基于深度可分离卷积与并行网络架构的X光重建CT方法与流程
本发明属于生物医学图像处理领域,具体涉及一种基于深度可分离卷积与并行网络架构的x光重建ct方法。
背景技术:
1、计算机断层扫描(computed tomography ct)可以提供患者器官的三维视图,依靠术前x线片和ct等影像学资料进行诊断和术前规划是必不可少,这便于疾病诊断。研究表明,做一次x光,人体会接受大约0.02毫西弗(msv)的辐射量,做一次常规剂量的ct,人体会接受大约4~7毫西弗(msv)的辐射量,而做一次低剂量的ct,人体会接受低于2毫西弗(msv)的辐射量。因此,做x光人体接受的辐射量会远远少于做ct人体接受的辐射量。但是,x光因为维度的限制,不可避免的会出现人体器官在影像上相互重叠的现象,而ct的出现,将x光的二维空间扩展到三维空间,信息从二维扩展到三维,完美的解决了器官重叠带来的信息重叠造成的影响。因此,尝试从二维的x光影像重建到三维的ct影像是非常有医学意义和现实意义的。
2、目前,三维重建方法主要分为:1.在深度学习进入三维重建处理领域前的人们利用数字图像处理、拓扑学、统计学、数学等方面来进行重建的传统方法。2.近几年随着算力的增加以及深度学习的井喷式发展,基于深度学习的方法对于三维重建领域越来越占有不可取代的地位。
3、1、如li b, kałużny j, klein j在acm transactions on graphics (tog)上发表的 learning to reconstruct botanical trees from single images[j],tan p,zeng g, wang j在acm siggraph 2007 papers发表的 image-based tree modeling[m],其公开了基于单幅/多幅图像的三维重建方法。这种方法是很常见的一种三维重建的方法,它通过一张或者若干张图像,实现对二维图像的三维重建。具体是:首先,在图像中选取一个点作为种子结点,再以种子结点为中心360度向外辐射,若辐射出的线段与图像部分重叠,则选取该线段作为骨架,并以重叠部分作为新的种子结点,继续向外辐射。所得的结果即为物体骨架,再通过管道重建物体。这个方法的优点是方便快捷,在很短时间内就能重建出物体;缺点是不能重建复杂物体,只能对花草树木等形状规则的物体做重建,同时,重建出物体的相似性不高,也忽视了很多图像细节。
4、2、如livny y, yan f, olson m, 发表在acm siggraph asia 2010 papers 上的automatic reconstruction of tree skeletal structures from point clouds[m],具体公开了基于点云的三维重建方法。这是三维重建方法中很重要的一部分。首先,它将三维物体转化成点云数据,再通过剪枝方法剪去噪声数据,最后将管道作为骨架重建三维物体。它的优点是适合对规则物体做三维重建,比如说树木,文物等;缺点是不能对人体器官等不规则物体做重建。
5、传统的重建方法有着简单,方便的优点,但重建的精度差强人意,常常用于一些简单物体的重建,比如说:文物重建、树木重建等等。而现今,随着深度学习的发展,传统的方法已经逐渐被淘汰。深度学习方法完全区别于传统方法,它基于算力的支持,对大量带有标签的数据集进行训练,让机器自主学习到图像的内在规律及特征。深度学习方法在重建过程中能够处理、学习到大量的数据特征,从而可以提升重建的精度和可靠性。在计算机三维重建领域,基于深度学习的三维重建已经发展成为一种重要的研究方向,广泛应用于医学图像的重建,包含以下两类主流方法:
6、一、基于卷积神经网络(cnn)的三维重建方法。l shen, w zhao, l xing等人发表在2019年的nature biomedical engineering上的patient-specific reconstruction ofvolumetric computed tomography images from a single projection view via deeplearning[j].通过基本的二维卷积操作提取肺部x光影像的特征,在2维到3三维的转化部分使用了reshape操作将一维特征变成三维特征,后面通过三维反卷积操作不断上采样,生成我们的肺部ct影像,同时,文章的损失函数仅使用l1损失或者mse损失。henzler p,rasche v, ropinski t等人发表在2018期computer graphics forum上的single‐imagetomography: 3d volumes from 2d cranial x‐rays[c],通过使用resnet网络架构作为网络的encoder提取头骨影像的影像特征,同时在encoder部分和decoder部分使用跳跃连接,在decoder部分借鉴çiçek ö提供的三维卷积操作,生成三维动物头骨。
7、二、基于生成对抗网络(gan)的三维重建方法。最经典的gan网络生成三维结构,是ying x, guo h, ma k等人在2019年的proceedings of the ieee/cvf conference oncomputer vision and pattern recognition上发表的x2ct-gan: reconstructing ctfrom biplanar x-rays with generative adversarial networks[c],提出的x2ct-gan网络生成肺部ct影像,它包含3d生成器、3d判别器。3d生成器中将互相垂直的x光影像作为输入,将二维特征转化为三维特征。3d判别器中,使用了phillip的3dpatchdiscriminator处理三维特征实现ct的重建。
8、而对于x光重建ct,中国专利cn115719391a公开了一种利用双平面x光照片重建ct图片的方法,主要利用trct-gan网络对双平面x射线重建ct。主要包括以下步骤:
9、步骤一、数据集处理,获1018张ct图片,利用数字重建放射影像技术分别合成1018张正面x光图片和1018张侧面x光图片,并点其中的916组双平面x图片和对应的ct图片作为训练集,剩余的作为测试集;
10、步骤二、网络模型建立,基于包含3d生成器和3d鉴别器的x2ct-gan,在3d生成器的编码器和解码器中加入动态注意力模块和transformer网络,使用patchgan作为3d鉴别器网络;
11、步骤三、损失函数的优化,基于包含对抗损失函数和重建损失函数的x2ct-gan网络框架,在trct-gan网络模型中的投影损失函数中加入感知损失函数进行优化,获得最终的trct-gan网络模型;
12、步骤四、模型的训练,利用训练集和测试集对trct-gan网络模型进行训练和测试,获得训练后的trct-gan网络模型步骤五、ct图片的重建,将患者的正面x光图片和对应的侧面x光图片作为trct-gan网络模型的输入,由trct-gan网终输出获得重建的ct图片。
13、其虽然加入了动态注意力模块和transformer网络以提升模型的性能,但是忽略了网络参数量的增加。深度学习模型的参数量随着网络深度的增加而不断膨胀,这不仅增加了模型的复杂性,也使得训练过程对显存需求巨大,从而提高了训练的门槛。这是因为在深度学习中,模型的深度与参数数量呈正相关关系,而网络层数的增加会导致参数的指数级增长。这对计算资源提出了更高的要求,尤其是显存需求庞大,这使得在训练深度学习模型时,需要强大的硬件支持。高显存占用不仅使得昂贵的显卡成为必备,同时也使得训练环境的搭建更为困难。因此,模型的规模成为训练成功的一个关键因素,尤其对于小型团队或资源受限的研究者而言,这种情况可能形成明显的训练门槛,制约了深度学习技术的广泛应用。
技术实现思路
1、针对现有技术存在的不足,本发明的目的在于提供一种基于深度可分离卷积与并行网络架构的x光重建ct方法。
2、为实现上述目的,本发明提供了如下技术方案:
3、一种基于深度可分离卷积与并行网络架构的x光重建ct方法,其包括以下步骤:
4、步骤一、x光数据和ct数据预处理,x光数据包括正面x光图片及对应位置的侧面x光图片,并构建数据集,并将其按照设定比例分成训练集及测试集;
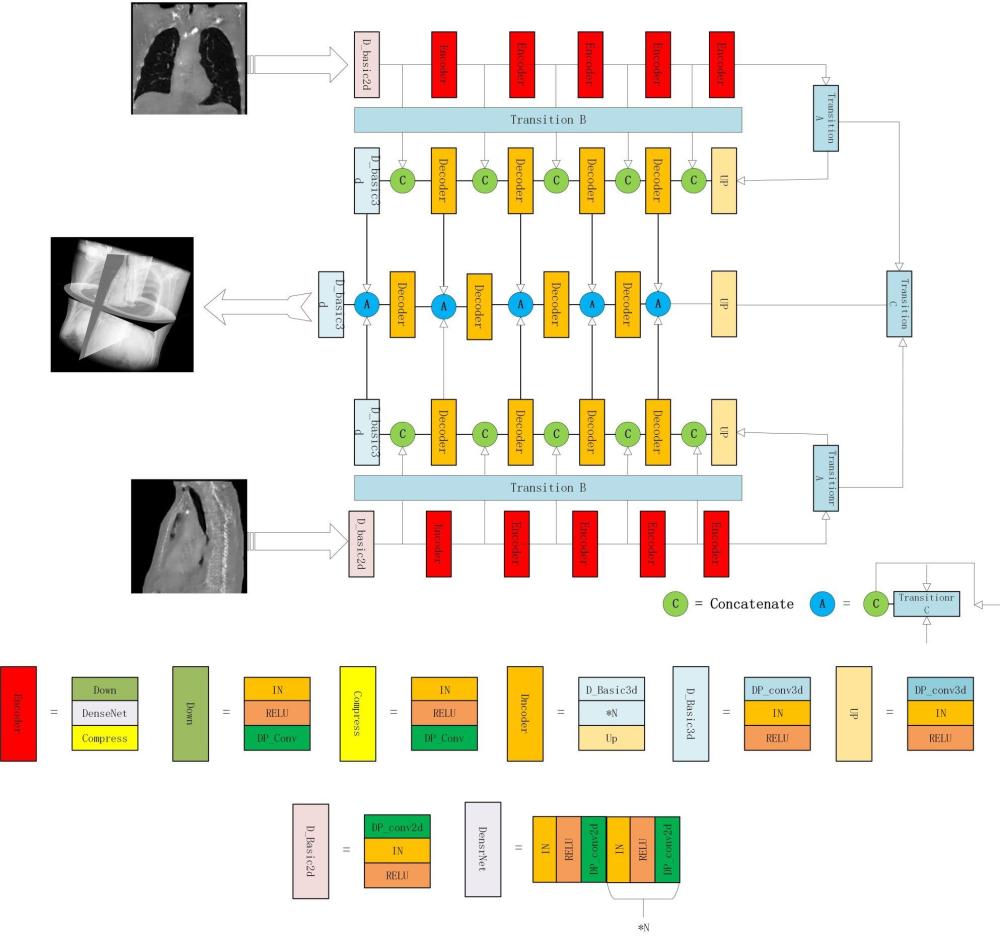
5、步骤二、构建gan模型,所述gan模型基于包含generator生成器和discriminator判别器的网络架构,所述generator生成器设有两路并行的分别获取x光数据的正面x光图片及对应位置的侧面x光图片的encoder-transition-decoder网络,并利用featurefusion模块将两个并行的encoder-transition-decoder网络的双平面信息进行融合重建三维ct图像,每一个encoder-transition-decoder网络引入通过深度可分离卷积抽取二维特征的encoder部分及transition部分以及将二维特征转化成三维特征的decoder部分,所述discriminator判别器通过引入深度可分离卷积提取生成三维向量以计算对抗损失,
6、所述transition部分包含:
7、transition-a模块,连接encoder部分和decoder部分,用于将2d特征转化成3d特征;
8、transition-b模块,用于encoder网络的跳跃连接,将encoder部分的特征转化为decoder部分的输入;
9、transition-c模块,用于将并行的encoder-transition-decoder网络做特征融合;
10、步骤三、损失函数的优化,采用包含最小二乘生成对抗网络函数llsgan及投影损失函数lpl对步骤二中建立的gan模型进行优化;
11、步骤四、训练gan模型,利用训练集和测试集对gan模型进行训练和测试,获得训练后的gan模型;
12、步骤五、将患者的正面x光图片和对应的侧面x光图片作为训练后的gan模型的输入,由训练后的gan模型输出重建后的三维ct图像。
13、在gan模型的损失函数中加入融合损失函数lfl及向量损失函数ltl,并结合最小二乘生成对抗网络函数llsgan及投影损失函数lpl,获得总损失函数:
14、
15、,
16、表示差异损失项的重要性,并利用总损失函数对gan模型进行优化,d*是判别总的损失,d代表判别器,g*是生成总损失,g代表生成器。
17、步骤一中,对获取的x光数据进行分辨率及尺寸统一,对获取的ct数据进行分辨率统一。
18、encoder模块由密集连接编码器组成,采用5层densenet网络作为encoder网络的主干,且5层densenet网络分别包含6,12,24,16,6层卷积层,每一个卷积层包括in层-relu层-conv层和in层-relu层-逐通道卷积层-逐点卷积层,并用深度可分离卷积替代encoder网络的传统卷积,每一个encoder。
19、transition-a模块将二维特征经过fc层—dropout层—relu层,将处理后得到的向量经过view操作生成三维向量;
20、transition-b模块将二维特征经过conv2d层—in层—relu层,再经过expend操作,将二维向量扩展成三维特征;生成的三维特征经过逐通道卷积层—逐点卷积层—in层—relu层,得到decoder模块的输入。
21、每个decoder模块都包含2层三维卷积层,1层三维卷积层包括逐通道卷积层-逐点卷积层-in层-relu层,并用深度可分离卷积替代传统卷积。
22、每一个decoder模块最后均设有上采样模块,所述上采样模块包含逐通道卷积层-逐点卷积层-in层-relu层。
23、所述encoder网络通过跳跃连接的方式将逐层提取的特征传给decoder网络,且通过concatenate操作将从encoder传递过来的特征和正常传递的特征做拼接,并在完成拼接后继续往下传递。
24、三维特征向量先经过一个block1,一个block1包括逐通道卷积层-逐点卷积层-leakyrelu层;再经过三个block2,一个block2包括逐通道卷积层-逐点卷积层-in层-leakyrelu层;最后经过block3,一个block3包括逐通道卷积层-逐点卷积层。
25、构建好gan网络后,选取adam优化器进行训练,学习率为2*10-4,在训练50轮后使用线性衰减将学习率逐渐减低到0,动量参数β1=0.5,β2=0.99,共训练100轮,使用融合损失函数lfl、向量损失函数ltl、最小二乘生成对抗网络函数llsgan及投影损失函数lpl作为生成的约束。
26、本发明的有益效果:本技术提出的gan模型,每一次的encoder操作后都有相应的decoder来还原。它的优势是能够多层次、全方面获取图像的特征,挖掘图像背后隐藏的信息,可以更多提取图像特征,采取深度可分离卷积可以显著减少模型的参数量,减低模型的训练门槛,减低模型的参数并提升网络的性能,达到更优越的x光重建ct的效果。
- 还没有人留言评论。精彩留言会获得点赞!