文本识别模型训练方法、文本识别方法及装置、设备与流程
本公开涉及机器视觉与自然语言处理,尤其涉及一种文本识别模型训练方法、文本识别方法及装置、设备。
背景技术:
1、在识别自然场景下图像中的文本信息过程中,通常使用计算机视觉模型识别图像中的文本。由于自然场景下图像中的文本存在被遮挡或文本模糊等情况,传统的计算机视觉模型无法准确的识别出被这遮挡或模糊的文本内容。因此,相关技术中通常引入语言模型,基于语言规则和语义内容对被遮挡或模糊的文本内容进行预测。
2、在实现本公开构思的过程中,发明人发现相关技术中至少存在如下问题:在引入语言模型后,往往采用预训练语言模型的方式使其获得语义纠错能力,降低了模型整体的训练效率。
技术实现思路
1、鉴于上述问题,本公开提供了文本识别模型训练方法、文本识别方法及装置、设备、介质和程序产品。
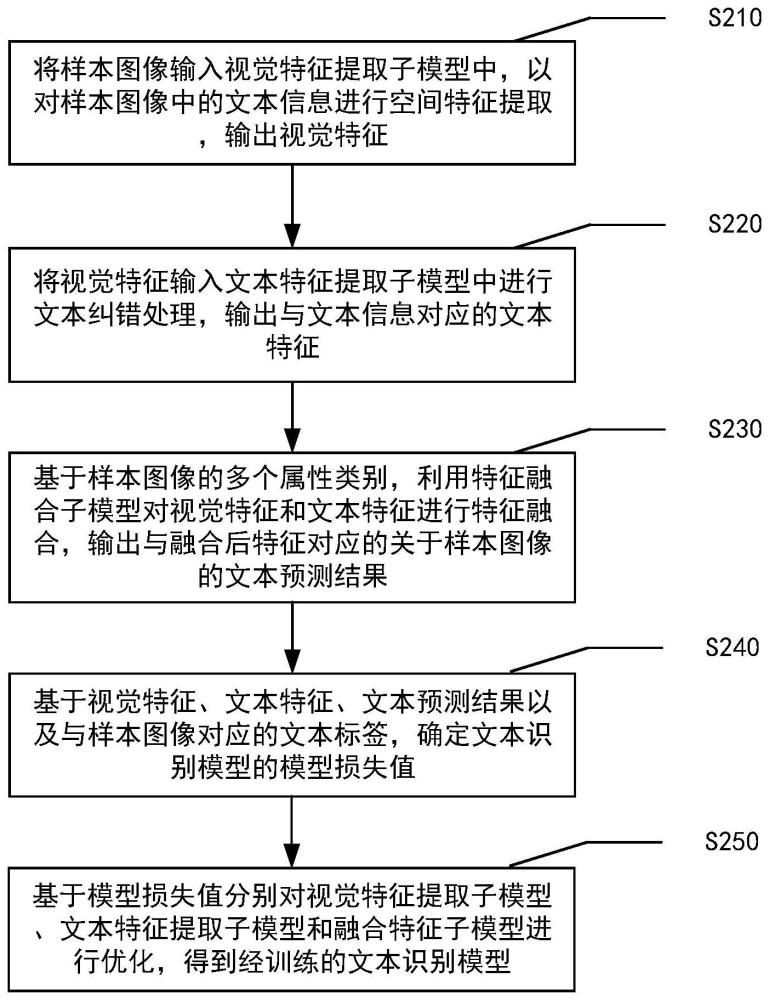
2、根据本公开的第一个方面,提供了一种文本识别模型训练方法,所述文本识别模型包括:视觉特征提取子模型、文本特征提取子模型和融合特征子模型,所述方法包括:
3、将样本图像输入所述视觉特征提取子模型中,以对所述样本图像中的文本信息进行空间特征提取,输出视觉特征;
4、将所述视觉特征输入所述文本特征提取子模型中进行文本纠错处理,输出与所述文本信息对应的文本特征;
5、基于所述样本图像的多个属性类别,利用所述特征融合子模型对所述视觉特征和所述文本特征进行特征融合,输出与融合后特征对应的关于所述样本图像的文本预测结果;
6、基于所述视觉特征、所述文本特征、所述文本预测结果以及与所述样本图像对应的文本标签,确定所述文本识别模型的模型损失值;
7、基于所述模型损失值分别对所述视觉特征提取子模型、所述文本特征提取子模型和所述融合特征子模型进行优化,得到经训练的文本识别模型。
8、根据本公开的实施例,所述基于所述样本图像的多个属性类别,利用所述特征融合子模型对所述视觉特征和所述文本特征进行特征融合,输出与融合后特征对应的关于所述样本图像的文本预测结果,包括:
9、基于所述样本图像的多个属性类别,利用所述特征融合子模型中的字符串拼接函数,对所述视觉特征和所述文本特征进行特征拼接,得到融合特征;
10、将所述融合特征依次输入所述特征融合子模型中的多个残差堆叠模块中,以对所述融合特征进行特征加强,输出加强特征;
11、基于所述特征融合子模型中的预设字符特征集,对所述加强特征中的多个字符分别进行置信度计算,以确定所述文本预测结果。
12、根据本公开的实施例,所述将所述融合特征依次输入所述特征融合子模型中的多个残差堆叠模块中,以对所述融合特征进行特征加强,输出加强特征,包括:
13、将所述融合特征输入第一残差堆叠模块的卷积层中对所述融合特征进行特征提取,输出提取特征,其中,所述第一残差堆叠模块为多个残差堆叠模块中的第一个残差堆叠模块;
14、基于残差连接的方式将所述融合特征和所述提取特征进行相加,得到拼接特征;
15、将所述拼接特征输入第一残差堆叠模块的特征加强网络中,输出中间特征;
16、根据所述多个残差堆叠模块之间的连接关系,将所述中间特征输入多个第二残差堆叠模块中依次进行特征加强,输出所述加强特征,其中,所述第二残差堆叠模块为所述多个残差堆叠模块除所述第一残差堆叠模块以外的残差堆叠模块。
17、根据本公开的实施例,所述将所述拼接特征输入第一残差堆叠模块的特征加强网络中,输出中间特征,包括:
18、基于所述拼接特征的特征信息,利用位置映射函数确定与所述拼接特征对应的位置编码矩阵;
19、利用字符串拼接函数对所述位置编码矩阵和所述拼接特征进行拼接,得到第一特征;
20、将所述第一特征输入所述特征加强网络中的自注意力机制层中,输出第二特征;
21、将所述第一特征和所述第二特征输入所述特征加强网络中的归一化层中进行归一化处理,输出所述中间特征。
22、根据本公开的实施例,在所述输出所述加强特征之前,还包括:
23、将进行特征加强后的中间特征输入所述特征融合子模型中的线性层中,对进行特征加强后的中间特征进行线性变换,得到所述加强特征。
24、根据本公开的实施例,所述基于所述视觉特征、所述文本特征、所述文本预测结果以及与所述样本图像对应的文本标签,确定所述文本识别模型的模型损失值,包括:
25、将所述视觉特征和与所述样本图像对应的文本标签输入视觉特征提取子模型的损失函数中,输出第一损失值;
26、将所述文本特征和所述文本标签输入文本特征提取子模型的损失函数中,输出第二损失值;
27、将所述文本预测结果和所述文本标签输入特征融合子模型的损失函数中,输出第三损失值;
28、将所述第一损失值、所述第二损失值以及所述第三损失值相加,得到所述模型损失值。
29、本公开的另一方面提供了一种文本识别方法,包括:
30、将目标图像输入至经上述任一项文本识别模型训练方法训练得到的视觉特征提取子模型中,以对目标图像中文本信息的空间特征进行提取,得到目标视觉特征;
31、将所述目标视觉特征输入至经上述任一项文本识别模型训练方法训练得到的文本特征子提取模型中进行文本纠错处理,输出目标文本特征;
32、基于所述目标图像的多个属性类别,利用经上述任一项文本识别模型训练方法训练得到的特征融合子模型,对所述目标视觉特征和所述目标文本特征进行特征融合,输出与融合后特征对应的关于所述目标图像的文本识别结果。
33、本公开的另一方面提供了一种文本识别模型训练装置,包括:
34、视觉提取模块,用于将样本图像输入所述视觉特征提取子模型中,以对所述样本图像中的文本信息进行空间特征提取,输出视觉特征;
35、文本提取模块,用于将所述视觉特征输入所述文本特征提取子模型中进行文本纠错处理,输出与所述文本信息对应的文本特征;
36、特征融合模块,用于基于所述样本图像的多个属性类别,利用所述特征融合子模型对所述视觉特征和所述文本特征进行特征融合,输出与融合后特征对应的关于所述样本图像的文本预测结果;
37、损失确定模块,用于基于所述视觉特征、所述文本特征、所述文本预测结果以及与所述样本图像对应的文本标签,确定所述文本识别模型的模型损失值;以及
38、模型训练模块,用于基于所述模型损失值分别对所述视觉特征提取子模型、所述文本特征提取子模型和所述融合特征子模型进行优化,得到经训练的文本识别模型。
39、本公开的另一方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得一个或多个处理器执行上述方法。
40、本公开的另一方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述方法。
41、本公开的另一方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述方法。
42、根据本公开提供的文本识别模型训练方法、文本识别方法及装置、设备、介质和程序产品,通过联合训练的方式,将样本图像输入到视觉特征子模型中,对样本图像中的文本信息进行提取,得到视觉特征,并将视觉特征作为文本图取子模型的输入,以此得到文本特征,使得文本识别模型可以学习到视觉特征与文本特征之间的对应关系,从而使文本特征可以更加准确的描述样本图像中文本的内容。通过特征融合子模型将文本特征和视觉特征进行特征融合,并基于融合特征进行预测,由于融合特征对视觉特征和文本特征中准确率较高的部分进行了特征加强,因此,基于融合特征得到的预测结果与文本标签计算文本识别模型的损失值,可以准确反应视觉特征与文本特征在模型中所占的比重,使得利用损失值对模型进行调参的精准度更高,从而提高了文本识别模型整体的性能,使得训练得到的文本识别模型在识别图像中的文本时更加精准。另外,将视觉特征提取子模型、文本特征提取子模型和融合特征子模型结合起来训练,不需要采用任何预训练的学习策略,各个子模型之间可以共享一部分参数一定程度上提高了文本识别模型的泛化能力和训练效率。
- 还没有人留言评论。精彩留言会获得点赞!