基于数据建模的数据抽样方法、设备及存储介质与流程
本技术涉及数据分析领域,尤其涉及一种基于数据建模的数据抽样方法、设备及存储介质。
背景技术:
1、大数据计算分析已经成为日常数据统计、分析的基础,在做数据分析时模型设计时,每个模型的设计需要多次验证调整。在对数据进行查询、分析、汇总时,现有技术采用的是基于可统计性列进行分析,尤其是在对大数据建立分析模型时,通常不需要对全量数据经常运算,有效降低资源消耗,仅需要一部分数据进行初步运行,以验证模型分析的准确性。但是现有的大数据的抽样都是统计学层面的抽样方法,包括但不限于简单随机抽样,系统抽样、分层抽样和整群抽样等。这些抽样的方法在大数据领域中无法保障数据的存储顺序和数据抽取的离散情况,导致数据建模的效率存在较大的不确定性。
技术实现思路
1、本技术提供一种基于数据建模的数据抽样方法、设备及存储介质,用以解决现有技术在进行数据抽样时效率低且抽取数据可靠性差的技术问题。
2、第一方面,本技术提供一种基于数据建模的数据抽样方法,包括:
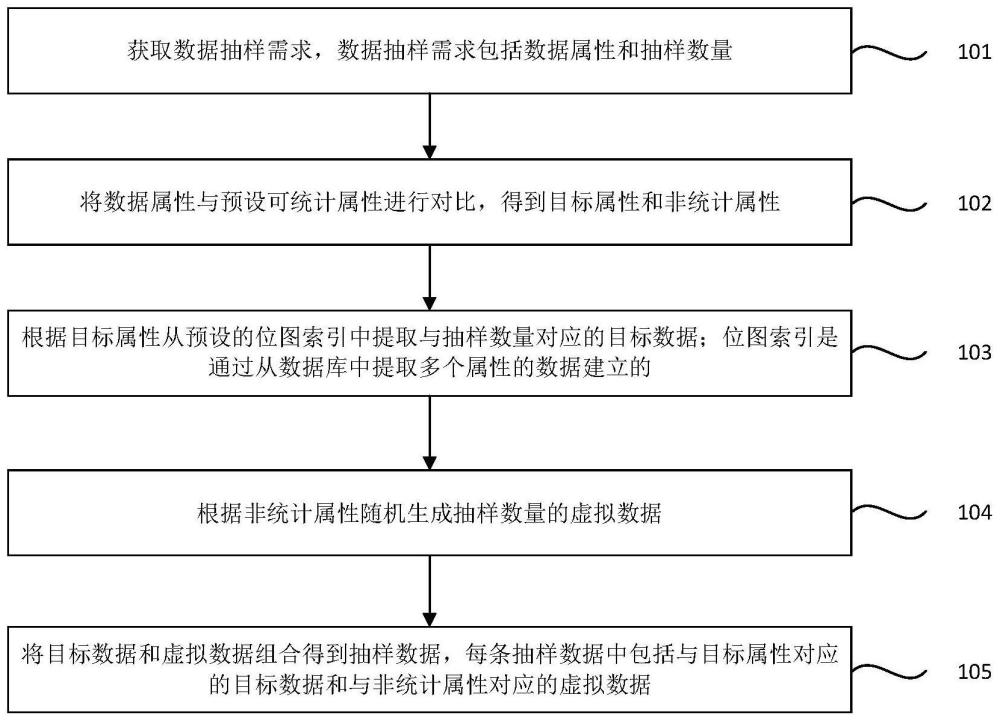
3、获取数据抽样需求,所述数据抽样需求包括数据属性和抽样数量;
4、将所述数据属性与预设可统计属性进行对比,得到目标属性和非统计属性;
5、根据所述目标属性从预设的位图索引中提取与所述抽样数量对应的目标数据;所述位图索引是通过从数据库中提取多个属性的数据建立的;
6、根据所述非统计属性随机生成所述抽样数量的虚拟数据;
7、将所述目标数据和所述虚拟数据组合得到抽样数据,每条抽样数据中包括与所述目标属性对应的目标数据和与所述非统计属性对应的虚拟数据。
8、在一种可能的设计中,所述根据所述目标属性从预设的位图索引中提取与所述抽样数量对应的目标数据之前,所述方法还包括:
9、将数据库中的基础数据进行分类得到多个属性集合,每个属性集合中包含同一属性多个类别的数据;
10、对每个属性对应的属性集合中的数据进行统计筛选,得到满足预设统计条件的可统计属性;
11、根据所述可统计属性对应的属性集合建立位图索引。
12、在一种可能的设计中,所述对每个属性集合中的数据进行统计筛选,得到满足预设统计条件的可统计属性,包括:
13、对每个属性集合中数据的类别进行统计得到类别数量;
14、根据所述属性集合中每个类别对应的基础数据计算每个类别在所述属性集合中的类别占比;
15、根据所述类别数量、类别占比与预设占比阈值,得到满足预设统计条件的可统计属性。
16、在一种可能的设计中,所述根据所述类别数量、类别占比与预设占比阈值,得到满足预设统计条件的可统计属性,包括:
17、将所述类别占比与预设占比阈值进行对比,判断是否存在所述类别占比大于预设占比阈值的类别;
18、当存在占比大于预设占比阈值的类别,将所述属性集合对应的属性划分为可统计属性;
19、当不存在占比大于预设占比阈值的类别,判断所述类别数量是否大于预设类别阈值;
20、若所述类别数量大于预设类别阈值,将所述属性集合对应的属性划分为非统计属性;
21、若所述类别数量小于或等于预设类别阈值,将所述属性集合对应的属性划分为可统计属性。
22、在一种可能的设计中,当存在占比大于预设占比阈值的类别,将所述属性集合对应的属性划分为可统计属性之后,还包括:
23、基于所述预设类别阈值计算类别保留值,所述类别保留值小于所述预设类别阈值且与所述预设类别阈值的差值为一;
24、将所述属性集合中的类别根据所述类别占比的数值从大到小进行排序,得到占比序列;
25、从所述占比序列中类别占比数值大的一段截取与所述类别保留值对应数量的保留类别,并将截取剩余的多个类别汇总为一个保留类别。
26、在一种可能的设计中,所述根据所述可统计属性对应的数据集合建立位图索引,包括:
27、对所述属性集合中的每一个类别创建对应的位图,得到与属性对应的类型索引;
28、将多个属性对应的类型索引进行位图合并,得到位图索引。
29、在一种可能的设计中,所述根据所述非统计属性随机生成所述抽样数量的虚拟数据,包括:
30、获取所述非统计属性对应的多个数据类别;
31、根据所述数据类别随机生成虚拟数据,所述虚拟数据为所述数据类别中的一种。
32、在一种可能的设计中,还包括:
33、获取所述数据库的更新数据;
34、基于所述位图索引对所述更新数据进行分析,得到差异数据,所述差异数据为不存在与所述位图索引中的数据;
35、对所述差异数据的属性和类别进行分析,并根据所述差异数据对应的属性和类别生成新的位图添加至所述位图索引。
36、第二方面,本技术提供一种基于数据建模的数据抽样设备,包括:
37、获取模块,用于获取数据抽样需求,所述数据抽样需求包括数据属性和抽样数量;
38、对比模块,用于将所述数据属性与预设可统计属性进行对比,得到目标属性和非统计属性;
39、提取模块,用于根据所述目标属性从预设的位图索引中提取与所述抽样数量对应的目标数据;所述位图索引是通过从数据库中提取多个属性的基础数据建立的,所述数据库中存储有所有属性的数据;
40、生成模块,用于根据所述非统计属性随机生成所述抽样数量的虚拟数据;
41、组合模块,用于将所述目标数据和所述虚拟数据组合得到抽样数据,每条抽样数据中包括与所述目标属性对应的目标数据和与所述非统计属性对应的虚拟数据。
42、在一种可能的设计中,提取模块,还用于:
43、将数据库中的基础数据进行分类得到多个属性集合,每个属性集合中包含同一属性多个类别的数据;
44、对每个属性对应的属性集合中的数据进行统计筛选,得到满足预设统计条件的可统计属性;
45、根据所述可统计属性对应的属性集合建立位图索引。
46、在一种可能的设计中,提取模块,还用于:
47、对每个属性集合中数据的类别进行统计得到类别数量;
48、根据所述属性集合中每个类别对应的基础数据计算每个类别在所述属性集合中的类别占比;
49、根据所述类别数量、类别占比与预设占比阈值,得到满足预设统计条件的可统计属性。
50、在一种可能的设计中,提取模块,还用于:
51、将所述类别占比与预设占比阈值进行对比,判断是否存在所述类别占比大于预设占比阈值的类别;
52、当存在占比大于预设占比阈值的类别,将所述属性集合对应的属性划分为可统计属性;
53、当不存在占比大于预设占比阈值的类别,判断所述类别数量是否大于预设类别阈值;
54、若所述类别数量大于预设类别阈值,将所述属性集合对应的属性划分为非统计属性;
55、若所述类别数量小于或等于预设类别阈值,将所述属性集合对应的属性划分为可统计属性。
56、在一种可能的设计中,提取模块,还用于:
57、基于所述预设类别阈值计算类别保留值,所述类别保留值小于所述预设类别阈值且与所述预设类别阈值的差值为一;
58、将所述属性集合中的类别根据所述类别占比的数值从大到小进行排序,得到占比序列;
59、从所述占比序列中类别占比数值大的一段截取与所述类别保留值对应数量的保留类别,并将截取剩余的多个类别汇总为一个保留类别。
60、在一种可能的设计中,提取模块,还用于:
61、对所述属性集合中的每一个类别创建对应的位图,得到与属性对应的类型索引;
62、将多个属性对应的类型索引进行位图合并,得到位图索引。
63、在一种可能的设计中,生成模块,具体用于:
64、获取所述非统计属性对应的多个数据类别;
65、根据所述数据类别随机生成虚拟数据,所述虚拟数据为所述数据类别中的一种。
66、在一种可能的设计中,提取模块,还用于:
67、获取所述数据库的更新数据;
68、基于所述位图索引对所述更新数据进行分析,得到差异数据,所述差异数据为不存在与所述位图索引中的数据;
69、对所述差异数据的属性和类别进行分析,并根据所述差异数据对应的属性和类别生成新的位图添加至所述位图索引。
70、第三方面,本技术提供一种基于数据建模的数据抽样设备,包括:处理器,以及与处理器通信连接的存储器;
71、存储器存储计算机执行指令;
72、处理器执行存储器存储的计算机执行指令,使得接入网络资源的路径查询设备执行第一方面中任一项的基于数据建模的数据抽样方法。
73、第四方面,本技术提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机执行指令,计算机执行指令被处理器执行时用于实现如第一方面中任一项的基于数据建模的数据抽样方法。
74、本技术提供的基于数据建模的数据抽样方法、设备及存储介质,通过获取数据抽样需求,数据抽样需求包括数据属性和抽样数量;将数据属性与预设可统计属性进行对比,得到目标属性和非统计属性;根据目标属性从预设的位图索引中提取与抽样数量对应的目标数据;位图索引是通过从数据库中提取多个属性的数据建立的;根据非统计属性随机生成抽样数量的虚拟数据;将目标数据和虚拟数据组合得到抽样数据,每条抽样数据中包括与目标属性对应的目标数据和与非统计属性对应的虚拟数据。通过位图索引的方式快速生成满足数据抽样需求的目标属性数据,同时通过随机生成的方式生成非统计属性的数据,满足数据抽样的数据要求和数量要求,有效提高了抽样效率、保证了抽样数据的可靠性。
- 还没有人留言评论。精彩留言会获得点赞!