基于时空卷积块的神经网络CST_DE3DNet的动作识别方法
本发明涉及了一种动作识别方法,涉及深度学习的动作识别,具体涉及一种基于时空卷积块的神经网络cst_de3dnet的动作识别方法。
背景技术:
1、随着深度学习技术的不断发展和动作识别应用场景的增加,基于深度学习的动作识别技术已成为该领域的关键研究方向。
2、动作识别技术在计算机视觉领域中具有重要的研究意义,并在人机交互等多个领域得到广泛应用。目前,动作识别方法主要可分为两种:基于传统机器学习手动提取特征的方法和基于深度学习网络学习特征的方法。
3、传统机器学习手动提取特征的方法通过采用传统机器学习算法对视频进行预处理,提取特征,将其向量化,再进行模型训练和动作分类预测。然而,这种方法对于视频动作识别面临着光照、背景变化以及视频帧之间的关联等因素的挑战,导致无法充分提取手势特征,其鲁棒性较差。
4、相比之下,基于深度学习的动作识别方法在二维图像的基础上增加了时序信息,因此能够学习空间序列和时间序列特征信息。例如,simonyan提出了双流cnn的经典方法,其中空间流网络和时间流网络分别学习空间特征和时间特征,然后将两者融合,从而弥补了传统机器学习方法在时间序列特征上的缺失。此外,tran等人提出了c3d模型,用于提取视频的时空特征。然而,该方法存在参数过多和计算量较大的问题。此外,传统卷积网络在对长期依赖关系的建模能力上相对有限,难以捕捉到视频序列中更长时间跨度的语义信息。
5、因此,当前研究致力于改进基于深度学习的动作识别方法,以解决参数量大、计算复杂度高以及对长期依赖关系建模能力不足等问题。这些努力旨在进一步提升动作识别技术在视频分析中的效果和性能。
技术实现思路
1、为了解决背景技术中存在的问题,本发明提供了一种基于时空卷积块的神经网络cst_de3dnet(action recognition network with channel-spatio-temporalattentionand decoupled efficient 3d convolution)的动作识别方法。方法针对复杂时空特征难以有效提取重点信息、传统的三维卷积神经网络计算量参数较大以及无法同时兼顾效率和性能等问题。该方法采用了基于时空卷积块的神经网络cst_de3dnet,以解决传统3dcnn网络结构中参数量较大的问题。基于时空卷积块的神经网络cst_de3dnet通过将3d卷积核拆分为空间维度上的二维卷积和时间维度上的一维卷积,同时使用深度可分离的空间二维卷积和深度可分离的时间一维卷积来优化这两种卷积操作,从而有效减少了参数的计算量。此外,还设计了一种全新的时空注意力机制。该方法通过在通道、空间和时间三个维度上分别应用注意力机制,能够有效捕捉到视频中重要的信息。通过在三个维度上应用注意力机制,该模型能够进一步提高网络的性能和效率。
2、本发明采用的技术方案是:
3、本发明的基于时空卷积块的神经网络cst_de3dnet的动作识别方法,包括:
4、步骤1)将带有动作类别标签的若干动作类别的动作视频进行预处理后构成动作训练集。
5、步骤2)建立基于时空卷积块的神经网络cst_de3dnet,将动作训练集输入基于时空卷积块的神经网络cst_de3dnet中进行训练,获得训练完成的基于时空卷积块的神经网络cst_de3dnet。
6、步骤3)采集待识别的动作视频并输入训练完成的基于时空卷积块的神经网络cst_de3dnet中,训练完成的基于时空卷积块的神经网络cst_de3dnet处理后输出待检测的动作视频的动作类别,完成动作识别。
7、所述的步骤1)中,针对每个带有动作类别标签的动作视频,首先采用稀疏采样方法提取动作视频中的预设帧数的视频帧序列,然后将提取出的视频帧序列中的每个视频帧进行尺寸归一化处理完成预处理,最终将预处理后的各个动作视频的视频帧构成动作训练集。
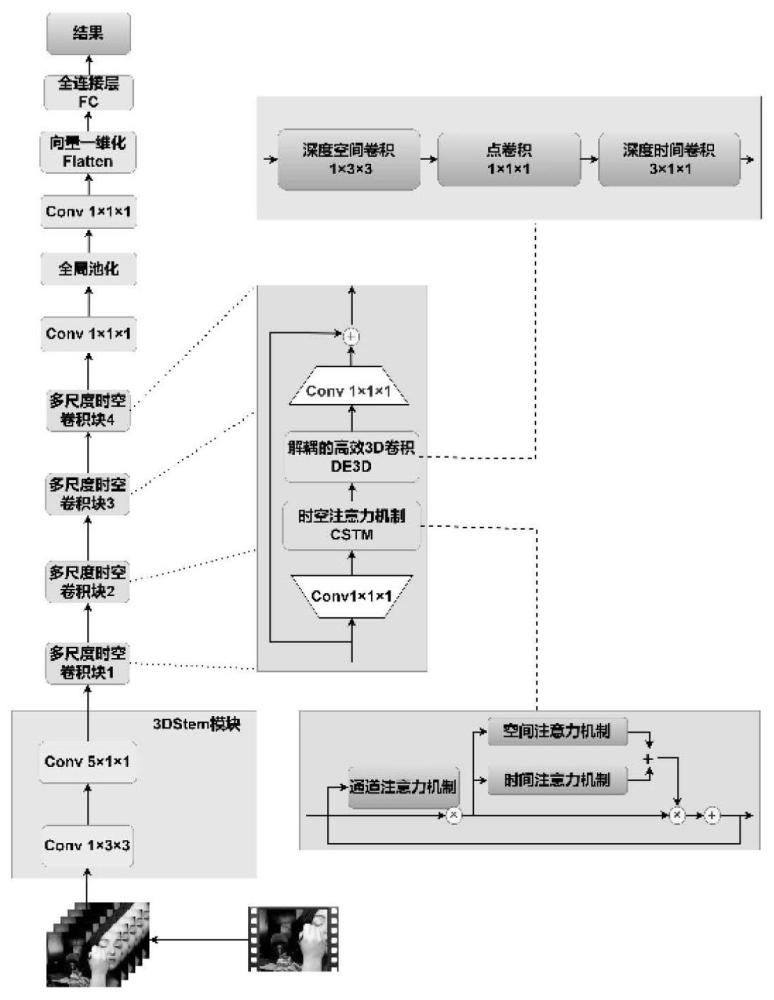
8、所述的步骤2)中,基于时空卷积块的神经网络cst_de3dnet包括依次连接的3dstem特征提取模块、四个多尺度时空卷积块cst_de3d、第一1×1×1的3d卷积层、全局平均池化层、第二1×1×1的3d卷积层、向量一维化操作flatten和全连接层fc。
9、所述的3dstem特征提取模块包括依次连接的第三1×3×3的3d卷积层和第四5×1×1的3d卷积层。
10、所述的多尺度时空卷积块cst_de3d包括依次连接的第五1×1×1的3d卷积层、时空注意力机制cstm、解耦的高效3d卷积模块de3d和第六1×1×1的3d卷积层,多尺度时空卷积块cst_de3d的输入依次经第五1×1×1的3d卷积层、时空注意力机制cstm、解耦的高效3d卷积模块de3d和第六1×1×1的3d卷积层处理后的输出再与多尺度时空卷积块cst_de3d的输入相加后输出作为多尺度时空卷积块cst_de3d的输出。
11、所述的时空注意力机制cstm包括通道注意力机制cam、空间注意力机制sam、时间注意力机制tam和残差结构,时空注意力机制cstm的输入首先输入至通道注意力机制cam中处理,处理后的输出和时空注意力机制cstm的输入相乘后获得相乘结果,相乘结果再分别输入至空间注意力机制sam和时间注意力机制tam中处理,空间注意力机制sam和时间注意力机制tam处理后的输出相加后再和相乘结果相乘,然后和时空注意力机制cstm的输入共同输入至残差结构处理后输出作为时空注意力机制cstm的输出。
12、所述的通道注意力机制cam包括全局最大池化层、全局平均池化层第七3d卷积层和第八3d卷积层,将通道注意力机制cam的输入分别输入至全局最大池化层和全局平均池化层中处理,全局最大池化层处理的输出依次输入至第七3d卷积层和第八3d卷积层中处理后输出激活全局最大池化特征图,全局平均池化层处理的输出依次输入至第七3d卷积层和第八3d卷积层中处理后输出激活全局平均池化特征图,激活全局最大池化特征图和激活全局平均池化特征图相加后再和通道注意力机制cam的输入相乘并输出作为通道注意力机制cam的输出。
13、所述的空间注意力机制sam包括全局空间维度最大池化操作层、全局空间维度平均池化操作层和第九3d卷积层,空间注意力机制sam的输入首先分别输入至全局空间维度最大池化操作层和全局空间维度平均池化操作层中处理,处理后的输出进行融合后输入第九3d卷积层中处理后输出作为空间注意力机制sam的输出。
14、所述的时间注意力机制tam包括帧间差分计算层、全局帧差分最大池化操作层、全局帧差分平均池化操作层、第十3d卷积层和第十一3d卷积层,时间注意力机制tam的输入首先输入至帧间差分计算层处理后再分别输出至全局帧差分最大池化操作层和全局帧差分平均池化操作层中处理,处理后的输出进行融合后再依次输入第十3d卷积层和第十一3d卷积层中处理后输出作为时间注意力机制tam的输出。
15、所述的解耦的高效3d卷积模块de3d包括依次连接的1×3×3的深度空间维度3d卷积层、第十二1×1×1的3d卷积层和3×1×1的深度时间维度3d卷积层。
16、深度空间维度3d卷积层为采用分组数量为1、卷积核大小为1×3×3的的3d卷积层;深度时间维度3d卷积层为采用分组数量为1、卷积核大小为3×1×1的3d卷积层。
17、本发明首先对每个动作类别进行预处理,读取动作视频,获取类别标签;其次对每个动作视频进行预处理,采用3dstem特征提取模块对视频帧进行特征提取和下采样获得动作视频的时空特征;本发明设计的时空注意力机制模块ctsm,能够关注到多尺度特征图上的全局时空特征,随后融入的深度可分离的3d卷积模块不仅能够进一步减少整体网络的参数量,还能使得网络能够充分分析多种尺度下的特征图的时空信息,两种的模块的共同作用下,整体网络的性能和效率得到保证。
18、本发明的有益效果是:
19、1)本发明设计的时空注意力机制模块cstm,能够从维度、时间、空间三个维度上关注特征图的在多种尺度下的全局和局部时空特征信息,使得网络能过捕捉动作视频的重点、提高整体网络的性能和准确度。
20、2)本发明设计的解耦的高效3d卷积模块de3d,合理地将传统的3d卷积网络进行解耦,不仅使得卷积操作的参数量得到大幅度下降,同时又保证网络的准确度,使得网络可以在一个很小的体积下发挥更大的效果。
21、3)使用四个多尺度时空卷积块cst_de3d,可以将视频特征图的分析划分成4种不同大小尺寸的特征图阶段进行时空特征分析,使得网络既能捕捉全局时空特征,同时又不遗漏局部时空特征信息,使得网络性能更加优秀。
22、总之,本发明的方法能够分析网络在多个阶段产生的多种尺度的特征图在通道、时间和空间三个维度上的特征信息,从而在这三个维度上提取关键信息。同时,采用全新的深度可分离的3d卷积可以有效减少整体网络的参数量,使得整体网络更加轻量级,进一步提升对视频内容的理解和解释能力,并提高视频动作分类的性能。
- 还没有人留言评论。精彩留言会获得点赞!