一种基于因果推断的本科生毕业去向预测方法与可视分析系统
背景技术:
1、本科生毕业后的首次毕业去向(后面简称毕业去向)是其职业生涯的起点,对于他们终身职业发展至关重要。然而,毕业去向的选择对本科生来说是一项复杂的任务,因为受到许多因素的影响,尤其是能力因素,如他们所获得的知识和技能水平,包括专业基础、英语水平和实际技能等。这些能力因素通常可以通过gpa(平均绩点)、各种课程的成绩、英语四级(cet4)分数、毕业设计成果等来表征。探索本科生课程成绩与他们毕业去向之间的因果关系,并帮助他们预测毕业后的首次毕业去向,对学生个人职业规划和高校人才培养计划的改进非常有用。
2、通常在本科学习的整个过程中,学生需要在四年或八个学期内完成约70门课程,并达到特定的学分要求和评估标准。从入学到毕业,每个学生都会积累一系列基本的个人信息、学业表现和毕业去向等数据。随着多年来各个专业的毕业生信息积累,形成了一个庞大的毕业去向和学业表现数据集,为探索学业表现与毕业去向之间的关联以及预测毕业去向奠定了数据基础。然而,这类数据的高维度、相关性和非线性特点也给分析和预测带来了巨大挑战。
3、近年来,人工智能、数据挖掘和可视化技术在预测和分析领域取得了显著进展,为解决这个问题奠定了技术基础。在以往的研究中,已经提出了多种方法,用于预测和分析本科毕业生的职业发展。然而,以往的方法通常忽略了不同因素之间的因果关系,导致模型在本科生毕业去向预测结果的精确性和可解释性方面受到限制。此外,当前的研究侧重于模型的预测能力,对模型结果的可视化关注较少,这一限制妨碍了用户理解模型和全面分析本科生就业去向预测结果。
技术实现思路
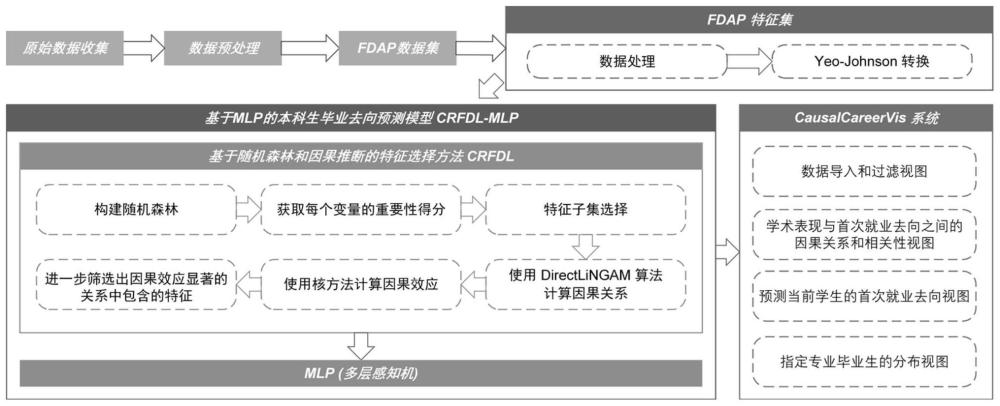
1、为了解决上述技术问题,本发明提供了一种基于因果推断的本科生毕业去向预测方法与可视分析系统。该方法主要包括:数据预处理与(第一去向与学业表现,the firstdestination and academic performance)fdap数据集构建、对fdap数据集进行特征增强操作得到fdap特征集、应用基于随机森林和因果推断的特征选择方法(crfdl,causalrandom forest with directlingam)进行特征筛选、构建基于多层感知机(mlp)的本科生毕业去向预测模型(crfdl-mlp)、对模型的有效性进行评估;之后就可以利用该模型预测本科生的毕业去向(包括读研、出国、就业、自由职业、待业)。
2、本发明还提供了一种基于因果推断的本科生毕业去向预测可视分析系统,该系统提供了关于本科生的学业表现与毕业去向之间因果关系和相关性的综合分析,并能够根据学生当前学业表现准确预测其毕业去向。通过案例研究证明了该方法的有效性和实用性。
3、本发明提供的技术方案如下:
4、一种基于因果推断的本科生毕业去向预测方法,具体包括如下步骤:
5、a.数据预处理与fdap数据集构建。
6、将原始数据进行数据清洗和数据转换,并将经过预处理的数据集定义为毕业去向与学业表现(fdap)数据集(以下内容提到的数据均为二维表形式,每行代表一名学生记录,每列代表学生具有的属性)。具体方法如下:
7、a1:使用z-score方法来检测和处理异常值。具体地,首先计算原始数据集中每个属性(课程成绩)的均值μ和标准差σ,然后计算该属性中每条记录相对于该属性均值的偏差值,即z-score:
8、
9、其中,xij是第i个学生的第j门课程的成绩,zij是对应的z-score值。根据高斯分布的性质,大约68%的数据应该位于均值加减一个标准差的范围内,而95%的数据应该位于均值加减两个标准差的范围内。因此,将超过3个标准差的课程成绩视为异常值,并将其从数据集中删除。
10、a2:处理空缺值和删除冗余特征。在此步骤中,首先筛选并删除缺失“毕业去向”数据的学生学业数据,每行代表一个学生的学业数据。然后删除缺失学生课程成绩超过整列70%的课程特征,每列代表学生课程。最后,用0填充缺失数据。
11、a3:将原始的“毕业去向”数据由细化的数据总结替换成5个毕业去向,包括读研、出国、就业、自由职业和待业,并使用one-hot编码进行转换,将5个毕业去向分别用5个二进制属性表示。
12、a4:使用z-score标准化方法对学生学业表现数据集中课程成绩数据进行标准化,使得数据符合标准正态分布,即均值为0,标准差为1。具体步骤是,先计算原始数据集中每个属性的均值μ和标准差σ,然后对每个xij减去均值,再除以标准差,最后得到标准化后的zij,即z-score。
13、由此得到fdap数据集,包括本科生的个人信息、大学四年内的学业表现以及毕业后的首次就业去向信息。其中,(1)个人信息包括:学生id、姓名、性别、专业、班级、生源地等;(2)学业表现信息包括:大学四年内每门课程的成绩、每门课程的学分、总学分、gpa(平均绩点)、cet4、cet6(大学英语六级成绩)等;(3)毕业去向包括:读研、出国、就业、自由职业和待业(读研指的是在中国的研究生学习,而出国指的是在国外的研究生学习或就业),毕业年份,就业单位以及所属行业。fdap数据集的矩阵形式如式(2)所示:
14、
15、假设fdap数据集中有n个学生的数据记录,每条记录有m个属性。其中,前k个属性是个人信息,中间l个属性是学业表现信息,最后5个属性是毕业去向信息。
16、b.对fdap数据集进行特征增强操作得到fdap特征集。
17、为了提高模型处理非线性关系的能力,对fdap数据集中的学业表现(成绩)数据使用yeo-johnson转换将非高斯属性转化为更接近高斯分布的结构,经过处理得到fdap特征集(fdap feature set)。yeo-johnson转换如公式(3)所示,
18、
19、转换后得到的fdap特征集矩阵如公式(4)所示:
20、
21、其中,xnl代表学业表现数据(式(2)中的academic矩阵)的第n行第l列的元素,ynl=f(xnl,λl)代表转换后的元素(式(4)中的academic′矩阵),λl是转换参数,可以通过最大似然法估计。式(3)中,academic′是经过yeo-johnson转换后的学业表现数据,是转换后矩阵中的第n行第l列的元素,λl是第l个属性的转换参数。
22、c.应用基于随机森林和因果推断的特征选择方法(crfdl)进行特征筛选。
23、(1)第一阶段:对fdap特征集使用随机森林计算academic′矩阵中每个属性相对于目标属性(fdap特征集中的destination矩阵)的重要性得分,如公式(5)所示:
24、
25、其中,ij是第j个属性的重要性得分,n是学生数量,fj是随机森林中的评估函数,是第i个学生的第j个属性的值,di是第i个学生的目标属性值(即destination矩阵中的一行)。对于每个属性,计算它与目标属性的相关性,然后取所有学生样本的平均值作为该属性的重要性得分。重要性得分越高,说明该属性对于预测目标属性(毕业去向)越有贡献。使用信息增益作为评估函数fj,信息增益计算方法如下:
26、
27、其中,h(di)是第i个学生样本的目标属性(毕业去向)的熵,是在给定第i个学生样本的第j个属性值的条件下,目标属性的条件熵。信息增益越大,说明属性值对目标属性的影响越大。熵和条件熵的计算方法如下:
28、
29、
30、其中,pk是第i个学生样本的目标属性为第k个类别的概率,vj是第j个属性的取值集合,是第i个学生样本的第j个属性值为v的概率,是在给定第i个学生样本的第j个属性值为v的条件下,目标属性的熵。
31、最终,将academic′矩阵中每个属性的重要性得分降序排序,选取前90%个得分最高的属性,形成rf数据集,用于输入到第二阶段的directlingam算法。rf数据集可以用如下矩阵表示:
32、
33、其中,s是筛选出的属性的个数,j1,j2,...,js是按重要性得分降序排列的属性的索引。这个矩阵的意义是,只保留了对目标属性有较大贡献的属性,从而减少了数据的维度和噪声,提高了第二阶段directlingam算法的效率和准确性。
34、(2)第二阶段:使用directlingam算法构建rf数据集的因果结构,得到因果效应矩阵。
35、首先,将rf数据集中的所有属性作为候选属性集。对于候选属性集中的每个属性,使用核方法计算其与其他属性的差分互信息,以获得因果顺序,并选择差分互信息最大的属性作为当前因果关系的起点。差分互信息的计算公式如下:
36、
37、其中,yi和yj表示rf数据集中的属性(i≠j),表示yi和yj的核矩阵,|·|表示行列式。差分互信息可以衡量两个属性之间的非线性相关性,越大表示越相关。核方法是一种非参数的统计方法,可以用来估计非线性的互信息。
38、每次选择因果顺序后,算法都会根据最大熵原则计算并更新当前因果关系之外的其他属性与起始属性的残差,以减少重复因果关系对下一次选择的影响。最大熵原则的含义是,在满足已知条件的情况下,选择熵最大的概率分布作为最优解。残差的计算公式如下:
39、
40、其中,表示第i个属性的残差,pi表示已经确定的yi的父节点集合(也就是影响yi的其他属性),表示yj对yi的回归系数(也就是属性yj对属性yi的影响程度)。
41、然后,从候选属性集中删除起始属性,并更新候选属性集,直到确定所有属性的因果关系。然后,计算出一个邻接矩阵来表示属性之间的因果关系。该矩阵的每个元素都表示一个属性是否与另一个属性存在因果关系。邻接矩阵的计算公式如下:
42、
43、aij为邻接矩阵a的元素,根据属性的因果系数来判断属性i和属性j是否有因果关系。如果不等于0,说明属性j对属性i有因果影响,那么邻接矩阵的元素aij就为1;如果等于0,说明属性j对属性i没有因果影响,那么邻接矩阵的元素aij就为0。
44、最后,算法返回因果效应矩阵w,并根据w绘制因果网络g。因果效应矩阵的每个元素都表示一个属性对另一个属性的因果效应的大小。因果效应矩阵的计算公式如下:
45、w=(z1,z2,...,zs)=(i-a)-1b (13)
46、其中,i表示单位矩阵,a表示邻接矩阵,b表示回归系数矩阵。因果效应矩阵w的元素wij表示第i个属性对第j个属性的总因果效应,包括直接和间接的影响。
47、假设rf数据集矩阵包含四个科目,那么可以得到如下类似的因果效应矩阵:
48、
49、这表示,科目1对其他科目都有正向影响,科目2对科目3和科目4有正向的影响,科目3对科目4有负向的影响。
50、(3)在构建因果网络的过程中,进一步筛选出因果效应显著的关系中包含的属性,为下一步构建crfdl-mlp模型提供训练集和测试集。
51、首先,使用hsic(hilbert-schmidt independence criterion,希尔伯特-施密特独立准则)检验,得出每对属性之间因果效应的显著性检验p值,表示属性之间的因果关系是否显著。hsic检验的计算公式如下:
52、
53、其中,x和y是两个误差变量,n是学生样本数,k和l是分别由x和y的核函数计算的gram矩阵,h是中心化矩阵,即其中i是单位矩阵,1是全1向量,tr(·)是矩阵的迹运算。x和y是原始数据rf的两个属性与邻接矩阵a的乘积之差,即:
54、x=en,i=rfn,i-(a·rft)n,i (16)
55、y=en,j=rfn,j-(a·rft)n,j (17)
56、其中,i和j是两个不同的属性索引,n表示所有的学生样本,e是误差变量矩阵,rf是原始数据矩阵,a是公式(12)得到的邻接矩阵,rft是rf的转置,en,i和rfn,i分别表示e和rf的第i列,(a·rft)n,i表示(a·rft)的第i列。
57、然后,设定一个临界值,通常p-value<0.05表示因果效应显著。根据p值和阈值的比较,将因果效应矩阵中p-value≥0.05的元素设为0,以排除那些不显著的因果关系。至此得到的rf*矩阵如下所示:
58、
59、其中,q是经过筛选出具有显著因果效应的关系中包含的属性个数。
60、d.构建基于多层感知机的本科生毕业去向预测模型(crfdl-mlp)。
61、crfdl-mlp模型是一种结合了因果推断与深度学习的新型预测模型。经过对fdap特征集使用基于随机森林和因果推断的特征选择方法(crfdl)进行特征筛选后,得到fdap重要特征集,为构建crfdl-mlp模型提供训练集和测试集。至此fdap重要特征集(fdapfeature set*)可以用如下矩阵表示:
62、
63、crfdl-mlp的神经网络结构包括一个输入层、四个隐藏层和一个输出层。输入层输入rf*和destination矩阵的数据,神经元数量为q+5个,使用relu激活函数。前三个隐藏层分别包含256、128和64个神经元,都使用relu激活函数,并使用批归一化和dropout层来防止过拟合。第四个隐藏层包含32个神经元,同样使用relu激活函数。输出层的神经元数量为5个,代表五个毕业去向,使用softmax激活函数。
64、crfdl-mlp模型使用relu和softmax激活函数,缓解了梯度消失问题。softmax用于输出层以实现概率分布。在训练过程中,使用交叉熵损失作为优化目标,并使用adam优化器来优化神经网络的权重和偏置。为了防止过拟合,添加了批归一化和dropout层。
65、crfdl-mlp模型训练的具体计算过程如下:
66、假设输入层的数据为x∈rn×(q+5),其中n是样本数,q是rf*矩阵的列数。输出层的目标向量为y∈rn×5,其中每一行是一个one-hot编码的向量,表示某个学生的毕业去向。
67、输入层到第一个隐藏层的权重矩阵为w1∈r(q+5)×256,偏置向量为b1∈r256。第一个隐藏层的激活函数为relu,即f1(x)=max(0,x)。则第一个隐藏层的输出为z1=f1(xw1+b1)。
68、第一个隐藏层到第二个隐藏层的权重矩阵为w2∈r256×128,偏置向量为b2∈r128。第二个隐藏层的激活函数也为relu,即f2(x)=max(0,x)。则第二个隐藏层的输出为z2=f2(z1w2+b2)。
69、第二个隐藏层到第三个隐藏层的权重矩阵为w3∈r128×64,偏置向量为b3∈r64。第三个隐藏层的激活函数也为relu,即f3(x)=max(0,x)。则第三个隐藏层的输出为z3=f3(z2w3+b3)。
70、第三个隐藏层到第四个隐藏层的权重矩阵为w4∈r64×32,偏置向量为b4∈r32。第四个隐藏层的激活函数也为relu,即f4(x)=max(0,x)。则第四个隐藏层的输出为z4=f4(z3w4+b4)。
71、第四个隐藏层到输出层的权重矩阵为w5∈r32×5,偏置向量为b5∈r5。输出层的激活函数为softmax,即则输出层的输出为
72、为了优化模型的参数,需要定义一个损失函数来衡量模型的预测与真实标签之间的差异。由于输出层使用了softmax激活函数,可以采用交叉熵损失函数,其定义如下:
73、
74、其中,yij表示第i个样本的第j个标签,表示第i个样本的第j个预测值。交叉熵损失函数可以衡量两个概率分布之间的相似度,越小表示越相似。
75、为了最小化损失函数,需要使用梯度下降法来更新模型的参数。梯度下降法的更新公式如下:
76、
77、其中,θ表示任意的模型参数,η表示学习率,表示损失函数对参数的偏导数,也就是梯度。为了计算梯度,需要使用反向传播算法,即从输出层开始,逐层计算损失函数对每个参数的偏导数,并将其传递给前一层,直到输入层。反向传播算法的具体步骤如下:
78、a)计算输出层的误差其中和y都是n×5的矩阵。
79、b)计算输出层的梯度其中δ5i表示δ5的第i行。
80、c)计算第四个隐藏层的误差δ4=w5δ5⊙f4′(z4w5+b5),其中⊙表示哈达玛积,即对应元素相乘,f4′表示relu函数的导数,即f4′(x)=1,如果x>0,否则为0。
81、d)计算第四个隐藏层的梯度
82、e)重复上述过程,计算第三个、第二个和第一个隐藏层的误差和梯度,直到得到所有参数的梯度。
83、f)使用梯度下降法更新所有参数,即其中k=1,2,3,4,5。
84、本方法中主要优化的参数包括:
85、(1)神经元数量(neurons):即隐藏层中的神经元数量,包括每个隐藏层的神经元数量。可以考虑在不同的隐藏层中设置不同数量的神经元。
86、(2)批处理大小(batch size):训练时每个小批量的样本数。不同的批处理大小可能会影响收敛速度和模型性能。
87、(3)迭代次数(epochs):训练的迭代次数,即整个数据集被传递给神经网络的次数。
88、(4)学习率(learning rate):adam优化器的学习率,它控制参数更新的步长。学习率过大可能导致震荡,而学习率过小可能导致收敛缓慢。
89、(5)正则化参数(regularization):l2正则化参数,用于控制模型的复杂度,防止过拟合。
90、e.对本科生毕业去向预测模型crfdl-mlp的性能和可解释性进行评估。
91、e1.使用准确度、精确度、召回率、f1分数、roc曲线下的面积(auc),比较和评估crfdl-mlp模型与四个现有基准预测模型(朴素贝叶斯、逻辑回归、支持向量机和随机森林分类器)在fdap特征集上的性能。
92、(1)accuracy(准确率):是指分类模型正确预测的样本数占总样本数的比例。计算公式为:
93、
94、其中,tp(真正例)是指实际为正例且预测为正例的样本数,tn(真反例)是指实际为反例且预测为反例的样本数,fp(假正例)是指实际为反例但预测为正例的样本数,fn(假反例)是指实际为正例但预测为反例的样本数。
95、(2)precision(精确率):是指分类模型预测为正例的样本中实际为正例的比例。计算公式为:
96、
97、精确率反映了模型预测正例的准确性,越高表示越少出现假正例。
98、(3)recall(召回率):是指分类模型预测出的正例占实际正例的比例。计算公式为:
99、
100、召回率反映了模型预测正例的完整性,越高表示越少漏掉真正例。
101、(4)f1-score(f1值):是指精确率和召回率的调和平均数,用于综合评价模型的性能。计算公式为:
102、
103、f1值越高表示模型的精确率和召回率都越高,平衡了两者之间的权重。
104、(5)auc(area under curve):是指roc曲线(receiver operatingcharacteristic curve)下的面积,用于评价二分类模型的性能。roc曲线是以假正例率(false positive rate,fpr)为横轴,真正例率(true positive rate,tpr)为纵轴绘制的曲线,反映了模型在不同阈值下的分类效果。计算公式为:
105、auc=∫01t pr(fpr)dfpr (26)
106、auc越接近1表示模型的性能越好,越接近0.5表示模型的性能越差。
107、e2.使用shap值指标来评估crfdl-mlp模型的可解释性。
108、shapley additive explanations(简称shap)是一种基于博弈论的方法,用于解释任何机器学习模型的输出。shap值是一种衡量每个属性对预测的贡献的指标,它是所有可能的属性子集中属性的平均边际贡献。计算公式为:
109、
110、其中,n是所有属性的集合,s是任意属性子集,j是某个属性,v(s)是模型在属性集合s上的预测值,φj是属性j的shap值,即对预测值的贡献。
111、本发明还提供了一个基于因果推断的本科生毕业去向预测可视分析系统causalcareervis。该系统由四个主要视图组成:数据导入和过滤视图、当前在校学生毕业去向预测视图、学业表现与毕业去向之间的因果关系和相关关系视图(包括:学业表现的因果网络和课程与毕业去向之间的相关性子视图)以及指定专业毕业生的毕业去向分布视图(包括:毕业去向列表,从2016年到2022年的毕业去向分布子视图)。该系统提供了关于学业表现与本科生毕业去向之间的因果关系和相关性的综合分析,并通过案例研究证明该方法的有效性和实用性,能够准确预测本科生的毕业去向。具体地:
112、(1)数据导入和过滤视图:用户可以下载学生学业成绩数据模板,并将符合格式要求的数据上传到系统中。当用户从系统的导航栏中选择一个专业时,相关的视图就会显示出来;
113、(2)当前在校学生毕业去向预测视图:展示了一个堆叠条形图,显示了每位学生选择五个毕业去向之一的概率。使用crfdl-mlp模型来预测学生的毕业去向,五种颜色分别代表五个毕业去向。水平轴表示概率,柱形中特定颜色的面积越大,学生选择该毕业去向的概率越高。垂直轴显示学生的id,每个柱形代表一个被预测的学生;
114、(3)学业表现与毕业去向之间的因果关系和相关性视图:该视图包括力导向布局图和矩阵热图。力导向布局图显示了crfdl方法获得的学业表现和毕业去向之间的因果关系的有向图,其中起始节点表示原因,目标节点表示结果,有向边上的数字表示因果关系的权重,节点的颜色由crfdl方法获取的学业表现对毕业去向选择的重要性分数编码,颜色越深,影响越大。通过观察因果网络中节点的颜色,用户可以了解哪些属性(即课程)对目标属性(即毕业去向)有重要的影响。通过观察因果网络中节点之间的关系,用户可以了解不同课程之间的影响以及这些影响是正向还是负向的。矩阵热图显示了学生课程成绩和毕业去向之间的斯皮尔曼相关系数分布,颜色的深浅表示相关程度;
115、(4)指定专业毕业生的毕业去向分布视图:该视图包括列表、饼图和折线图,允许用户分析本科生毕业去向的分布。列表展示了经过处理的数据集,包含11列,表示毕业年份、班级名称、学生id、性别、生源地、就业形式、单位名称、单位所在地、单位所属行业、单位类型和首次就业去向。每行代表一个学生,具有添加、删除、修改和过滤的功能。饼图显示了所选专业每个毕业去向的毕业生分布,以及一个折线图,表示不同毕业年份每个毕业去向的毕业生总数,每个毕业去向用不同颜色的线表示,当用户将鼠标悬停在折线图上并选择不同的年份时,饼图中的数据会相应更新;
116、与现有技术相比,本发明的有益效果是:
117、本发明提出了一种基于因果推断的本科生毕业去向预测与分析方法crfdl-mlp。首先基于本科生毕业去向和学业表现历史数据构建fdap数据集,通过yeo-johnson变换得到fdap特征集,以增强crfdl方法检测fdap数据集中因果关系的能力。然后基于随机森林特征选择算法和directlingam因果发现算法构建crfdl特征提取方法,以提高crfdl-mlp模型在高维、混合分布和非线性数据中计算因果关系的准确性。最后基于mlp构建本科生毕业去向预测模型。该模型在本科生毕业去向预测任务上达到了87%的准确率,优于四种传统的预测模型(朴素贝叶斯、逻辑回归、支持向量机和随机森林分类器)。与现有方法相比,本发明方法整合了因果推断和多层感知机神经网络,可以有效地处理fdap特征集中的高维混合型数据和复杂非线性关系,增强模型的可解释性,提高预测本科生毕业去向的准确度。
118、本发明设计并实现了一种基于本科生毕业去向预测模型的可视分析系统causalcareervis。该系统由四个主要视图组成:数据导入和过滤视图、当前在校学生毕业去向预测视图、学业表现与毕业去向之间的因果关系和相关关系视图(包括:学业表现的因果网络和课程与毕业去向之间的相关性子视图)以及指定专业毕业生的毕业去向分布视图(包括:毕业去向列表,从2016年到2022年的毕业去向分布子视图)。该系统能够准确预测本科生毕业去向,并且提供关于学业表现与本科生毕业去向之间因果关系和相关性的综合分析。causalcareervis可以帮助学生理解他们的学业表现如何影响他们的职业选择,并根据学生的当前学业表现预测其毕业去向,为学生和老师进行就业决策和学业表现分析提供个性化指导。
- 还没有人留言评论。精彩留言会获得点赞!