一种基于机器学习的mura特征提取与识别方法与流程
本发明涉及液晶面板生产领域,具体涉及一种基于机器学习的mura特征提取与识别方法。
背景技术:
1、在液晶面板生产过程中,对于mura类缺陷识别与定位是整个缺陷识别流程中必不可少的关键步骤,mura类缺陷是指显示器亮度不均匀,造成各种痕迹的现象。mura类缺陷识别的位置精度与分类准确性直接关系到了产品良率、客诉赔偿、人工成本等因素。因此这一过程尤为重要。
2、现有的mura类缺陷识别技术可以分为三大方向,第一是依靠人眼识别,在拍摄机台的屏幕前安置一名专门的操作员,每次需要识别mura类缺陷的种类与位置的时候,该人员操作软件将图像进行对比度拉伸,通过不断变换对比度调节,直至屏幕当中可清晰展现mura类缺陷;第二是基于传统模板匹配的算法,方案是将产线实际拍摄到的液晶面板图像与事先规定好的mura类缺陷图进行旋转平移比对,最终输出缺陷种类与位置;第三是基于深度学习的自动识别方方案,在模型开始训练之前收集大量的mura类缺陷图像并且进行人工标注作为训练集,完成训练之后,模型便可拥有自动识别mura类缺陷的能力。
3、人员操作方案的劣势在于,mura类缺陷在判定的过程当中,受人员的因素影响极大,对于同一张液晶面板图像,不同的判图员对其mura位置判断、是否有mura缺陷的判断经常结果不一致。在现行的场内人工判定时,通常需要有一名经验丰富的判图员作为判图小组组长,对人工检测结果进行抽检复核,会造成极大的人工成本浪费。同时由于人员疲劳、定位效果不佳等原因,也会造成一定的失误。对于判定不一致的部分缺陷,存在着过杀以及漏检等相应的良率问题。
4、基于传统视觉方法的劣势在于针对每种形态的mura缺陷需要收集样例图,此过程较为繁琐,在上线一只产品的时候,需要图像算法人员针对本产品特征进行多次参数调试,导致新产品上线效率低。
5、基于深度学习方式的劣势在于模型训练周期长、收集图片多、对运算单元有较高的要求等。对于未在训练集中出现过的mura缺陷,需要进行多轮的标注与迭代训练。这一过程会继续降低部署效率。
技术实现思路
1、为解决现有技术中存在的技术问题,本发明提供了一种基于机器学习的mura特征提取与识别方法,以对图像的高维特征进行统计学分析,自动识别出异于液晶面板普通状态的关键位置,以此关键位置作为对人工mura判定的建议显示在软件界面上。
2、为达到上述目的,本发明的技术解决方案如下:
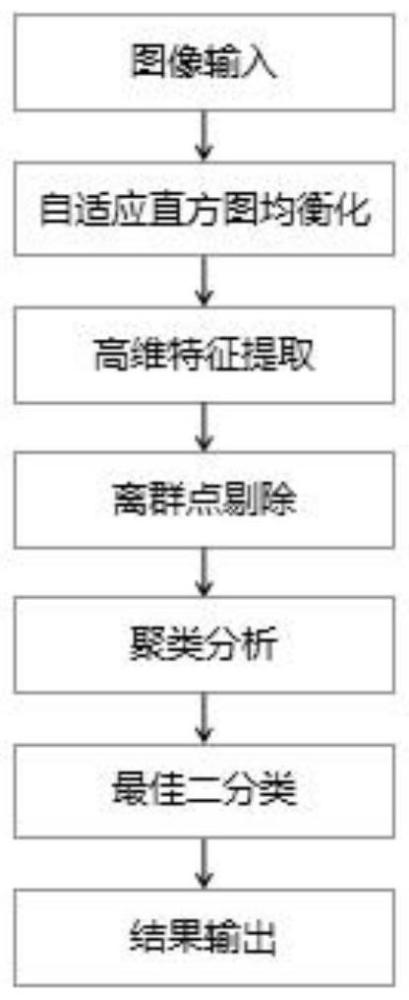
3、一种基于机器学习的mura特征提取与识别方法,包括以下步骤:
4、步骤一,输入液晶面板图像,对图像进行自适应直方图均衡化;
5、步骤二,对全场图像的每个像素进行高维特征提取;
6、步骤三,进入机器学习环节,剔除离群点,在剩余样本中实施聚类算法,进入最佳二值化分割环节,输出前景点掩膜图像。
7、作为优选的技术方案,在步骤一中,直自适应直方图均衡化的计算方式是统计每个灰度值在0-255之上的直方图分布,取分布最高的前85%作为直方图的上下界,以上下界线性将直方图拉取到0-255,使mura缺陷清晰得显示在图像当中,以备后续运算处理。
8、作为优选的技术方案,在步骤二中,高维特征包括灰度值、相对中心坐标、矩形box方差、矩形box最大最小值、横向/纵向方差、横向/纵向最大最小值、包络相似性,每个高维特征赋予对应的权重。
9、作为优选的技术方案,特征计算方式为:灰度值i(x,y);相对中心坐标即点坐标到液晶面板中心的归一化坐标
10、xrel=(x-xcenter)/wid,yrel=(y-ycenter)/het;矩形区域内灰度值的方差矩形区域内灰度值的最大最小值min/max{i(x,y)|(x,y)∈box};横纵方向内灰度值的方差
11、横纵方向内灰度值的最大最小值
12、min/max{i(x,y)|(x,y)∈col/row};包络相似性即矩形区域内灰度值与相邻区域的逐像素差值的绝对值的和
13、
14、作为优选的技术方案,在步骤三中,剔除离群点的步骤为:在高维特征空间内计算全部样本的几何中心,同时计算每一个样本到几何中心的欧式距离;将欧式距离从大到小排布,选取并剔除其中最大的3%-5%的数据视为离群数据;剔除之后剩余样本继续计算几何中心,且计算剩余样本每个样本到几何中心的欧式距离,继续剔除3%-5%的离群数据;重复这一步骤,直到保留约70%的数据再进入下一环节。
15、作为优选的技术方案,在步骤三中,聚类算法是计算空间中密度较大的点集的位置作为锚点,按事先设定好的密度阈值,在密度阈值之上的点即为锚定点,距离相近的若干锚定点合为同一锚定点,最终在整个高维样本空间中寻找到若干锚定点;以锚定点为核心,在高位空间中对样本进行分割;计算每一个单独样本到全部锚定点的距离,以其距离最近的点为其归属;重复分割直到分割达到稳定状态。
16、作为优选的技术方案,在步骤三中,最佳二值化分割环节是针对每个聚类完成的集合,计算像素灰度均值,将像素灰度均值按平均灰度由高至低进行排序并统计累计频率,取灰度值最高的累计频率大于30%的点作为mura缺陷前景点。
17、与现有技术相比,本发明的有益效果为:
18、(1)本发明的基于机器学习的mura特征提取与识别方法,通过对图像的高维特征进行统计学分析,自动识别出异于液晶面板普通状态的关键位置,并以此关键位置作为对人工mura判定的建议显示在软件界面上。
19、(2)本发明的基于机器学习的mura特征提取与识别方法的主要特点在于:可自动识别不同种类、不同形态、不同图像特征的mura缺陷,运算简便,对计算单元的硬件能力没有很高要求,可快速部署在多个站点。
技术特征:
1.一种基于机器学习的mura特征提取与识别方法,其特征在于,所述方法包括以下步骤:
2.根据权利要求1所述的一种基于机器学习的mura特征提取与识别方法,其特征在于,在所述步骤一中,直自适应直方图均衡化的计算方式是统计每个灰度值在0-255之上的直方图分布,取分布最高的前85%作为直方图的上下界,以上下界线性将直方图拉取到0-255,使mura缺陷清晰得显示在图像当中,以备后续运算处理。
3.根据权利要求1所述的一种基于机器学习的mura特征提取与识别方法,其特征在于,在所述步骤二中,高维特征包括灰度值、相对中心坐标、矩形box方差、矩形box最大最小值、横向/纵向方差、横向/纵向最大最小值、包络相似性,每个高维特征赋予对应的权重。
4.根据权利要求3所述的一种基于机器学习的mura特征提取与识别方法,其特征在于,特征计算方式为:灰度值i(x,y);相对中心坐标即点坐标到液晶面板中心的归一化坐标xrel=(x-xcenter)/wid,yrel=(y-ycenter)/het;矩形区域内灰度值的方差dev[{i(x,y)|(x,y)∈box}];矩形区域内灰度值的最大最小值min/max{i(x,y)|(x,y)∈box};横纵方向内灰度值的方差dev[{i(x,y)|(x,y)∈col/row}];横纵方向内灰度值的最大最小值min/max{i(x,y)|(x,y)∈col/row};包络相似性即矩形区域内灰度值与相邻区域的逐像素差值的绝对值的和
5.根据权利要求1所述的一种基于机器学习的mura特征提取与识别方法,其特征在于,在所述步骤三中,剔除离群点的步骤为:在高维特征空间内计算全部样本的几何中心,同时计算每一个样本到几何中心的欧式距离;将所述欧式距离从大到小排布,选取并剔除其中最大的3%-5%的数据视为离群数据;剔除之后剩余样本继续计算几何中心,且计算剩余样本每个样本到几何中心的欧式距离,继续剔除3%-5%的离群数据;重复这一步骤,直到保留约70%的数据再进入下一环节。
6.根据权利要求1所述的一种基于机器学习的mura特征提取与识别方法,其特征在于,在所述步骤三中,聚类算法是计算空间中密度较大的点集的位置作为锚点,按事先设定好的密度阈值,在密度阈值之上的点即为锚定点,距离相近的若干锚定点合为同一锚定点,最终在整个高维样本空间中寻找到若干锚定点;以锚定点为核心,在高位空间中对样本进行分割;计算每一个单独样本到全部锚定点的距离,以其距离最近的点为其归属;重复分割直到分割达到稳定状态。
7.根据权利要求1所述的一种基于机器学习的mura特征提取与识别方法,其特征在于,在所述步骤三中,最佳二值化分割环节是针对每个聚类完成的集合,计算像素灰度均值,将所述像素灰度均值按平均灰度由高至低进行排序并统计累计频率,取灰度值最高的累计频率大于30%的点作为mura缺陷前景点。
技术总结
本发明涉及一种基于机器学习的mura特征提取与识别方法,包括以下步骤:输入液晶面板图像,对图像进行自适应直方图均衡化;对全场图像的每个像素进行高维特征提取;进入机器学习环节,剔除离群点,在剩余样本中实施聚类算法,进入最佳二值化分割环节,输出前景点掩膜图像。本发明的基于机器学习的mura特征提取与识别方法,通过对图像的高维特征进行统计学分析,自动识别出异于液晶面板普通状态的关键位置,并以此关键位置作为对人工mura判定的建议显示在软件界面上,可自动识别不同种类、不同形态、不同图像特征的mura缺陷,运算简便,对计算单元的硬件能力没有很高要求,可快速部署在多个站点。
技术研发人员:刁晓淳,王文瑞
受保护的技术使用者:上海哥瑞利软件股份有限公司
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!