一种打架识别方法、系统及其存储介质与流程
本发明涉及安全预警,具体为一种打架识别方法、系统及其存储介质。
背景技术:
1、打架斗殴作为一种扰乱社会公共秩序的不良行为,目前主要依赖于人工监控,但是人工监控存在漏看和误判的风险,不仅效率低而且人工成本高。随着人工智能技术的发展,使智能监控代替人工监控成为可能。
2、目前的打架行为识别方法主要有以下两种:
3、1.通过使用目标检测方法把监控视频中的行人进行检测,然后对每个行人的动作行为进行分析,从而判断监控视频中是否存在打架行为,由于打架行为是多人的互动行为,该种方法只对单个行人进行独立分析,误判率高。
4、2.通过把整个监控视频作为输入,送进三维卷积神经网络进行分析,判断监控视频是否存在打架行为。该种方法对整个视频进行全面分析,有助于全面分析行人之间的互动;但是,对整个监控画面进行分析,模型的计算量大,对硬件设备要求高,而且,行人占监控画面的区域较小,对模型分析结果的影响比重也较小,识别的准确率不高。
5、归纳可知,现有的打架识别方法存在误判率高、计算量大、对硬件要求高等痛点。
技术实现思路
1、为了解决上述问题,本发明提供了一种打架识别方法。
2、本发明采用以下技术方案,一种打架识别方法,包括以下步骤:
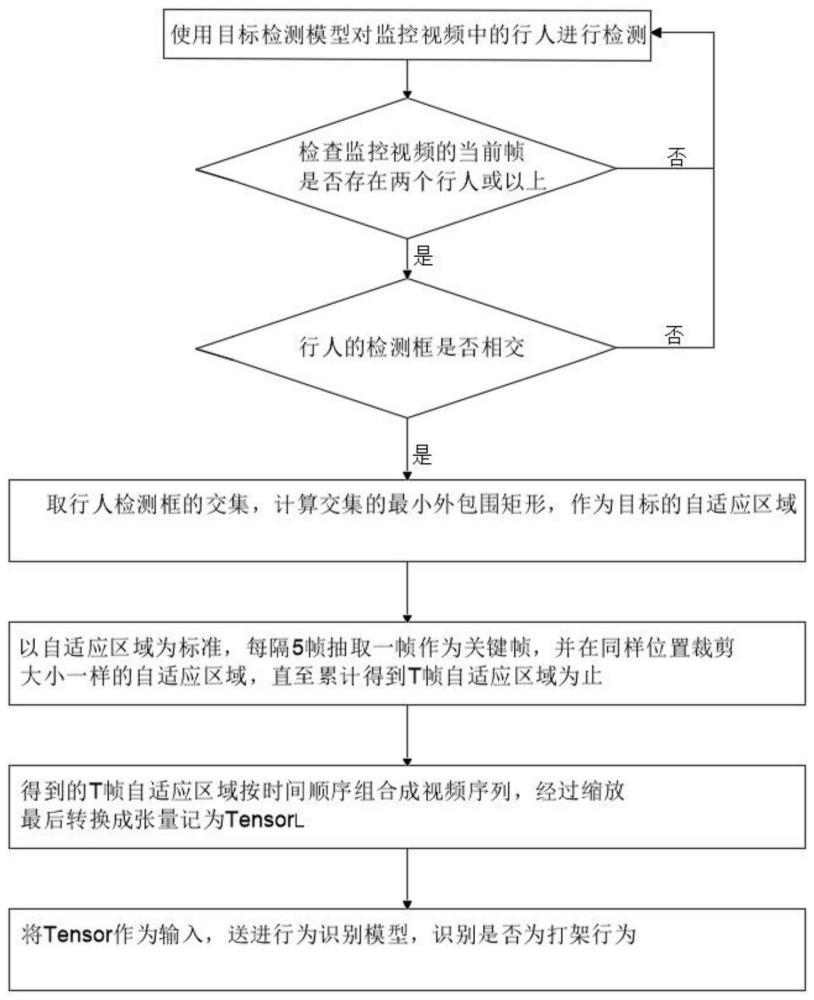
3、步骤so1:使用目标检测模型对监控视频中的行人进行检测;
4、步骤so2:检查监控视频的当前帧是否存在两个行人或以上,若是,则进入步骤s03,否则返回步骤s01;
5、步骤s03:检查行人的检测框是否相交,若是,则进入步骤4,否则返回步骤s01;
6、步骤s04:取行人检测框的交集,计算交集的最小外包围矩形,作为目标的自适应区域;
7、步骤s05:以步骤s04中的自适应区域为标准,每隔5帧抽取一帧作为关键帧,并在同样位置裁剪大小一样的自适应区域,直至累计得到t帧自适应区域为止;
8、步骤s06:对步骤s05中得到的t帧自适应区域按时间顺序组合成视频序列,经过缩放,最后转换成张量,记为tensor;
9、步骤s07:把步骤s06中的tensor作为输入,送进行为识别模型,识别是否为打架行为。
10、作为上述技术方案的进一步描述:所述张量转化公式为:
11、
12、tensor∈rt×c×h×w;
13、t为输入的帧数,c为通道数(通常为3,rgb),h,w分别为高和宽。f(t,c,h,w)为第t帧,第c通道,高为i,宽为j的像素值;
14、其中:f(t,c,i,j)∈[0,255];
15、tensor(t,c,i,j)∈[-1.0,1.0]。
16、作为上述技术方案的进一步描述:所述目标检测模型为轻量化的yolov5s模型,并基于coco数据集的预训练权重进行训练,使模型具备行人检测的能力,其中,输入图片大小为640×640。
17、作为上述技术方案的进一步描述:所述行为识别模型采用slowfast-r50,采用kinetics数据集的预训练权重,经过对监控视频数据集训练至收敛,具备识别打架行为的能力。
18、作为上述技术方案的进一步描述,所述目标检测模型的训练方法包括以下步骤:
19、步骤t1:获取真实场景的视频数据流,并抽帧成图片,对每帧图片中的行人进行画框标注,记为行人目标框,并打上标签[class_id,xc,yc,w,h],其中class_id为0,代表行人类别,(xc,yc)为行人目标框的中心坐标,w,h为行人目标框的宽和高;
20、步骤t2:将步骤t1抽取的图片作为目标检测模型的输入,所属目标检测模型输出行人检测框,使用损失函数计算把输出的行人检测框与输入图片的行人目标框的误差,通过神经网络的反向传播机制,对目标检测模型进行训练,直至误差收敛时停止训练,目标检测模型具备了行人检测能力。
21、作为上述技术方案的进一步描述,所述的损失函数公式为:
22、
23、
24、
25、l=λ1lcls+λ2lbox
26、其中,xi为目标检测模型预测行人检测框的概率,yi为通过softmax函数归一化的结果,控制概率在(0,1)之间;lcls为目标检测模型分类的误差,[xc,yc,w,h]为标注的真实行人目标框,[xc*,yc*,w*,h*]为目标检测模型输出的行人检测框,lcls为目标检测模型的位置误差;λ1,λ2为权重系数。
27、作为上述技术方案的进一步描述:步骤s01中的监控视频通过摄像机、摄像机阵列或者监控摄像头设备来采集获得。
28、作为上述技术方案的进一步描述,所述目标检测模型的训练方法包括以下步骤:
29、步骤w1:使用步骤s01~s06的过程收集训练数据集,把t帧没有发生打架行为的视频序列的标签设为0,把t帧没有发生打架行为的视频序列的标签设为1,把视频序列和标签一一对应,组成训练数据集和测试数据集;
30、步骤w2:把视频序列输入到行为识别模型,输出视频序列的类别,使用损失函数计算输出类别与对应标签的误差,通过神经网络的反向传播机制,训练所述行为识别模型,直至误差收敛,使所述行为识别模型具备打架行为识别能力。
31、作为上述技术方案的进一步描述,所述的损失函数公式为:
32、
33、
34、其中,xi为行为识别模型预测打架行为类别的概率,yi为通过sigmoid函数非线性化的结果,控制输出概率在(0,1)之间,为标签的值(0或者1),l为行为识别模型输出的行为类别与真实的标签之间的误差。
35、一种打架识别系统,包括行人检测模块、数据处理模块和打架识别模块,各个模块之间通过有线和/或无线的方式连接,实现彼此间的数据传输;
36、行人检测模块,其通过目标检测模型对监控视频中的行人进行检测;
37、数据处理模块,用于获取行人检测模块得到的行人检测框的交集,取相交的行人检测框的交集,并计算交集的最小外包围矩形,作为自适应的目标区域;
38、打架识别模块,将最小外包围矩形作为自适应的目标区域,把目标区域最作为输入,送进行为识别模型,识别是否为打架行为。
39、一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述的一种打架识别方法。
40、有益效果:
41、1.准确率高,本发明采用多层先验技术,首先通过目标检测模型检测行人并统计其数量,然后判断行人的检测框是否存在两个或以上并且检查其是否相交,若均满足条件,则取行人检测框的交集并计算其最小外包围矩形作为自适应目标区域,最后使用行为识别模型分析该区域是否存在打架行为,在多层的先验技术下,减少了对打架行为识别的误判率,进而提高识别准确率。
42、2.实时性好,本发明首先采用目标检测模型,而监控画面下的行人比较明确,因此,目标检测模型可以采用轻量化的模型;然后使用行为识别模型分析监控画面中的行为特征,而本发明中通过先验技术,自适应地提取了监控画面中的行人交互区域,来代替整个监控画面,大大缩小了输入的分辨率,极大地减少了行为识别模型的参数量和计算量,提高了其推理速度,保证监控视频处理的实时性。
43、3.硬件要求低,不需要深度相机,普通的摄像头即可采集监控视频;再者,本发明通过提取监控画面中行人互动的区域,把该区域代替整个监控画面作为输入,大大缩小了输入的分辨率,极大地减少了行为识别模型的参数量和计算量,降低了硬件的算力要求。
44、4.硬件平均功耗低,本发明使用多层的先验技术,通过判断监控画面的行人数量和行人交互状态,只有满足先验条件再计算自适应区域并运行行为识别模型,这样可以筛选掉很多视频片段,无需硬件长期运载行为识别模型,有利于减轻硬件负担,综合上减少了硬件的平均功耗。
45、5.吞吐量高,本发明的目标检测模型采用的是轻量化模型;再者,通过提取自适应区域,减少了输入的分辨率,大大减少了行为识别的参数量和计算量,从而保证了整体的吞吐量。
- 还没有人留言评论。精彩留言会获得点赞!