基于TRIZ发明原理的多特征融合中文专利文本分类方法
本发明涉及专利文本分类,具体涉及一种基于triz发明原理的多特征融合中文专利文本分类方法。
背景技术:
1、专利作为创新设计的重要源头,蕴含着丰富的创新发明知识,是当前挖掘创新知识理论的有效途径。技术创新需要学科的交叉融合,面对数量剧增的专利文献,传统的基于学科领域通过专家对专利文本分类进行分类的方法已经满足不了工程师创新的需求,迫切需要一种能够跨学科、跨领域的高效的专利分类方法,为创新设计人员提供更为广泛的知识,扩宽其创新视野,加速创新历程。
2、发明问题解决理论(theory of invention problem solving,triz)是创新设计中重要的理论,其揭示了任何发明创造都遵循着一定的规律,并且不同领域的发明技术矛盾都可以通过一套原理来解决。triz理论将发明创造遵循的共同规律归纳成40个发明原理,这些原理适用于不同领域,针对技术矛盾,创新设计人员可以结合这些发明原理和本领域的工程方法寻求具体的解决方案。国际上常规的专利分类标准主要有国际专利分类法(international patent classification,ipc)、美国专利分类法(u.s.patentclassification,upc/uspc)、欧洲专利分类法(european classification system,ecla)等。基于triz理论的专利文本分类方法不同于国际上常规的专利分类标准,它能够使创新设计人员打破领域的限制,不再局限于在特定领域挖掘专利技术原理,当遇到创新瓶颈时,可以将问题抽象为技术矛盾,通过矛盾矩阵找到发明原理,在应用了相应发明原理的专利中获得启发,产生适合自己发明创造的创新思路和解决方案,提高创新效率和创新效果。
3、与一般文本不同,专利文本具有不同领域的专业术语、句子语义复杂、类别多且各类别的专利文本数量不平衡等特点。这些特点使得专利文本在分类时对文本特征的提取要求高,分类难度大,且专利文本属于文本分类中的长文本,自身的不同层次结构特征往往会被忽视,导致其分类效果差,准确率不高。因此,专利文本需要合适的文本表示和特征提取方法来实现专利文本的高效自动分类。
4、目前深度学习在文本分类研究中的应用越来越多,衍生出众多预训练模型用于文本表示,主要有分为静态预训练模型和动态预训练模型,它们解决了传统词袋模型数据稀疏、丢书语义等信息的弊端。其中静态预训练模型主要包括:word embeddings(word2vec)、global vectors for wordrepresentation(glove)和fasttext。这类预训练模型在预训练过程中,文本的向量表示是固定的,不能随上下文的变化而改变,在某些特定的任务上具有一定的局限性。动态预训练模型主要包括embeddings from language models(elmo)、generative pre-trained transformer(gpt)、bidirectional encoder representationfrom transformers(bert),这类预训练模型在预训练过程中,文本的向量表示能够随上下文信息的变化而改变,更好地适应不同的任务。bert模型的训练效果有了大步幅的提升,随之带来的问题就是训练参数过多、时间过长。lan等人基于bert预训练语言模型进行了改进,提出了一种轻量级预训练语言模型albert模型,其内部与bert模型一致,均采用双向transfomer编码器,使得参数量有了大幅度降低,运行速度也有了显著提升,并且在众多nlp任务上都有着出色的表现。
5、在特征提取方面,主要有卷积神经网络(convolutionneural networks,cnn)、循环神经网络(recurrent neural networks,rnn)、图神经网络(graph neural networks,gnn)等以及它们的变种。使用神经网络模型自动从文本中提取信息特征,解决了机器学习中需要手动提取文本特征的弊端。kim基于原始的卷积神经网络提出textcnn,用于捕捉文本中的局部信息,但由于它是单向的,无法从正反两个方向提取全面的信息,并且无法考虑长距离文本之间的语义联系。bigru是一种基于bilstm的变体,它们都是基于rnn的改进模型。gru单元在lstm单元的基础上做了部分改进,只由重置门和更新门组成,拥有更少的参数,更快的训练速度,在一定程度上防止了过拟合。bigru能够很好的提取文本中的全局上下文语义特征,但是又忽略了局部的关键字符特征,故单独使用以上方法缺乏一定的适用性。
6、基于上述基于triz理论的专利文本分类的需求及深度学习在处理文本分类上的优势,为应对术语丰富、语义结构复杂、类别众多的中文专利,深入挖掘其中蕴含的理论知识,打破不同领域创新的隔离性,缩短创新设计人员发明进程,本发明预涉及一种基于triz发明原理的多特征融合中文专利文本分类方法。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于triz发明原理的多特征融合中文专利文本分类方法。
2、本发明的上述目的通过以下技术方案来实现:
3、一种基于triz发明原理的多特征融合中文专利文本分类方法,该方法包括如下步骤:
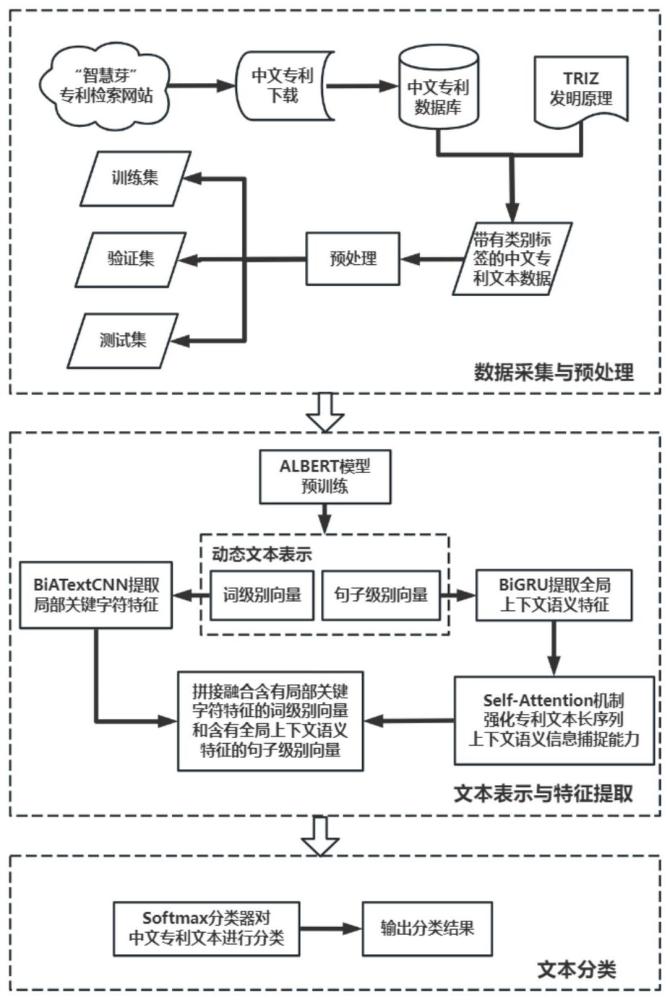
4、s1:准备原始中文专利文本数据,进行数据预处理后作为中文专利文本分类数据集,将数据集分为训练集、验证集和测试集,用于triz_mfpm模型的训练;
5、s2:构建triz_mfpm模型,包括albert动态预训练模型、改进的双向卷积神经网络模型biatextcnn、双向门控循环神经网络模型bigru和自注意力机制模块self-attention;
6、s3:将s1中处理得到的数据集中的中文专利文本输入到albert模型,输出动态的词级别向量和句子级别向量;
7、s4:将s3输出的词级别向量输入到biatextcnn模型进行特征提取,提取含有局部关键字符信息特征;
8、s5:将s3输出的句子级别向量输入到bigru模型进行特征提取,捕捉含有上下文深层语义信息特征,并将其输出结果输入到self-attention机制中,使模型着重关注专利文本长序列中的相关性,提升捕捉上下文语义能力,更好地提取句子语义特征;
9、s6:采取并行拼接的方式将s4输出的含有局部关键字符特征的词级别向量和s5输出的含有全局上下文句子语义特征的句子级别向量进行拼接融合,得到多层次的中文专利文本向量表示;
10、s7:使用softmax分类器计算中文专利文本所属发明原理类别的概率分布,经过多轮训练得到以40条triz发明原理为分类标准的triz_mfpm模型;
11、s8:将需要分类的专利文本进行处理后输入到s7中训练好的triz_mfpm模型完成专利分类任务。
12、而且,s1中,每篇专利选取40条triz发明原理中一个主要的发明原理进行类别标记来获取的,并将其标题和摘要作为原始数据进行数据的预处理,最后按照14:3:3比例分为训练集、验证集和测试集。
13、而且,所述s3中的albert模型是一种基于bert模型的轻量级预训练语言模型,其输入向量是由token embedding、segment embedding和position embedding共同组成的,并采用双向transformer编码器通过多头自注意力机制对中文专利文本进行动态文本向量化表示,得到词级别向量和句子级别向量。
14、而且,所述s4中的biatextcnn模型是在textcnn模型的基础上改进后的双向卷积神经网络模型,由词嵌入层、双向卷积层、注意力层、池化层、拼接层和全连接层组成,其中双向卷积层由正向和反向卷积核组成,池化操作采用的是max-pooling方法。
15、而且,所述s5中的bigru模型是双向门控循环神经网络模型,是lstm模型的一种变体;每个gru单元由重置门和更新门组成,重置门用于控制是否保留上一时刻的状态到当前时刻的状态,更新门用于控制上一时刻的状态有多少被加入到当前时刻的状态。
16、本发明具有的优点和积极效果为:
17、1、本发明将triz发明原理作为分类标准用于中文专利文本分类,辅助创新设计人员方便快捷地从不同领域获取创新过程中遇到问题的矛盾来源,并结合发明原理和本领域工程方法来解决问题,加快创新进程;以albert模型为基础进行中文专利文本分类,使用改进的双向卷积神经网络、双向门控循环神经网络和自注意力机制在动态的中文专利词级别向量和句子级别向量上进行学习,提取含有局部关键字符特征的词向量和含有全局上下文语义特征的句子向量,并将两者拼接融合得到多层次中文专利文本向量表示。本技术中的triz_mfpm模型在中文专利文本分类中的准确率为78.62%,超过在albert模型上使用单一神经网络模型的准确率,证明了本实施例模型的优势。
18、2、本发明提出一种基于triz发明原理的多特征融合中文专利文本分类方法,该方法使用albert模型对中文专利文本进行动态化向量表示,提高文本向量的表征能力,得到动态的词级别向量和句子级别向量;在下游分类任务中,对textcnn进行改进得到双向卷积神经网络,对词向量中的关键字符特征进行提取,打破原始textcnn只能使用单向卷积核提取特征的弊端,使用多个不同大小的正向和反向卷积核在专利文本词向量矩阵上分别以正序、逆序滑动、以此来提取双向局部特征,并在进入池化层之前加入注意力层来增强模型区分能力,进一步提升模型对专利文本局部特征中关键信息的关注度,更好地提取专利文本向量中的局部关键字符特征;使用bigru模型对句子向量中的全局上下文语义等特征进行提取,并加入self-attention机制优化输入权重,使模型着重关注专利文本长序列中的相关性,提升捕捉上下文语义能力,更好地提取句子语义特征;将处理得到的词向量和句子向量进行拼接融合得到更为全面的文本向量表示,解决了传统专利文本分类中文本向量表示中信息欠缺的问题。
- 还没有人留言评论。精彩留言会获得点赞!