提升知识库长文本问答准确率的方法与流程
本发明涉及信息处理,具体地,涉及一种提升知识库长文本问答准确率的方法。
背景技术:
1、当前知识库问答系统正不断快速发展与演进,并且应用到私有化领域,取得了长足的进步。知识库问答的主要任务是:给定自然语言问句,计算机能够自动的基于知识库中的知识回答该问题。常见的知识库有freebase,dbpedia,wikidata等等。知识在知识库中的存在形式为三元组的形式(s,p,o),其中s代表主语实体,o代表宾语实体,p代表主语实体和宾语实体之间的关系谓语。
2、目前的中文知识库问答主要分为两类。一类是通过大量的特征与模型结合来实现,回答准确度高,但使用的模型和特征较为复杂,很难落地在实际场景。另外一类是针对不同的特定场景定制问答服务,这些问答服务广泛应用于智能客服、机器人等领域。
3、但是,在处理长文本时,通常会面临一些挑战和问题,包括信息计算过载、处理效率低、耗时长,回答不准确等。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种提升知识库长文本问答准确率的方法。
2、第一方面,本申请实施例提供一种提升知识库长文本问答准确率的方法,包括:
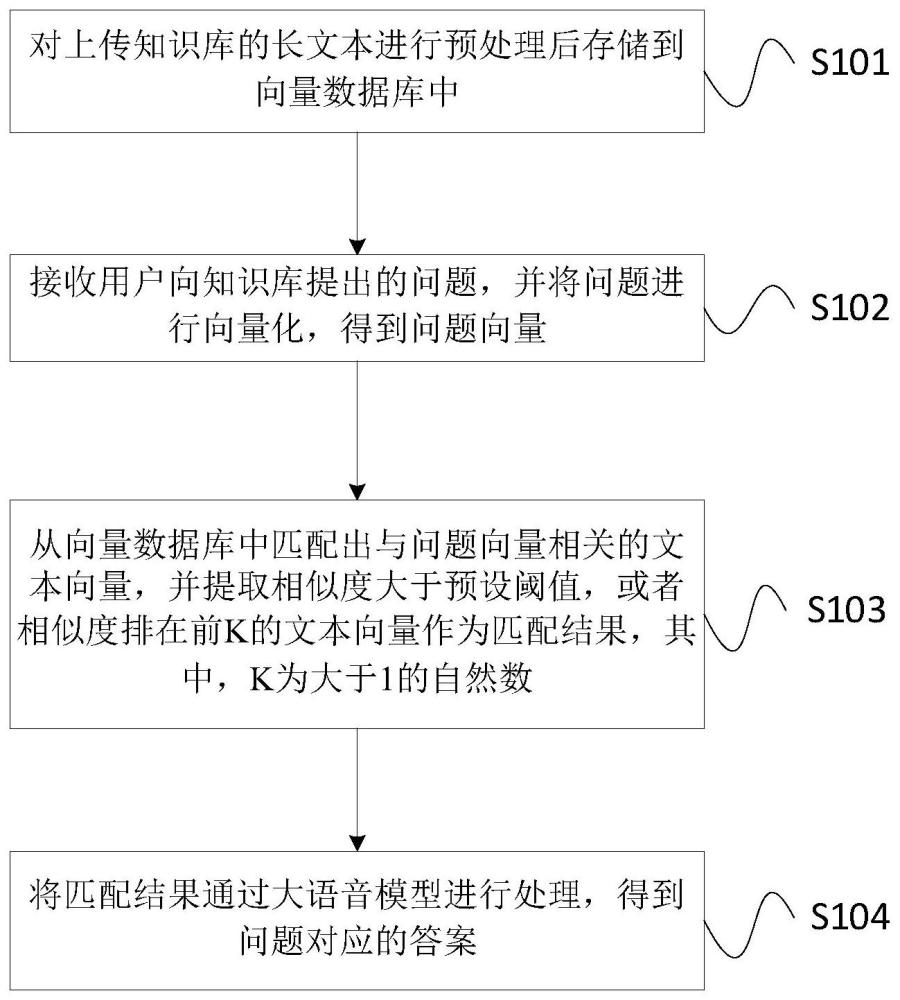
3、步骤1:对上传知识库的长文本进行预处理后存储到向量数据库中;
4、步骤2:接收用户向知识库提出的问题,并将问题进行向量化,得到问题向量;
5、步骤3:从向量数据库中匹配出与所述问题向量相关的文本向量,并提取相似度大于预设阈值,或者相似度排在前k的文本向量作为匹配结果,其中,k为大于1的自然数;
6、步骤4:将所述匹配结果通过大语音模型进行处理,得到问题对应的答案。
7、可选地,所述步骤1包括:
8、将长文本上传到知识库中;
9、对长文本进行预处理,以转换为标准的文本格式;
10、对转换格式后的长文本进行分层处理,并将长度大于设置值的段落分割成一个个小段落和句子;
11、当所述长文本被读取时,通过上下文建模捕捉文本中的语境信息;
12、将所述语境信息进行向量化,得到文本向量,并将所述文本向量存储到向量数据库中。
13、可选地,当上传的所述长文本涉及到多个不同的专业领域时,分别在不同的领域对大语音模型进行优化调整。
14、可选地,在对转换格式后的长文本进行分层处理之前,所述方法还包括:
15、添加长文本注意力机制,用以帮助提取长文本中的关键信息。
16、可选地,还包括:
17、当生成的答案超过设定的长度时,对所述答案进行再次匹配,以提取出关键信息;
18、根据所述关键信息,生成长度不超过设定的目标答案。
19、第二方面,本申请实施例提供一种提升知识库长文本问答准确率的装置,包括:
20、预处理模块,用于对上传知识库的长文本进行预处理后存储到向量数据库中;
21、问题处理模块,用于接收用户向知识库提出的问题,并将问题进行向量化,得到问题向量;
22、匹配模块,用于从向量数据库中匹配出与所述问题向量相关的文本向量,并提取相似度大于预设阈值,或者相似度排在前k的文本向量作为匹配结果,其中,k为大于1的自然数;
23、答案生成模块,用于将所述匹配结果通过大语音模型进行处理,得到问题对应的答案。
24、可选地,所述预处理模块,具体用于:
25、将长文本上传到知识库中;
26、对长文本进行预处理,以转换为标准的文本格式;
27、对转换格式后的长文本进行分层处理,并将长度大于设置值的段落分割成一个个小段落和句子;
28、当所述长文本被读取时,通过上下文建模捕捉文本中的语境信息;
29、将所述语境信息进行向量化,得到文本向量,并将所述文本向量存储到向量数据库中。
30、可选地,还包括:优化调整模块,用于在上传的所述长文本涉及到多个不同的专业领域时,分别在不同的领域对大语音模型进行优化调整。
31、可选地,还包括:注意力机制模块,用于添加长文本注意力机制,用以帮助提取长文本中的关键信息。
32、可选地,还包括:答案处理模块,用于在生成的答案超过设定的长度时,对所述答案进行再次匹配,以提取出关键信息;
33、根据所述关键信息,生成长度不超过设定的目标答案。
34、第三方面,本申请实施例提供一种提升知识库长文本问答准确率的设备,包括:处理器和存储器,所述存储器中存储有可执行的程序指令,所述处理器调用所述存储器中的程序指令时,所述处理器用于:
35、执行如第一方面中任一项所述的提升知识库长文本问答准确率的方法的步骤。
36、第四方面,本申请实施例提供一种计算机可读存储介质,用于存储程序,所述程序被执行时实现如第一方面中任一项所述的提升知识库长文本问答准确率的方法的步骤。
37、与现有技术相比,本发明具有如下的有益效果:
38、本申请,通过对上传知识库的长文本进行预处理后存储到向量数据库中,接收用户向知识库提出的问题,并将问题进行向量化,得到问题向量;从向量数据库中匹配出与问题向量相关的文本向量,并提取相似度大于预设阈值,或者相似度排在前k的文本向量作为匹配结果,其中,k为大于1的自然数;将匹配结果通过大语音模型进行处理,得到问题对应的答案。从而能够更加迅速地从长文本中捕捉到语境信息,减轻模型对长序列的处理负担,提高整体计算效率,并提升长文本问答的准确性。
技术特征:
1.一种提升知识库长文本问答准确率的方法,其特征在于,包括:
2.根据权利要求1所述的提升知识库长文本问答准确率的方法,其特征在于,所述步骤1包括:
3.根据权利要求2所述的提升知识库长文本问答准确率的方法,其特征在于,当上传的所述长文本涉及到多个不同的专业领域时,分别在不同的领域对大语音模型进行优化调整。
4.根据权利要求2所述的提升知识库长文本问答准确率的方法,其特征在于,在对转换格式后的长文本进行分层处理之前,所述方法还包括:
5.根据权利要求1-4中任一项所述的提升知识库长文本问答准确率的方法,其特征在于,还包括:
6.一种提升知识库长文本问答准确率的装置,其特征在于,包括:
7.根据权利要求6所述的提升知识库长文本问答准确率的装置,其特征在于,所述预处理模块,具体用于:
8.根据权利要求7所述的提升知识库长文本问答准确率的装置,其特征在于,还包括:优化调整模块,用于在上传的所述长文本涉及到多个不同的专业领域时,分别在不同的领域对大语音模型进行优化调整。
9.一种提升知识库长文本问答准确率的设备,其特征在于,包括:处理器和存储器,所述存储器中存储有可执行的程序指令,所述处理器调用所述存储器中的程序指令时,所述处理器用于:
10.一种计算机可读存储介质,用于存储程序,其特征在于,所述程序被执行时实现权利要求1至7任一项所述的提升知识库长文本问答准确率的方法的步骤。
技术总结
本发明提供了一种提升知识库长文本问答准确率的方法,包括:对上传知识库的长文本进行预处理后存储到向量数据库中,接收用户向知识库提出的问题,并将问题进行向量化,得到问题向量;从向量数据库中匹配出与问题向量相关的文本向量,并提取相似度大于预设阈值,或者相似度排在前K的文本向量作为匹配结果,其中,K为大于1的自然数;将匹配结果通过大语音模型进行处理,得到问题对应的答案。从而能够更加迅速地从长文本中捕捉到语境信息,减轻模型对长序列的处理负担,提高整体计算效率,并提升长文本问答的准确性。
技术研发人员:张宋伟,唐杰,王宗宝,戴立言
受保护的技术使用者:上海网达软件股份有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!