基于曼哈顿距离的量子k-means算法的制作方法
本发明涉及量子grover-long方法、量子cal线路和传统k-means聚类方法,属于量子计算和聚类分析相结合的交叉,具体为基于曼哈顿距离的量子k-means算法。
背景技术:
1、随着计算机需要处理的数据量的增加,大数据方法变得越来越重要,大数据方法就像其他的技术革命一样,从效率提升入手,当方法的效率提升了,节省下来了时间,人们便可以利用空闲的时间去做其他更为重要的任务,因此人们迫切需要高效的大数据方法来作为处理数据的工具,当人们从实际问题构建出计算模型时,第一个面对的问题就是如何对海量数据进行准确的分类,大数据方法中的聚类方法便由此应运而生,聚类方法在机器学习领域已经被提出来许多年,也蓬勃发展并且生成了许多不同的分类,根据聚类的不同尺度,方法分为基于划分思想的方法如k-means方法、k-medians方法和kernelk-means方法,基于层次思想的方法如birch方法、cure方法和chameleon方法,基于密度的思想的方法如meanshift方法、dbscan方法和密度峰值聚类方法,基于模型思想的方法如高斯混合模型方法等。
2、其中,k-means方法简单可行,应用效果好,k-means方法是一种基于距离信息的无监督聚类方法,它的目标是将未标记的训练向量集分类成个聚类,在方法的每次迭代过程中,每个训练向量被重新分配到距离自己最近的聚类中心所属的聚类,然后根据当前聚类中的训练向量的情况,重新计算出一个新的聚类中心,因此,在进行了若干次迭代后的聚类,其内部的训练向量之间相似度很高,而不同聚类之间的训练向量的相似度很低,k-means方法的数学原理较为简单,编程实现也较为简单,可扩展性好,适用于大量数据的数据集。
3、值得注意的是,在k-means方法的运行过程中若采用不同的距离度量方法将会直接影响聚类的结果,因此,距离度量的正确选择是确定k-means方法的性质的最关键的步骤之一,距离度量的方法有很多种,如欧氏距离、曼哈顿距离、chebyshev距离、余弦距离、相关系数等,其中最常用的是欧氏距离和曼哈顿距离,它们都计算两个实值训练向量之间的距离,欧氏距离计算的是两个具有浮动值或整数值的训练向量的差的平方和的平方根,而曼哈顿距离计算的是两个训练向量在整数特征空间中的绝对差的和,欧氏距离对描述两个训练向量之间的直线距离较为有用,而曼哈顿距离则对于描述均匀网格上的物体(如棋盘或城市街区)的矢量更为有用,与欧氏距离相比,曼哈顿距离对离群值具有更强的鲁棒性,此外,在计算机图形学中,曼哈顿距离只能通过加减法来计算,大大提高了运算速度,无论累积运算多少次,都不会出现错误,在k-means方法的应用中,如果其应用场景在较为常见的块状街区中时,距离的度量方法使用曼哈顿距离较为妥当,而借助量子计算的技术,可以在量子计算的平台上去实现曼哈顿距离度量的方式,使得方法的效率进一步地提升,因此,在量子k-means方法中成功地应用曼哈顿距离度量方式,是一种较为重要的尝试。
4、量子计算技术的蓬勃发展,是运用量子计算技术去改进经典方法的前提,近几十年来,许多研究者为量子计算技术的发展贡献出了积极的力量,1997年,grover等人以二次速度增长的方式解决了搜索问题,差不多十年后的2009年,harrow等人提出了一种求解线性方程组的方法,在此之后,加速机器学习的量子方法的发展变得越来越迅速,与经典方法相比,量子方法不仅可以解决与经典方法相同的问题,而且运行速度有明显的提高,例如,量子谱聚类方法不仅可以执行与经典聚类方法类似的聚类任务,并且精度非常好,运行的时间更高效,而量子k-means方法则在时间性能,分类精度等方面都要优于经典k-means方法。
5、受到以上成功应用了量子计算技术的方法的启发,本发明提出了qkmm方法,对于在块状的城市街区,或者在网格上的数据集以及游戏棋盘上的数据集进行分类的应用场景,本发明提出的方法可以有效地应用在这些场景中,与使用了量子保真度和量子线路“swap test”实现的欧氏距离不同,本发明中设计了量子线路cal来实现曼哈顿距离的计算,经过多次运算,qkmm方法不仅可以成功地将数据集分为个聚类,并且所消耗的时间更为少量。
6、本发明是一种基于曼哈顿距离的量子k-means聚类方法,其流程基于经典下的k-means聚类方法,经典下的k-means聚类方法具有原理简单,容易实现等优点,经典聚类方法中的距离公式大多都是使用欧氏距离,欧氏距离公式计算的是数据点之间的绝对距离,而在现实的应用场景中,数据点之间有可能有障碍物,或者数据点是存在于块状街区之间的,并不能从直线直接穿过。在这样的应用场景下,欧氏距离并不适用,k-means方法的应用场景受到了限制,这一不足使得经典下的k-means方法无法广泛应用于解决数据点之间存在障碍物的问题。
技术实现思路
1、本发明提供的发明目的在于提供基于曼哈顿距离的量子k-means算法。本发明的聚类方法为qkmm方法,该方法利用量子叠加原理,通过两个量子oracles得到所需的量子态,然后在计算样本数据点与个聚类中心之间的曼哈顿距离的过程中,利用量子线路cal来减少其时间复杂度,接下来,方法巧妙地设置了阈值,以更小的距离标记了数据点,使得需要搜索的范围大大地缩小了,最后,应用grover-long搜索方法找到最合适的聚类中心,并在经典计算机上对样本数据集进行计算,从而更新聚类中心点的值,qkmm方法能有效解决传统的k-means方法在计算两个城市之间的路径信息时或者当两个数据点之间存在障碍物时不适用的问题,并且降低了k-means方法的时间复杂度。
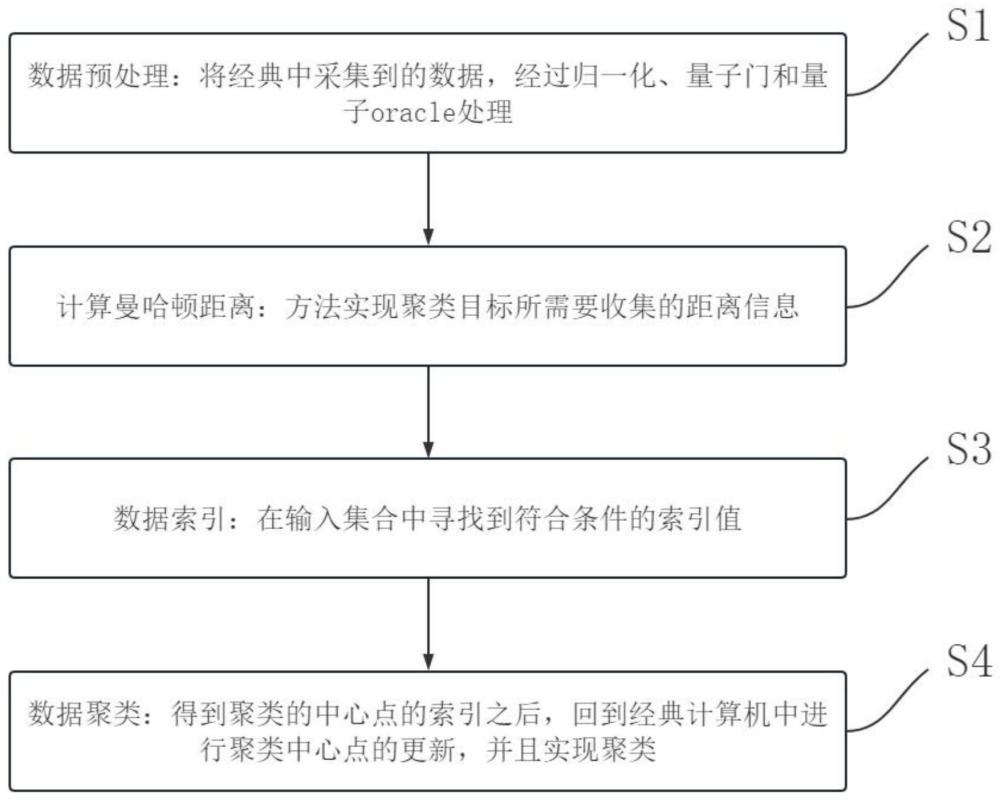
2、为了实现上述时间复杂度较高、搜索范围较大的问题,本发明提供如下技术方案:基于曼哈顿距离的量子k-means算法,包括以下步骤:
3、步骤一、数据预处理:将经典中采集到的数据,经过归一化、量子门和量子oracle处理。
4、步骤二、计算曼哈顿距离:方法实现聚类目标所需要收集的距离信息。
5、步骤三、数据索引:在输入集合中寻找到符合条件的索引值。
6、步骤四、数据聚类:得到聚类的中心点的索引之后,回到经典计算机中进行聚类中心点的更新,并且实现聚类。
7、进一步的,在步骤一中,所述数据预处理即使得数据的范围处在后续方法允许的一个合理的范围内,并且保留了数据之间的关系。
8、进一步的,在步骤一中,所述数据预处理包括数据输入和数据初始化,所述数据初始化包括量子寄存器、hadamard门、量子oracle和量子complement线路。
9、进一步的,在步骤一中,所述hadamard门、量子oracle和量子complement线路对输入数据进行处理,得到包含有计算结果的量子态中,所述量子寄存器将得到的量子态数据进行相应的存储,所述量子寄存器共有六个。
10、进一步的,在步骤s1中,六个所述量子寄存器分别为
11、进一步的,所述步骤一中,第一个量子寄存器将记录聚类中心的维度索引,记为s,第三个量子寄存器记录聚类中心本身的索引,记为j。
12、进一步的,所述步骤一中,第二个量子寄存器将存储下一个训练向量的量子状态,第四个量子寄存器将记录与第一个和第三个量子寄存器的联合索引相对应的聚类中心的相反数。
13、进一步的,所述步骤一中,第五个量子寄存器记录翻转的曼哈顿距离,第六个量子寄存器是一个溢出检测的寄存器。
14、进一步的,所述步骤二中,所述计算曼哈顿距离的方式为运用量子cal线路进行计算,在量子态的状态下,所述计算曼哈顿距离是在量子态上进行的酉算子操作,曼哈顿距离信息都保存在了量子态中。
15、进一步的,所述步骤三中,所述数据索引的方法为运用grover-long方法,所述grover-long方法是改进的grover方法,且grover-long方法可以以完全成功的概率进行寻找。
16、本发明提供了基于曼哈顿距离的量子k-means算法,具备以下有益效果:本发明的聚类方法为qkmm方法,该方法利用量子叠加原理,通过两个量子oracles得到所需的量子态,然后在计算样本数据点与个聚类中心之间的曼哈顿距离的过程中,利用量子线路cal来减少其时间复杂度,接下来,方法巧妙地设置了阈值,以更小的距离标记了数据点,使得需要搜索的范围大大地缩小了,最后,应用grover-long搜索方法找到最合适的聚类中心,并在经典计算机上对样本数据集进行计算,从而更新聚类中心点的值,qkmm方法能有效解决传统的k-means方法在计算两个城市之间的路径信息时或者当两个数据点之间存在障碍物时不适用的问题,并且降低了k-means方法的时间复杂度。
- 还没有人留言评论。精彩留言会获得点赞!