一种基于人工智能大数据模型的工业园区危险废物处理方法与流程
本发明涉及危险废物处理,特别涉及一种基于人工智能大数据模型的工业园区危险废物处理方法。
背景技术:
1、危险废物是指列入国家危险废物名录的具有危险特性的废物,包括医疗废物、医药废物、废药物药品、农药废物等等,所有危险废物都需要经过严格的处理方式。
2、根据《中华人民共和国固体废物污染环境防治法》、《重庆市环境保护条件》、《危险废物收集、贮存、运输技术规范》、《危险废物转移联单管理办法》、《危险废物经营许可证管理办法》等法律法规,需要对危险废物从生产、存储、运输、处理的全流程进行规范化管理,同时还需要对危险废物进行全流程监测,防止因管理不到位造成不可估量的损失,乃至造成人员伤亡。
3、目前的管理流程较为完善,大多通过各种自动化监测及自动化统计手段,实现危险废物全流程跟踪,但其不足在于:1、全流程中不乏人员参与,有失误的可能性,例如误封装、延期运输、存储泄漏、厂家生产异常等情况,以目前的监管手段无法有效识别,有较大的风险;2、危险废物的各类较多,每家工厂都有各自独立的监管软硬件,对于大型工业园区无法对园区内所有工厂实行有效的监管。
技术实现思路
1、本发明公开了一种基于人工智能大数据模型的工业园区危险废物处理方法,它以工业园区作为主体,针对工业园区内不同厂家,可独立完成危险废物的全方位监管,显著提高了危险废物的处理安全性。
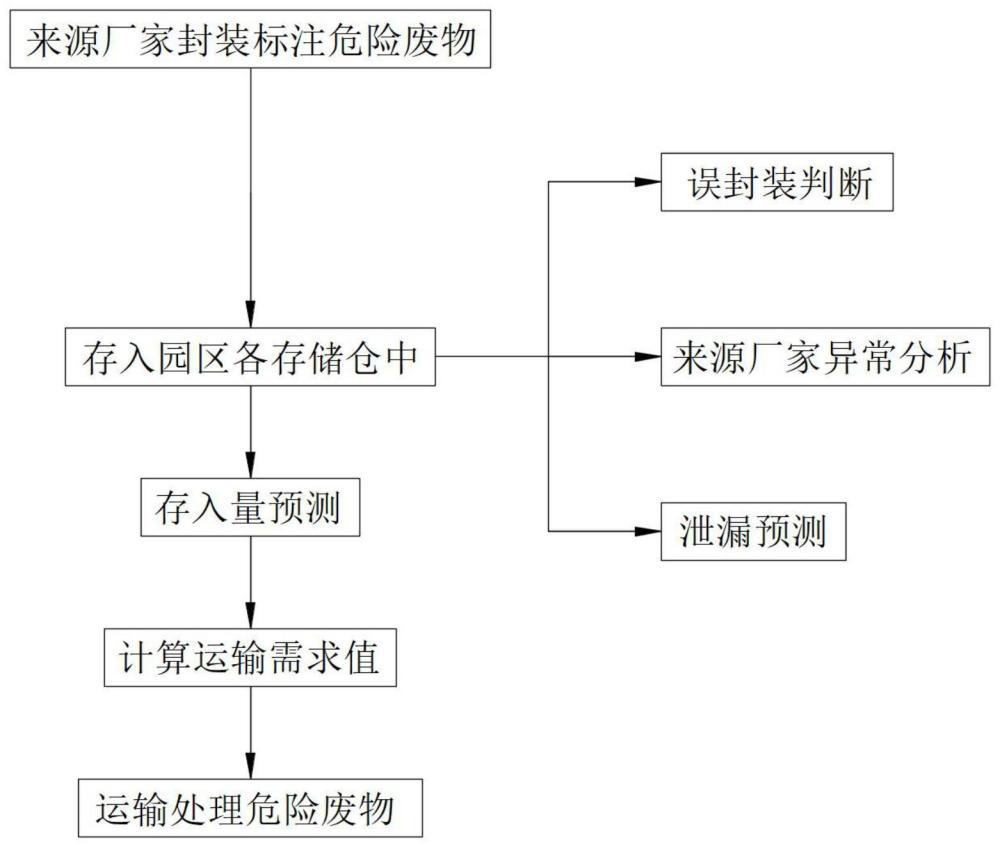
2、它通过这样的技术方案实现的,所述工业园区内建造有若干用于存储不同类别危险废物的存储仓,危险废物的处理方法如下:
3、针对封装后的危险废物,标注危险废物的种类、封装日期、来源厂家、重量和体积信息;
4、将标注后的危险废物存储在对应各类的存储仓中;
5、规化运输,将各存储仓中的危险废物运送至对应处置地;
6、在危险废物入存储仓时,通过异常分析模型判断来源厂家的生产情况;
7、在危险废物入存储仓时,判断是否存在误封装;
8、在存储仓中,设置有用于不同危险废物泄漏检测的对应传感器,传感器采集到的数据通过泄漏预测模型判断存储仓内是否发生了泄漏;
9、通过存入量预测模型预测每个存储仓未来的存入量,计算每个存储仓的运输需求值,安排运输车辆依据运输需求值从高至低依次运输不同存储仓内的危险废物。
10、该实施例的优点在于,以工业园区的管理方为操作主体,针对不同的存储仓分别建立各自的监测模型,无论工业园区内有多少危险废物生产厂家,均可实现全流程管理和风险监控;针对人工可能犯错的危险废物的存储流程,可通过异常分析模型判断来源厂家的生产情况,以及判断是否可能出现了误封装;在存储时,还可以判断存储仓是否发生泄漏,显著降低了事故风险;针对危险废物运输流程,综合了危险废物以及存储仓的各种特性,实时指导运输优先级,在节约运输成本的基础上进一步降低了事故风险。
11、可选地,所述危险废物包括以下任意一项及以上:
12、药品制造废物、农药制造废物、木材防腐剂制造废物、精炼石油废物、燃气生产废物和基础化学原料制造废物。
13、进一步地,通过异常分析模型判断来源厂家的生产情况,具体方法如下:
14、根据存入存储仓的危险废物的来源厂家,选取对应厂家的异常分析模型;
15、调取异常分析日当日,该对应厂家在各类危险废物存储仓分别存入的危险废物种类和每类对应重量;
16、将各种危险废物种类和每类对应重量输入异常分析模型;
17、异常分析模型输出异常分析日当日,该厂家生产是否存在异常。
18、进一步地,所述异常分析模型为随机森林模型,其构建方法如下:
19、对于总训练集t,t中共有n个样本,每次有放回地随机选择n个样本,每个样本中均包括相同随机特征,随机特征个数k小于总特征数d,由此n个样本构建每棵决策树的树训练样本;
20、当每个树训练样本有m个属性时,在决策树的每个节点需要分裂时,随机从m个属性中选取出m个属性,满足条件m<<m,从这m个属性中采用信息增益g(d,a)=h(d)-h(d|a)为根据,选取1个属于作为该节点的分裂属性;
21、直到每棵决策树不再分裂为止;
22、综合每棵决策树的投票结果,最终投票结果最多的类别即随机森林模型最终输出;
23、随机森林模型构建过程中,总训练集t为厂家历史存储每种危险废物的重量以及人为标注的生产是否存在异常;n个样本为历史n日中厂家每日分别存储每种危险废物的重量,随机特征k为每种危险废物的重量;
24、因此,每棵决策树的树训练样本为在总训练集t中随机可放回地获取n次历史单日数据,每次获取的历史单日数据均包括随机且相同的危险废物各类及重量。
25、该实施例的优点在于,针对园区内每家厂家均单独定制一个异常分析模型,可从危险废物的出货量检测厂家的生产情况是否异常,进一步提高园区主管方对园区的掌控力;随机森林算法作为异常分类算法能融合大数据特征,具有准确极高、不容易过拟合、抗噪声能力强,可处理高维度数据等优势,针对各家厂家情况不同的特殊情况,随机森林算法是最优选择。
26、进一步地,在危险废物入存储仓时,判断是否存在误封装,具体方法如下:
27、读取封装危险废物标注的种类信息,若标注各类信息与存储仓存储种类信息不同,则判断为误封装或误存储;
28、读取封装危险废物标注的标注重量和标注体积信息,根据标注重量和标体积计算理论密度;
29、实测封装危险废物的实际重量,根据实际重量和标注体积计算参考密度;
30、将标注重量与实际重量的差值、标注体积、以及理论密度与参考密度的差值,作为输入,通过决策树输出是否存在误封装。
31、进一步地,所述决策树构建方法如下:
32、获取若干组历史数据,历史数据包括历史标注重量与实际重量的差值、历史标注体积、以及历史理论密度与参考密度的差值,为每组历史数据标注是否存在误封装;
33、计算根节点的信息熵,h(d)=-∑p(i).log2p(i),式中p(i)为误封装或非误封装的概率;
34、分别计算各属性的信息增益,g(d,a)=h(d)-h(d|a);
35、选取信息增益最大的属性作为划分属性;
36、重复计算信息增益以及选取信息增益最大属性,直到决策树无法再分裂。
37、该实施例的优点在于,虽然危险废物的各类相同,但其密度可能随工艺、原材料等的变化发生相应的变化,因此相较于易想到的阈值判断,采用决策树算法可显著提高误封装判断的正确率,且决策树算法相对简单,可节省算力。
38、进一步地,通过泄漏预测模型判断存储仓内是否发生了泄漏,具体方法如下:
39、针对不同的存储仓以及危险废物种类,设置一种或多种可能泄漏气体对应的气体传感器;
40、以存储仓中分别存入不同重量的对应危险废物,关闭存储仓门,经过预设时间后通过气体传感器获取关闭仓门期间泄漏气体的增长量;
41、对不同重量,以及不同重量对应的泄漏气体增长量构建训练数据;
42、以训练数据训练神经网络模型;
43、每次关闭存储仓之前,获取存储仓内危险废物的实际重量,排空存储仓内的泄漏气体,经预设时间后,将气体传感器获取的泄漏气体增长量以及危险废物实际重量输入神经网络模型中,输出存储仓内是否发生了泄漏的判断。
44、该实施例的优点在于,泄漏预测模型针对相同的封仓时间,在封仓之前尽量排出泄漏气体,可显著提高预测的准确率。
45、进一步地,通过存入量预测模型预测每个存储仓未来的存入量,具体方法如下:
46、获取每个存储仓历史存入数据,以历史存入数据作为训练数据;
47、以训练数据训练神经网络模型;
48、以神经网络模型预测每个存储仓未来的存入量。
49、进一步地,所述神经网络模型的训练方法如下:
50、初始化输入层、隐藏层和输出层;
51、初始化输入层、隐藏层和输出层的神经元权值以及偏置值;
52、定义学习率、训练周期数、测试周期数;
53、设置激活函数为sigmoid函数,损失函数为mse均方差函数;
54、通过正向传播计算当前损失;
55、通过反向传播计算更新权值;
56、直到神经网络模型收敛,或达到训练次数。
57、进一步地,每个存储仓的运输需求值,计算公式如下:
58、
59、式中,dvi为第i个存储仓的运输需求值,ωi为第i个存储仓所存危险废物的危险权重,rdi为第i个存储仓当前所余空间结合未来存入量预计还能存入的天数,tdi为假设第i个存储仓当前为空时结合未来存入量预计还能存入的天数,thi为预设第i个存储仓不运输的最大上限天数,dnci为第i个存储仓距离上一次运输的实际天数。
60、该实施例的优点在于,过多的运输车辆可能导致运输不饱和,浪费运输成本,过少的运输车辆会延长危险废物的运输时间,增加处理风险;该实施例考虑了危险废物的危险程度、存储仓的容量以及运输的频次,当长时间无车辆运输时,分母趋近于零,运输需求值趋近于正无穷;存储仓为空时未来预测的存入量不变,存储仓能存入的总天数不变,当还能存储的天数越大,分子越小,危险废物的运输需求值越低。
- 还没有人留言评论。精彩留言会获得点赞!