基于多模态大语言模型的多模态命名实体识别方法和装置
本技术涉及多模态命名实体识别,特别是涉及一种基于多模态大语言模型的多模态命名实体识别方法和装置。
背景技术:
1、互联网用户每天都会产生大量的多模态数据。如何从这些海量数据中挖掘有价值的信息是一个重要的研究课题,引起了研究人员的广泛关注。多模态命名实体识别(multimodal named entity recognition,mner)任务的目的是识别社交媒体平台(如推特)上的图文对中的文本实体,是支持知识图谱、搜索引擎和推荐系统等应用的关键技术。
2、最近多模态命名实体识别的相关研究大体上可以分为两类:图像+文本方法和文本+文本方法。图像+文本方法将图像和文本信息在特征级别进行融合,而文本+文本方法则将图像转换为文本,并利用文本交互来融合图像和文本信息。虽然这些方法取得了良好的性能表现,但它们在面对社交媒体平台图文对数据的某些特点时仍存在局限性。
3、具体而言,在传统的图像+文本方法中,图像和文本信息在特征级别上合并。通常使用resnet和vit等视觉主干网络提取图像特征,然后通过拼接、注意机制等方式将其与文本特征相结合。例如,rpbert和mrc-mner使用直接拼接方式融合图像特征和文本特征。maf和hvpnet采用跨模态注意机制进行特征融合。为了缓解模态之间的差距,maf和采用对比学习来对齐模态特征,获得了性能上的提升。
4、另一方面,传统文本+文本方法将图像中包含的信息转换为文本,避免了模态差异带来的问题。例如,wu等人利用目标检测模型将图像转换成多个对象标签。chen等人将图像替换为图像描述,用于跨模态信息融合。ita利用图像描述、ocr和目标检测模型提取图像信息。
5、总而言之,目前的多模态命名实体识别,均是聚焦于文本或者图像的特征本身,从而导致在多模态命名实体识别的效果不佳。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种基于多模态大语言模型的多模态命名实体识别方法和装置。
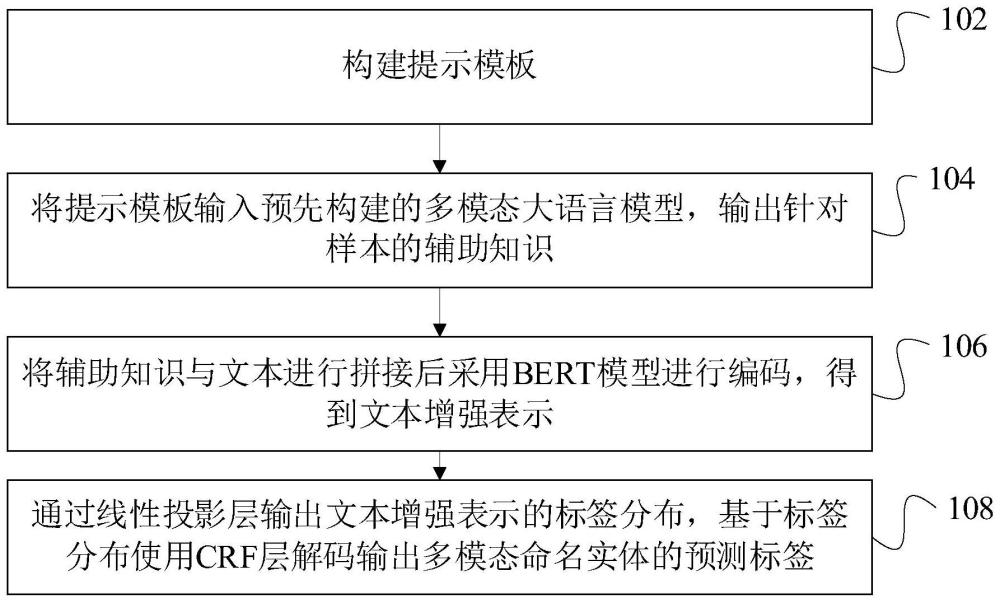
2、一种基于多模态大语言模型的多模态命名实体识别方法,所述方法包括:
3、构建提示模板;所述提示模板包括:图像填充区域、文本填充区域、图像信息获取指令以及图文知识拓展指令;所述图像填充区域和所述文本填充区域分别用于填充样本中的图像和文本;所述信息获取指令和图文知识拓展指令分别用于指示从所述图像中获取图像信息和指示理解所述样本;
4、将所述提示模板输入预先构建的多模态大语言模型,输出针对所述样本的辅助知识;
5、将所述辅助知识与所述文本进行拼接后采用bert模型进行编码,得到文本增强表示;
6、通过线性投影层输出所述文本增强表示的标签分布,基于所述标签分布使用crf层解码输出多模态命名实体的预测标签。
7、在其中一个实施例中,所述多模态命名实体包括:角色实体、文本实体和实体位置。
8、在其中一个实施例中,所述角色实体的类型包括:人物、地点、组织和其他。
9、在其中一个实施例中,所述信息获取指令和图文知识拓展指令中分别加入限定词语控制所述辅助知识的长度。
10、在其中一个实施例中,还包括:将所述辅助知识与所述文本进行拼接为[cls]t[sep]ts,其中,t表示所述文本,ts表示辅助知识;
11、采用bert模型进行编码,得到文本增强表示为:
12、
13、其中,文本t={t1,…,tn},tn表示第n个token,辅助知识ts={q1,…,qm},qm表示第m个token,ht∈rn×d表示文本增强表示中的文本表示,表示文本增强表示中的辅助知识表示,d是bert最后一层的隐藏层维度。
14、在其中一个实施例中,还包括:通过线性投影层输出所述文本表示的标签分布。
15、在其中一个实施例中,还包括:通过线性投影层输出所述文本增强表示的标签分布为:
16、
17、表示经过bio标记编码的输出标签的概率分布,a表示bio标记类型的数量;
18、基于所述标签分布使用crf层解码输出多模态命名实体的预测标签为:
19、
20、其中,y表示所有标签序列的集合,y′表示可能的标签序列组合。y={y1,…,yn}表示每个token的预测标签序列;
21、在其中一个实施例中,还包括:通过构建负对数似然函数的损失函数训练所述bert模型,所述负对数似然函数的损失函数为:
22、
23、其中,y*是实际的标签序列。
24、一种基于多模态大语言模型的多模态命名实体识别装置,所述装置包括:
25、提示模板构建模块,用于构建提示模板;所述提示模板包括:图像填充区域、文本填充区域、图像信息获取指令以及图文知识拓展指令;所述图像填充区域和所述文本填充区域分别用于填充样本中的图像和文本;所述信息获取指令和图文知识拓展指令分别用于指示从所述图像中获取图像信息和指示理解所述样本;
26、辅助知识生成模块,用于将所述提示模板输入预先构建的多模态大语言模型,输出针对所述样本的辅助知识;
27、文本增强模块,用于将所述辅助知识与所述文本进行拼接后采用bert模型进行编码,得到文本增强表示;
28、预测模块,用于通过线性投影层输出所述文本增强表示的标签分布,基于所述标签分布使用crf层解码输出多模态命名实体的预测标签。
29、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
30、构建提示模板;所述提示模板包括:图像填充区域、文本填充区域、图像信息获取指令以及图文知识拓展指令;所述图像填充区域和所述文本填充区域分别用于填充样本中的图像和文本;所述信息获取指令和图文知识拓展指令分别用于指示从所述图像中获取图像信息和指示理解所述样本;
31、将所述提示模板输入预先构建的多模态大语言模型,输出针对所述样本的辅助知识;
32、将所述辅助知识与所述文本进行拼接后采用bert模型进行编码,得到文本增强表示;
33、通过线性投影层输出所述文本增强表示的标签分布,基于所述标签分布使用crf层解码输出多模态命名实体的预测标签。
34、上述基于多模态大语言模型的多模态命名实体识别方法和装置,通过结合多模态大语言模型的方式进行文本知识的增强,从而显著提升多模态命名实体识别的性能,具体而言,在利用多模态大语言模型的方式进行文本知识的增强时,其核心是构建提示模板,在本发明的构建提示模板中,包括:图像填充区域、文本填充区域、图像信息获取指令以及图文知识拓展指令,借助于多模态大语言模型的视觉能力,以及图像信息获取指令以及图文知识拓展指令构建的思维链提示,能够在与多模态大语言模型进行对话时,充分的理解对话者的真实意图,从而提取得到高质量的辅助知识,从而在辅助知识进行的文本增强下,能够大规模的提升多模态命名实体的识别性能。
- 还没有人留言评论。精彩留言会获得点赞!