一种云原生监控Prometheus智能分片提高资源利用率的方法与流程
本发明属于存储,尤其涉及一种云原生监控prometheus智能分片提高资源利用率的方法。
背景技术:
1、在云原生监控prometheus监控指标采集过程中,单个prometheus能够采集的监控指标数量是有限的。多个prometheus配合去采集大规模的监控指标就涉及到监控指标如何进行分片,同时每个prometheus所在的机器的cpu、磁盘io性能是有差别的,如果进行平均分配就会导致性能好的机器上的prometheus会浪费资源此时需要一种可以解决上述问题。本发明为基于云原生监控prometheus实现自动分片、根据分片的负载高低自动迁移分片到性能好的分片去采集更多的指标、分片的自动扩缩容,能力和特性包括:
2、1.prometheus根据机器性能计算分片采集能力并给分片填充要采集的监控指标;
3、2.prometheus分片自动扩缩容。
4、目前prometheus分片的实现方式有kubernetes种基于服务发现的方式、开源项目kvass进行平均分配的方式,对应问题如下:
5、不同节点的cpu、磁盘io性能是不一致的,会导致性能好的机器上的分片prometheus资源浪费。
技术实现思路
1、本发明所要解决的技术问题是针对背景技术的不足提供本一种云原生监控prometheus智能分片提高资源利用率的方法,在云原生监控prometheus监控指标采集过程中,单个prometheus能够采集的监控指标数量是有限的;多个prometheus配合去采集大规模的监控指标就涉及到监控指标如何进行分片,同时每个prometheus所在的机器的cpu、磁盘io性能是有差别的,如果进行平均分配就会导致性能好的机器上的prometheus会浪费资源,同时解决了分片自动迁移、分片自动扩缩容等功能。
2、本发明为解决上述技术问题采用以下技术方案:
3、一种云原生监控prometheus智能分片提高资源利用率的方法,基于云原生监prometheus实现自动分片、根据分片的负载高低自动迁移分片到性能好的分片去采集更多的指标、分片的自动扩缩容,具体包含如下步骤;
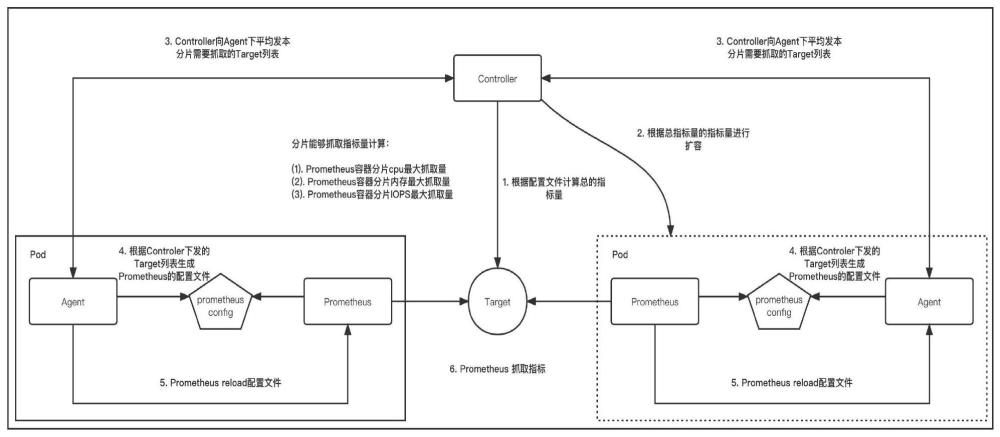
4、步骤1,云原生监控prometheus初始化;
5、步骤2,云原生监控prometheus根据机器性能自动给分片填充监控指标;
6、步骤2,云原生监控prometheus对分片进行自动扩缩容。
7、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,所述云原生监控prometheus具体包含agent组件、controller组件和prometheus组件。
8、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,云原生监控prometheus初始化具体如下:
9、步骤1.1,controller组件根据配置文件获取总的要抓取的监控指标数量;
10、步骤1.2,controller组件根据总指标量以及分片的初始抓取指标量来扩容出足够数量的分片;
11、步骤1.3,controller组件初始将分片平均分配给每个分片然后将每个分片的target列表下发到每个分片的agent组件;
12、步骤1.4,agent组件根据接收到的target列表生成对应的prometheus配置文件,同时通知prometheus热更新配置文件,然后prometheus根据配置文件抓取监控指标。
13、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,在步骤2中,计算分片并下发采集任务,具体如下:
14、步骤2.1,agent组件采集当前分片的cpu、内存、iops这三个监控指标,定时向controller组件上报;
15、步骤2.2,controller组件根据各个分片的指标并依据计算公式进行计算出分片的指标采集数量,根据计算公式算出分片抓取的指标量后向其下发要采集的监控指标集,将不同性能机器上的prometheus分片分配了匹配对应硬件性能的监控指标采集数量。
16、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,在步骤2中,分片抓取能力计算公式包含内存抓取指标数计算公式、iops抓取指标数计算公式和iops抓取指标数计算公式。
17、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,内存抓取指标数计算公式,具体如下:
18、当前分片监控指标平均字节数量=当前分片总的监控指标的总的字节数/当前分片总的监控当前分片内存能抓取的总指标数=当前分片总内存/当前分片平均字节数量。
19、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,iops抓取指标数计算公式,具体如下:
20、当前分片iops能抓取的总指标数=(当前分片iops目前负载因子/当前分片iops目前抓取的数量)*分配给分片总的iops负载因子。
21、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,cpu抓取指标数计算公式:
22、当前分片cpu能抓取的总指标数=(当前分片cpu目前负载因子/当前分片cpu目前抓取的数量)*分配给分片总的cpu负载因子。
23、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,当前分片能够抓取的指标数=min(当前分片内存能抓取的总指标数,当前分片iops能抓取的总指标数,当前分片cpu能抓取的总指标数)。
24、作为本发明一种云原生监控prometheus智能分片提高资源利用率的方法的进一步优选方案,在步骤3中,对分片进行自动扩缩容,具体如下:
25、步骤3.1,agent组件采集当前分片的cpu、内存、iops这三个监控指标,定时向controller组件上报;
26、步骤3.2,controller组件根据各个分片的指标通过计算公式计算出每个分片的指标抓取数量;
27、步骤3.3,controller组件根据每个分片的能够抓取的监控指标数量,发现有比较空闲的分片可以全部迁移到高性能的分片,则将target迁移到高性能的分片上同时将老的分片缩容。
28、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
29、1、本发明prometheus分片抓取的指标是根据分片所在机器的硬件资源通过公式计算出来的,可以显著提升资源利用率;
30、2、本发明prometheus分片可以根据总的监控指标数量进行动态的自动扩缩容;
31、3、本发明将监控分片的iops、cpu等指标进行抽象,然后就可以根据抽象后的指标来通过数量来衡量分片的抓取能力;
32、4、现有系统底层的机器肯定是不同型号不同品牌,因此对应的性能也是有差异的,通过这种性能抽象将硬件资源的能力最大挖掘出来,降低基础架构部门的资源开销,为公司节省成本。
- 还没有人留言评论。精彩留言会获得点赞!