基于多任务算法的护学岗视觉监测系统
本发明涉及护学岗领域,尤其涉及基于多任务算法的护学岗视觉监测系统
背景技术:
1、传统的护学岗台需要花费交警、老师和家长的时间和精力,并且由于上下学的人流量较大可能无法同时顾及多处学生情况,因此传统的护学岗系统仍有不少地方需要改善和提高;近些年来,随着人工智能领域的不断发展,智能化设备或系统走进人们的日常生活中,护学岗需要车牌检测技术,面部是否有佩戴物检测技术以及姿态检测技术等检测技术,但是多任务算法的同时处理导致计算量大,检测速度慢;现有车牌检测技术由于车牌的拍摄角度会导致检测车牌的不准确,同时,姿态检测技术对特定姿态的检测检测并不是准确。
技术实现思路
1、发明目的:为了克服现有技术中存在的不足,本发明提供一种基于多任务算法的护学岗视觉监测系统,同时处理多个任务算法,监测学生上下学信息和保障学生上下学安全。
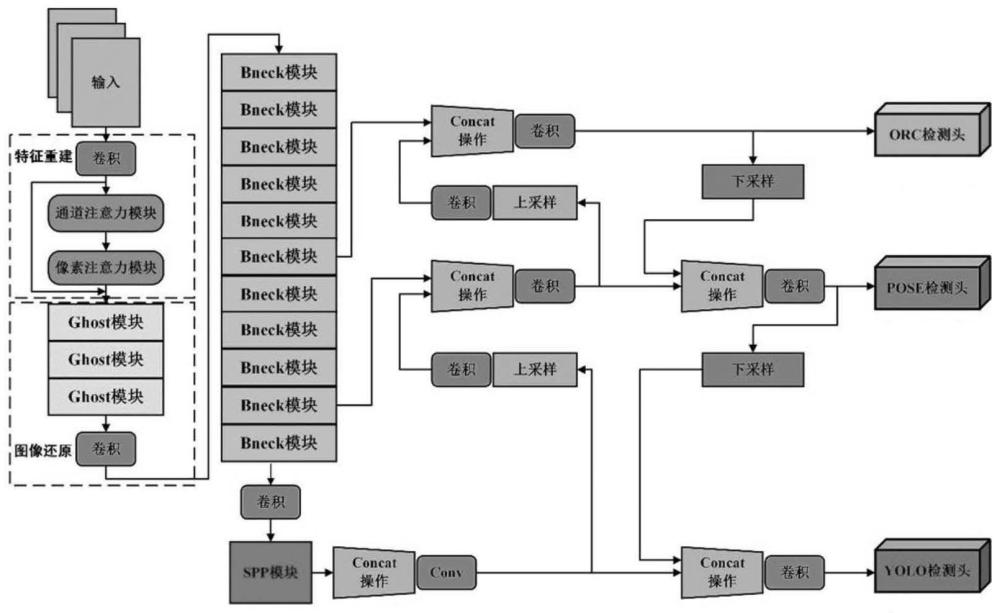
2、技术方案:为实现上述目的,本发明的基于多任务算法的护学岗视觉监测系统,包括护学岗亭;所述护学岗亭上设置有视觉传感器,且护学岗亭周边设定监测区域,所述视觉传感器采集监测区域内的图像,所述采集的图像传输至图像分析模块中分析,所述图像分析模块至少搭建车牌检测任务、姿态检测任务以及面部是否有佩戴物任务这三个任务的监测算法网络,所述车牌检测任务、姿态检测任务以及面部是否有佩戴物任务的监测算法均包括编码层和解码层,所述车牌检测任务、姿态检测任务以及面部是否有佩戴物任务的监测算法采用同一个编码层。
3、进一步的,所述编码层包括backbone模型和neck模型;所述backbone模型是用于特征提取,采用轻量级网络nr-mobilenetv3;所述neck模型由spp模块和fpn模块组成,所述neck模型融合nr-mobilenetv3提取的特征,将neck模型融合加工的特征作为解码层的输入;所述解码层包括ocr-head、pose-head和yolo-head;所述ocr-head处理车牌检测任务,pose-head处理姿态检测任务,yolo-head处理面部是否有佩戴物任务。
4、进一步的,所述网络nr-mobilenetv3是在网络mobilenetv3的基础上引入特征重建模型;所述特征重建特征模型包括特征提取模块和图像还原模块;所述特征提取模块将通过卷积提取图像的浅层特征输入通道注意力模块和像素注意力模块;所述通道注意力模块将权重转移到被雨水和雾气影响的特征信息,所述像素注意力模块对图像中的每一个像素点加权,采用残差结构,将浅层特征输入深层网络;得到去雨、去雾的推理公式:
5、x0=conv1(c)
6、x1=cab(x0)
7、x2=pab(x1)
8、其中c表示输入的被雨、雾影响的图片,x0表示卷积提取的浅层特征,x1表示通过通道注意力模块处理后输出的特征,x2表示通过像素注意力模块处理后输出的特征,cab表示通道注意力模块,pab表示像素注意力模块。
9、进一步的,所述图像还原模块将提取的深层特征映射到去雨、去雾图像中,所述图像还原模块由三个ghost模块和一个卷积组成;第一个ghost模块对提取的特征图做整合细化处理,第二个第三个ghost模块对特征图进行降维;图像还原模块输出与修复模块得到的特征图相融合后,输入最后的卷积层再输出;得图像还原模块推理公式:
10、
11、x4=conv2(x3)
12、其中x3通过ghost模块降维后的特征,x4是还原后的图像,x2表示通过像素注意力模块处理后输出的特征,表示特征组合,ghost表示采用ghost模型进行特征降维,conv2表示卷积操作,对图像进行还原。
13、进一步的,所述ocr-head处理车牌检测任务,将编码层提取的特征信息输入ocr网络,对输出的特征进行后处理操作,得到检测的每一个字符的类别信息和位置信息,将类别信息与预先设置好的字符进行对应能够得到每一个位置的字符信息,以及对于车牌字符依据位置信息进行排序操作,识别车牌;具体检测步骤如下:
14、step1:截取图像区域,通过数据分析获取图像角度;
15、step2:进行阈值处理,计算联通域;
16、step3:通过特征直方图进行特征筛选,将所联通域合成一个区域;
17、step4:通过合成的区域获取文字倾斜角度;
18、step5:基于文字倾斜角度进行仿射变化,将倾斜的图像转正。
19、进一步的,所述pose-head处理姿态检测任务,将编码层提取的特征信息输入openpose关节点定位网络得到人体骨架关节点信息;判断手部关键点与肩关节关键点的位置关系,得到手臂的姿态变化;设定手部21个关键点分别为hand0,hand1,...,hand20,肩关节关键点为sh0,推理公式如下:
20、f=s1×s2×s3×s4×s5×s6
21、其中f表示是否行礼的结果,其中s1,s2,s3,s4,s5分别代表拇指、食指、中指、无名指、小拇指是否完全的逻辑判断符,s6表示手部是否在肩部以上的逻辑判断符;
22、逻辑判断符的推理方法以s5为例,公式如下:
23、
24、
25、
26、其中λ表示角度阈值,s5表示小拇指是否完全的逻辑判断符,k1表示手部关键点17和手部关节点0连线的斜率,k2表示手部关键点20和手部关节点17连线的斜率,handi(x)表示关键点i横坐标,handi(y)表示关键点i的纵坐标。
27、进一步的,判断学生上下学是否摔倒的检测,基于人体骨架关节点数据以及三个条件的判断;三个条件均满足,则认为人员发生摔倒;
28、第一,左右髋关节关键点纵坐标减小速度大于预设临界速度阈值μ;
29、第二,左右髋关节关键点连线的斜率与水平线夹角小于预设的夹角阈值η;
30、第三,人体关键点外接矩形宽与高比值大于预设临界比值σ;
31、所述临界速度阈值μ、夹角阈值η和临界比值σ的设定基于行人摔倒后关节关键点的位置关系和关节关键点摔倒前后的变化差别。
32、进一步的,所述yolo-head处理面部是否有佩戴物任务,将编码层提取的特征信息输入原yolov8算法的头部网络解码,完成对面部是否有佩戴物任务的检测;调整置信度参数、长宽参数、坐标偏移量参数、以及类别参数生成最终的预测框;设定编码层输出的特征图左上坐标为(rx,ry),特征图中生成的先验框的宽和高分别为hw和hh;生成预测框的具体方法如下:
33、step1:根据先验框和特征图左上坐标为(rx,ry)获取预测框的中心横坐标,推理公式如下:
34、
35、其中kx表示预测框中心横坐标,tx表示预测横坐标的偏移值,rx表示特征图左上横坐标;
36、step2:根据先验框和特征图左上坐标为(rx,ry)获取预测框的中心纵坐标,推理公式如下:
37、
38、其中ky表示预测框中心纵坐标,ty表示预测纵坐标的偏移值,ry表示特征图左上纵坐标;
39、step3:根据预测框的中心坐标及先验框的宽和高分别为hw和hh计算预测框的宽和高,推理公式如下:
40、
41、
42、其中kw表示预测框宽度,tw表示宽度维度的尺度缩放,hw表示先验框映射到特征图中的宽;ky表示预测框高度,th表示高度维度的尺度缩放,hh表示先验框映射到特征图中的高;
43、step4:根据预测框的中心坐标、宽和高确定最终的预测框,完成对待检测目标的框选。
44、有益效果:本发明的基于多任务算法的护学岗视觉监测系统,将减少交警、老师和家长时间精力的投入,可以及时管理和监测学生的各个方面的状况;提出了高效的多任务监测算法,同时处理车牌检测任务、姿态检测任务以及面部是否有佩戴物任务,多个任务共享同一个编码层,能够减少计算量,提升检测速度;提出的ocr-head车牌检测算法,通过对ocr算法加入仿射变化矫正,有效的提高检测正确率;提出对人体关键点检测的算法,有效判断了学生的打闹、行礼和摔倒行为,通过人体动作用于更多的人机交互情景中;提出面部是否有佩戴物检测的算法,能够满足应用时检测的正确率,以及检测的实时性。
- 还没有人留言评论。精彩留言会获得点赞!