一种基于内容的规则及文本分类三段式表字段推断方法与流程
本发明涉及一种推断方法,尤其涉及一种基于内容的规则及文本分类三段式表字段推断方法。
背景技术:
1、在医疗数据集成过程中,由于各医院需求不同以及各医疗产商表结构及表字段设计差异较大。特别地,存在较多表字段缺失或者是无意义字符的情况,这给数据集成带来巨大的挑战。
2、在数据集成过程中,业务人员需要基于相关业务场景推断业务表各字段所表达的含义,进而进行后续的数据集成。这种基于人工经验识别表字段含义的方式比较耗时,尤其是在面对成百上千张数据表时,也容易出错,即使是一位经验丰富的业务人员。
3、因此,如何准确而快速自动识别出各业务表中表字段含义便非常重要,这将极大的降低数据工作者的工作量并提高工作效率。对于这种表字段的推断识别,传统的方式是业务人员基于业务理解进行人工推断识别,比较耗时。目前存在一些自动识别表字段含义的方式,但主要从表字段本身出发,将不规范的表字段进行修正,这对于表字段完全缺失的情况便无能为力。
4、对于表名字段名智能补全,近些年出现一些基于自然语言处理的方式,专利文献:201910664540.2,公开一种基于nlp技术的表名字段名智能补全方法,包括以下步骤;s1:预处理;s2:原始拆分;s3:查字典;s4:语言识别;s5:高级拆分;s6:补全推断;s7:输出翻译。对于数据表字段推断识别初期主要通过业务人员基于业务理解进行人工识别,这种方式准确率较高,但是比较耗时。另外,当需要识别的数据表数量急剧增加时,人工推断的准确率也会随之降低。对于表名字段名智能补全,近些年出现一些基于自然语言处理的方式,该方法通过数据预处理、分词、语言识别等步骤对表名字段名进行补全。但是该方式仅从字段名本身进行字段的推断补全,并没有考虑字段内容本身的含义,这对于字段名完全缺失的情况,便无能为力。因此,本发明从字段内容角度出发,解决字段名完全缺失的情况。
技术实现思路
1、本发明主要是解决现有技术中存在的不足,提供解决不同厂商多样化的表字段在集成时低效且容易出错的问题。
2、本发明的上述技术问题主要是通过下述技术方案得以解决的:
3、一种基于内容的规则及文本分类三段式表字段推断方法,按以下步骤实现数据表字段自动推断:
4、步骤一:收集一家医疗机构原始数据表,比如患者基本信息表,以下数据仅按照原格式随机生成:
5、
6、步骤二:医疗机构原始数据通常存在缺失、不规范及类型混乱相关问题,为了有效进行数据类型及后续表字段的推断识别,对表格中列数据进行如下处理:
7、(1)、大小写统一、空格及无意义字符剔除;
8、(2)、缺失值采用众数填充;
9、步骤三:各字段数据类型识别,主要识别步骤如下:
10、(1)、定义各字段类型,如下:
11、①日期型:能被合理切分为年、月、日的字符串即认为是日期数据,记为d;
12、②文本型:含有中文字符即认为是文本数据,记为t;
13、③类别型:含有英文字母且不含中文字符及认为是类别数据,记为c;
14、④整型:仅含0-9的阿拉伯数字即认为是整型数据,记为i;
15、⑤浮点型:同时含有0-9的阿拉伯数字且仅含一位小数点即认为是浮点型数据,记为f;
16、⑥标志型:仅含0、1或9数字即认为是标志型,记为g;
17、⑦其他:无法归纳为上述任一种类型,记为0;
18、(2)、统计各字段不同类型数据占比,记为:di,ti,ci,ii,fi,gi,oi:di,其中di表示第i列日期型占比;ti表示第i列文本型占比;ci表示第i列类别型占比;ii表示第i列整型占比;fi表示第i列浮点型占比;gi表示第i列标志型占比,oi表示第i列其他类型占比;
19、(3)、确定各字段数据类型,选择占比最大类型作为该列的数据类型,但以下情况需要进行类型修正或者数据修正:
20、①ii最大,但fi大于一定阈值,阈值为10%,将该列数据类型修正为浮点型;
21、②如果该列被识别为非文本型,但存在文本数据,则将文本数据修正为空值,以防影响后续表字段推断;
22、经过步骤3字段类型识别,各表字段被识别情况如下:
23、
24、步骤四:规则维度表字段推断识别:
25、(1)、基于业务规则的识别:对于col_2、col_3、col_7、col_8及col_11这种相对规范的数据内容,从此维度进行,具体比如:
26、①姓名:字符长度小于4且首个字符在百家姓字典中,当该字段满足此条件且超过一定阈值,阈值为80%,即被推断为姓名,col_3即被推断为姓名;
27、②身份证号:15位或者18位数字,最后一位可能是字符“x”且特定位置的数字符合年、月及日相关日期规范,当该字段满足此条件且超过一定阈值,阈值为80%,即被推断为身份证号,col_2即被推断为身份证号;
28、③邮政编码:字符长度为6位数字且在邮政编码字典中,当该字段满足此条件且超过一定阈值,阈值为80%,即被推断为邮政编码,col_7即被推断为邮政编码;
29、④联系号码:字符长度位7位或者11位数字组成且符合电话号码规范,当该字段中满足此条件且超过一定阈值,阈值为80%,即被推断为联系号码,col_8即被推断为联系号码;
30、⑤icd10编码:字符由数字及字母组成且在icd10编码字典中,当该字段中满足此条件且超过一定阈值,阈值为80%,即被推断为icd10编码,col_11即被推断为icd10编码;
31、(2)、基于逻辑规则的识别:
32、①col_4与col_9都是日期类型的数据,在医疗机构数据中,日期类是患者的出生日期或者就诊日期;
33、逻辑上,出生日期跨度较大且年份维度差异大,而就诊日期跨度较小,年份维度一般也就中在近10年;基于此,从逻辑上区分col_4位出生日期,col_9为就诊日期;另外利用col_2列为身份证进一步确认col_4是否为出生日期列;
34、②col_5为整型数据且分布在0-100范围,再加上col_2身份证列验证,很容易推断为年龄;
35、③col_1中各数据值不相同且等于数据总行数,很容易推断为主键;
36、经过上述规则模块推断,各表字段被推断识别情况如下:
37、 col_1 col_2 col_3 col_4 col_5 col_6 col_7 col_8 col_9 col_10 col_11 col_12 col_13 col_14 主键 身份证号 姓名 出生日期 年龄 t 邮政编码 联系号码 就诊日期 t icd10编码 f f g
38、步骤五:算法维度表字段推断识别:算法推断表字段,涉及标签确定、专家标注、数据修正、特征工程、模型训练及测试相关步骤,最后使用训练好的模型进行表字段推断,详细步骤如下:
39、(1)、标签确定:基于数据集成标准化后的数据,确定文本数据所有可能标签,记为{l1,l2,...,li,...,lm),其中li标识第i个标签,m表示标签的数量;
40、(2)、专家标注:收集部分原始数据,业务专家按照上述确定的m种标签对数据进行打标,为后续算法训练准备;
41、(3)、数据修正:文本数据通常存在多义性,比如col_10列中“妄想狂跖骨骨折”及“过敏性肠炎+低血压”均表示多个诊断,为了提高算法推断准确率,需要将其原子化,分别拆分为“妄想症”、“跖骨骨折”和“过敏性肠炎”、“低血压”;
42、(4)、特征工程构建:基于同业务专家沟通讨论,构建一些有利于表字段推断的特征,比如字符长度、关键词含量;
43、(5)、模型构建及训练:
44、①将文本数据通过词嵌入相关技术转化为词向量表示,选择word2vec;
45、②词向量同上述特征工程构建的特征联合,为后续算法训练和测试做准备;
46、③将上述数据按照一定比例,采用7∶3,划分为训练集和测试集,前者用于模型训练,后者用于模型效果测试;
47、④使用机器学习或者深度学习算法进行模型训练及调优,确定模型最终参数,选择fasttext;
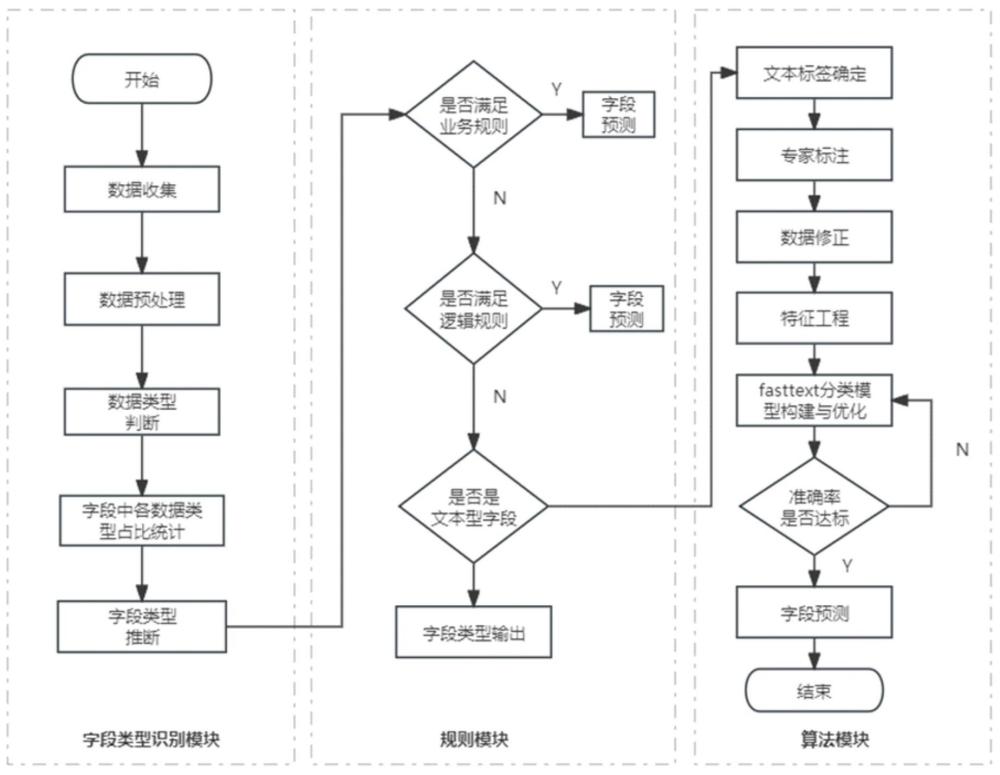
48、⑤使用测试集确定训练好模型效果,选择效果最优模型即可;
49、(6)、模型预测
50、①使用最终选择的模型进行文本数据的分类预测,预测结果记为pij,其中i表示第i列数据,j表示{l1,l2,...,li,...,lm}中第j个标签,即lj;
51、②选择当前列算法预测标签最多的作为当前列最终字段推断结果,col_6被推断为“住址”,col_10被推断为“icd10诊断”;
52、经过上述算法模块进一步推断,各表字段被推断识别情况如下:
53、
54、对于col_12及col_13这种浮点型字段,仅从内容本身暂时无法给予一个较优的通用推断方法,需要基于业务知识进行个性化处理。
55、本发明通过规则和自然语言处理(natural language processing,nlp)算法相结合的方式,从字段内容维度进行表字段自动推断识别,主要通过以下三个阶段完成:
56、阶段一:字段类型识别模块,利用字段内容确定字段可能类型,主要包括日期型、文本型、类别型、整型、浮点型、标志型及其他;
57、阶段二:规则模块字段推断,主要从规则维度对一些存在规范的数据或存在逻辑可推断的字段进行推断,比如身份证号、电话号码及主键等;
58、阶段三:算法模块字段推断,对于规则模块无法推断的文本型数据,将文本通过词嵌入技术转化为向量,进而进行文本分类,文本分类的结果即为推断结果。
59、创新点:
60、1.以字段内容为出发点,有效解决字段名缺失及无意义字符问题,扩展表字段推断应用场景。
61、2.采用分类分阶段的方式,有效拆解表字段推断任务并提升整个推断任务效率。
62、3、用规则和文本相结合的方式进行表字段推断,有效发挥各方法优点,提升整体推断准确率;
63、因此,本发明的一种基于内容的规则及文本分类三段式表字段推断方法,从字段内容维度出发,以规则和文本分类相结合的方法,分阶段进行表字段推断识别,取得较优表现。
64、说明书附图
65、图1是本发明中三段式表字段推断模型的结构示意图。
- 还没有人留言评论。精彩留言会获得点赞!