一种自适应图机制,替换原有骨架图,使得骨架图可以跟网络参数一同优化,提升了全局准确率,提出了一种跨时空的联合图卷积方法,跨时空聚合节点信息,提升识别准确率并降低网络参数量使实时化可行。
2、为了实现上述目的,本发明采用如下技术方案:
3、本发明的第一个方面提供基于自适应联合时空图卷积的虚拟现实交互方法,包括如下步骤:
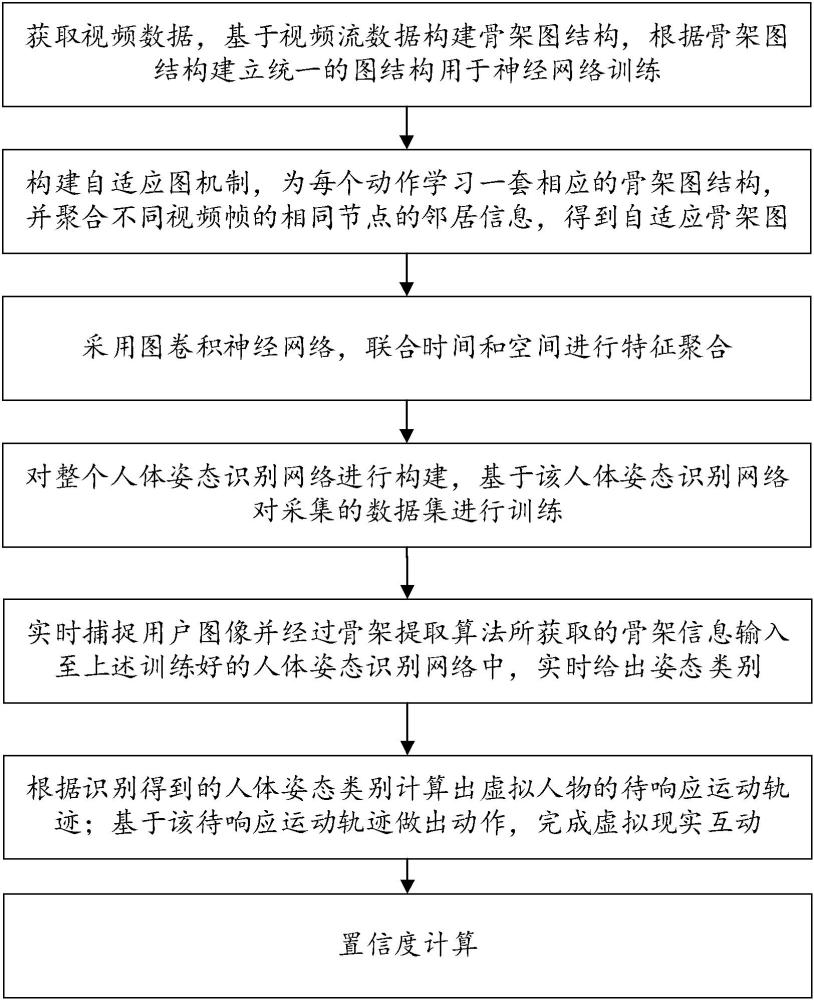
4、根据获取的视频流数据构建人体骨架图结构;
5、基于人体骨架图结构和训练后的人体姿态识别网络得到人体姿态类别;其中,所述人体姿态识别网络的构建过程包括:
6、结合人体骨架图结构,构建自适应图机制,为每个动作学习一套相应的骨架图结构,并聚合不同视频帧的相同节点的邻居信息,得到自适应骨架图;
7、基于自适应骨架图,采用图卷积神经网络对时间和空间维度特征联合聚合,得到时空联合聚合表示,根据时空联合聚合表示识别得到人体姿态类别;
8、根据识别得到的人体姿态类别计算出虚拟人物的待响应运动轨迹,基于该待响应运动轨迹做出动作,完成虚拟现实互动。
9、进一步地,所述根据获取的视频流数据构建人体骨架图结构,包括:
10、将人体的骨架表示为图数据结构,其中顶点集表示人体骨骼中的每个关节点,是骨骼图中所有关节点的数目,边集表示关节点之间的骨骼,骨骼图的邻接矩阵的计算公式为:如果节点和节点之间存在链接,则,否则为0。
11、进一步地,所述结合人体骨架图结构,构建自适应图机制,为每个动作学习一套相应的骨架图结构,并聚合不同视频帧的相同节点的邻居信息,得到自适应时空骨架图,包括:
12、根据每个动作的人体骨架图结构,建立关节点之间的额外链接,得到第一矩阵;
13、学习每个动作视频流数据相应的人体骨架图结构,衡量任意两个节点之间是否存在链接以及对应的链接强度,得到第二矩阵;
14、结合人体骨架图结构邻接矩阵、第一矩阵和第二矩阵得到自适应的时空骨架图的邻接矩阵。
15、进一步地,所述衡量任意两个节点之间是否存在链接以及对应的链接强度采用归一化的高斯函数衡量。
16、进一步地,所述图卷积神经网络的构建过程为:
17、获取所有帧自适应骨架图的邻接矩阵;
18、将自适应骨架图应用于自适应骨架图的邻接矩阵中,得到自适应的时空骨架图的邻接矩阵;
19、基于自适应的时空骨架图的邻接矩阵构建自适应学习时空图,选择性地聚合𝜏帧内的连接邻域,得到时间窗口的自适应联合图卷积。
20、进一步地,所述采用图卷积神经网络对时间和空间维度特征联合聚合时,具体包括:每个图卷积神经网络包括多个自适应时空联合图卷积块,每个自适应时空联合图卷积块包括一个自适应时空联合图卷积网络和一个时间卷积网络,通过自适应时空联合图卷积网络提取时空联合特征,随后输入时间卷积网络,对时间层面的特征进一步提取,得到最后的聚合特征向量。
21、进一步地,在得到人体姿态类别后,进行置信度计算,计算方法为:
22、,其中,xi是人体骨架数据经过神经网络计算所获得的类别向量,是类别总数,是xi预测类别下标的值。
23、本发明的第二个方面提供基于自适应联合时空图卷积的虚拟现实交互系统,包括姿态识别端和虚拟现实端;
24、所述姿态识别端,被配置为:根据获取的视频流数据构建人体骨架图结构;基于人体骨架图结构和训练后的人体姿态识别网络得到姿态类别;其中,所述人体姿态识别网络的构建过程包括:
25、结合人体骨架图结构,构建自适应图机制,为每个动作学习一套相应的骨架图结构,并聚合不同视频帧的相同节点的邻居信息,得到自适应骨架图;
26、基于自适应骨架图,采用图卷积神经网络对时间和空间维度特征联合聚合,得到时空联合聚合表示,根据时空联合聚合表示识别得到人体姿态类别;
27、所述虚拟现实端,被配置为:根据识别得到的人体姿态类别计算出虚拟人物的待响应运动轨迹;基于该待响应运动轨迹做出动作,完成虚拟现实互动。
28、进一步地,所述姿态识别端,还被配置为:所述结合人体骨架图结构,构建自适应图机制,为每个动作学习一套相应的骨架图结构,并聚合不同视频帧的相同节点的邻居信息,得到自适应时空骨架图,包括:
29、根据每个动作的人体骨架图结构,建立关节点之间的额外链接,得到第一矩阵;
30、学习每个动作视频流数据相应的人体骨架图结构,衡量任意两个节点之间是否存在链接以及对应的链接强度,得到第二矩阵;
31、结合人体骨架图结构邻接矩阵、第一矩阵和第二矩阵得到自适应的时空骨架图的邻接矩阵。
32、进一步地,所述姿态识别端,还被配置为:在得到人体姿态类别后,进行置信度计算。
33、与现有技术相比,本发明的有益效果是:
34、(1)针对现有方法使用大多使用外部设备和传感器的局限性,本发明使用rgb摄像头作为感知源,通过骨架估计算法实时提取人体骨架。
35、(2)针对现有基于图卷积神经网络的骨架人体动作识别方法部分动作难以被识别的问题,本发明提出了一种自适应图机制,替换原有骨架图,使得骨架图可以跟网络参数一同优化,提升了全局准确率。
36、(3)针对现有方法层数过深导致实时性较差难以部署至真实场景下的缺点,本发明提出了一种跨时空的联合图卷积方法,跨时空聚合节点信息,提升识别准确率并降低网络参数量使实时化可行。
- 还没有人留言评论。精彩留言会获得点赞!