一种增强rediscluster服务可靠性的方法与流程
本发明属于互联网,尤其涉及一种增强redis cluster服务可靠性的方法。
背景技术:
1、缓存中间件是一种在分布式系统中使用的中间件,用于提高数据访问速度和可靠性。它通常将数据缓存在内存中,以便快速地访问数据,从而减轻数据库或其他上游组件的负担。缓存中间件还可以提高系统的可伸缩性,因为它可以在需要时增加或减少缓存的大小,以适应系统的需求。常见的缓存中间件有redis。而redis cluster是redis的分布式解决方案,旨在解决redis的单点故障和性能问题,通过将数据存储在多个节点上来提高可用性和性能,具备高性能、可拓展、高可用等能力,与redis相比,redis cluster提供了更多的功能和更好的性能,适用于需要高可用性、高性能和分布式存储的场景。
2、传统的分布式集群redis cluster本身具备一定的高可用机制,但是存在一些高可用场景下无法做到自动恢复:场景1:集群中超过半数以上的master节点同时宕掉,集群无法自动恢复;场景2:相同槽段的master和slave同时宕掉,客户端无法读写该槽段数据,集群无法自动恢复;场景3:redis节点宕掉后,集群无法自动拉起该节点;场景4:集群中master同时宕掉,手动启动半数以上的master,集群仍无法对外提供读写服务;此外无法自动恢复的场景也可能不仅仅限于此。
技术实现思路
1、本发明所要解决的技术问题是针对背景技术的不足提供一种增强redis cluster服务可靠性的方法及装置,通过access机制收集、分析集群中各个节点的状态,在不干扰集群自身高可用恢复机制的情况下,解决集群在一些高可用场景下无法做到自动恢复的问题,进一步增强redis cluster的服务可靠性,保障redis cluster在各种异常下的自动恢复,提升服务的可靠性。
2、本发明为解决上述技术问题采用以下技术方案:
3、一种增强redis cluster服务可靠性的方法,具体包含如下步骤;
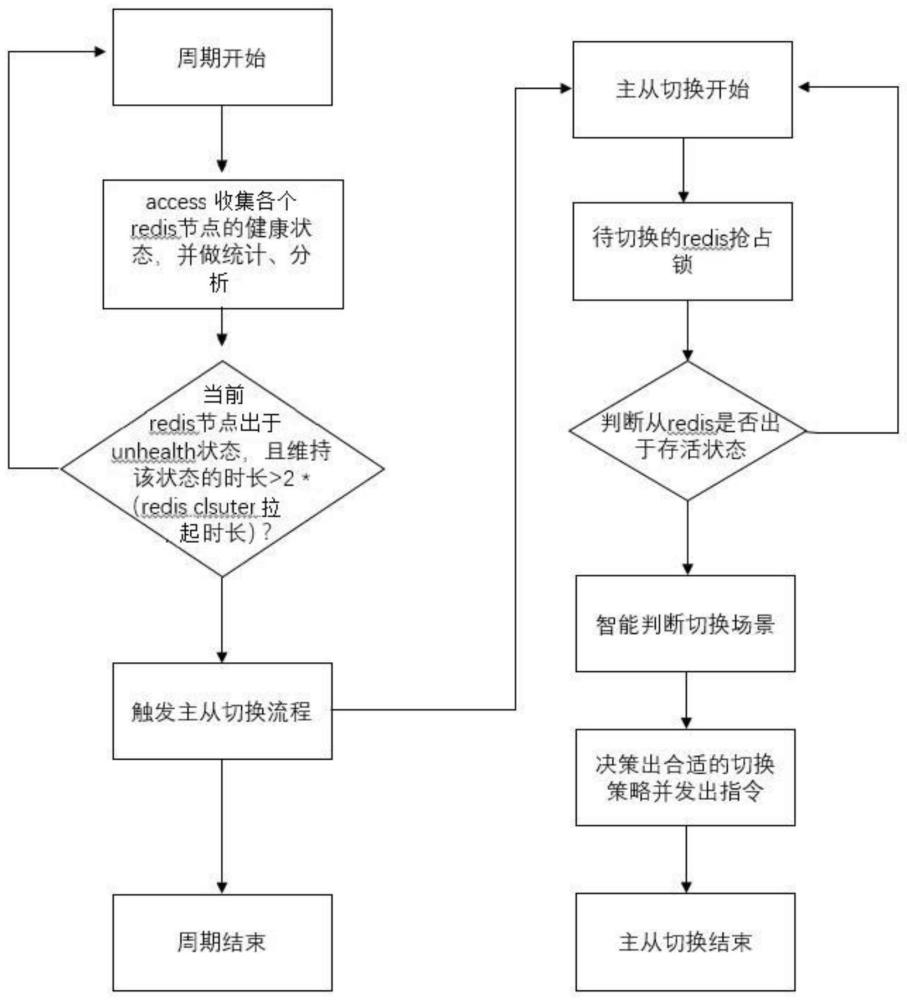
4、步骤1,利用主access机制定期监听、收集、分析集群中各个节点健康状态;
5、步骤2,access机制会记录节点的状态数据,上报监控中心,触发监控告警,及时维护集群的监控状态。
6、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,在步骤1中,所述主access通过zookeeper选主机制产生;其中access为接入机。
7、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,在步骤1中,定期监听、收集、分析集群中各个节点健康状态,当分析发现存在集群无法自动恢复的场景时,此时access会介入,判断异常场景,并将集群恢复到正常状态。
8、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,所述异常场景包含:access分析主节点未宕机,且判断正常master主节点超过一半,在对应的从节点执行cluster failover待数据同步并且投票;cluster failover为实例支持的开源命令,用于从节点执行后会等待数据同步并且投票。
9、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,所述异常场景包含:access分析主节点主节点未宕机,且判断正常master节点数少于一半,在对应的从节点执行cluster failover takeover无需投票。
10、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,所述异常场景包含:access分析主节点已宕机,且判断正常master节点数超过一半,在对应的从节点执行cluster failover force不用等待数据同步。
11、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,所述异常场景包含:access分析主节点已宕机,且判断正常master节点数少于一半,在对应的从节点执行cluster failover takeover。
12、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,在步骤2中,节点的状态数据包含内存。
13、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,在步骤2中,节点的状态数据包含连接数。
14、作为本发明增强redis cluster服务可靠性的方法的进一步优选方案,在步骤2中,当节点的状态数据超过预设定的阈值,触发监控告警。
15、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
16、本发明过access机制收集、分析集群中各个节点的状态,在不干扰集群自身高可用恢复机制的情况下,解决集群在一些高可用场景下无法做到自动恢复的问题,进一步增强redis cluster的服务可靠性,保障redis cluster在各种异常下的自动恢复,提升服务的可靠性。
技术特征:
1.一种增强redis cluster服务可靠性的方法,其特征在于:具体包含如下步骤;
2.根据权利要求1所述的增强redis cluster服务可靠性的方法,其特征在于:在步骤1中,所述主access通过zookeeper选主机制产生,其中access为接入机。
3.根据权利要求1所述的增强redis cluster服务可靠性的方法,其特征在于:在步骤1中,定期监听、收集、分析集群中各个节点健康状态,当分析发现存在集群无法自动恢复的场景时,此时access会介入,判断异常场景,并将集群恢复到正常状态。
4.根据权利要求3所述的增强redis cluster服务可靠性的方法,其特征在于:所述异常场景包含:access分析主节点未宕机,且判断正常master主节点超过一半,在对应的从节点执行cluster failover待数据同步并且投票;cluster failover为实例支持的开源命令,用于从节点执行后会等待数据同步并且投票。
5.根据权利要求3所述的增强redis cluster服务可靠性的方法,其特征在于:所述异常场景包含:access分析主节点主节点未宕机,且判断正常master节点数少于一半,在对应的从节点执行cluster failover takeover无需投票。
6.根据权利要求3所述的增强redis cluster服务可靠性的方法,其特征在于:所述异常场景包含:access分析主节点已宕机,且判断正常master节点数超过一半,在对应的从节点执行cluster failover force不用等待数据同步。
7.根据权利要求3所述的增强redis cluster服务可靠性的方法,其特征在于:所述异常场景包含:access分析主节点已宕机,且判断正常master节点数少于一半,在对应的从节点执行cluster failover takeover。
8.根据权利要求3所述的增强redis cluster服务可靠性的方法,其特征在于:在步骤2中,节点的状态数据包含内存。
9.根据权利要求1所述的增强redis cluster服务可靠性的方法,其特征在于:在步骤2中,节点的状态数据包含连接数。
10.根据权利要求1所述的增强redis cluster服务可靠性的方法,其特征在于:在步骤2中,当节点的状态数据超过预设定的阈值,触发监控告警。
技术总结
本发明公开了一种增强Redis cluster服务可靠性的方法,涉及互联网技术领域,具体包含如下步骤;利用主access机制定期监听、收集、分析集群中各个节点健康状态;access机制会记录节点的状态数据,上报监控中心,触发监控告警,及时维护集群的监控状态。通过access机制收集、分析集群中各个节点的状态,在不干扰集群自身高可用恢复机制的情况下,解决集群在一些高可用场景下无法做到自动恢复的问题,进一步增强redis cluster的服务可靠性,保障redis cluster在各种异常下的自动恢复,提升服务的可靠性。
技术研发人员:吴小文,毛刘刚,张国豪,陈国锐,石方波,冯伟佳
受保护的技术使用者:天翼云科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!