一种基于TD误差优先采样和Adam自适应学习率的SA-TD3算法
本发明涉及强化学习领域,具体涉及一种基于td误差采样和自适应学习率的sa-td3深度强化学习控制算法。
背景技术:
1、深度强化学习(deep reinforcement learning,drl)起源于deepmind团队在《nature》杂志中将深度神经网络和q-learning算法相结合,构建神经网络逼近状态-动作值函数,引入经验回放机制,提出了深度q网络算法(deep q-network,dqn)。dqn在atari游戏中以游戏画面的像素为输入,实现了超越人类玩家的水平,展示了深度强化学习的强大自主学习能力。silver等提出了确定性策略梯度算法(deterministic policy gradient,dpg),lillicrap等将dqn思想与actor-critic(演员-评论家)框架结合起来,在dpg的基础上提出了深度确定性策略梯度算法(deep deterministic policy gradient,ddpg),该算法能够更好的解决连续动作空间上的强化学习问题。scott等人提出的双延迟深度确定性策略梯度算法(twin delay deep deterministic policy gradient,td3)在ddpg算法的基础上采用双q网络,选取其中较小的值来平衡价值,并延迟更新策略网络,以减少更新错误,同时为目标动作增加噪声,用作算法的正则化器。
2、然而,td3算法面临着收敛速度较慢和训练稳定性不佳等问题,经验池所有样本都以等概率随机采样,忽略不同样本具有不同重要性的信息,造成训练速度慢、训练过程不稳定的缺点以及参数更新时梯度下降法在迭代求最优解的过程中,在极值点附近算法的收敛速度极大地减缓,导致最终的参数优化变慢等问题,因此,采取较好的采样方法和参数更新方法极为重要。
技术实现思路
1、本发明的目的在于针对现有技术中的上述问题,提出一种基于td误差优先采样和adam自适应学习率调整的sa-td3方法,通过优先采样提高经验数据样本质量,通过自适应学习率的调整得到合适的学习率,以此提高td3算法的收敛速度及稳定性。
2、本方法包括以下步骤:
3、s1、设计td3算法的网络训练模型,使用原始td3算法和ddpg算法训练三个经典的连续控制任务,观察其奖励值随着训练回合增加的情况;
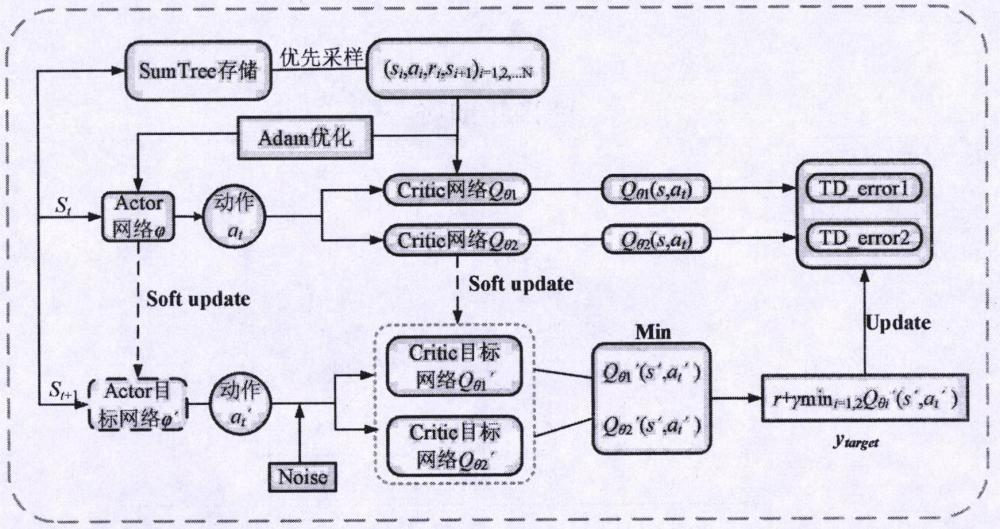
4、s2、根据步骤s1搭建的td3算法网络训练模型,设计基于td误差的优先采样模块,进行模型训练;
5、s3、在td3算法的网络模型上设计基于adam优化算法的自适应学习率调整模块,不断迭代寻优,得到待优化目标超参数的优质解;
6、s4、使用改进后的算法对openai gym中的控制任务进行训练记录训练回合数及每回合获得的奖励值,作为算法改进效果的指标;
7、进一步的技术方案包括:
8、步骤s2的具体过程为:
9、s21、将样本优先级pi和样本数据(s,a,r,s′)使用二叉树结构的存储单元进行存储,如图1所示,在抽样时根据优先级的大小进行抽取。优先级取决于时序差分(temporal-difference learning,td)误差的大小,td误差的值越大说明样本被学习的重要性越高,相应的优先级也越高。这样会使有用的经验数据被采样的概率变高,从而加快收敛速度并提高数据利用率;
10、s22、为保证采样是按优先级进行,并且样本的优先级被抽样的概率是单调的,同时保证即使对于最低优先级的转移也是非零概率的。定义采样转移的概率为:
11、
12、式中pi表示样本i的优先级,α为常数决定了优先级对每个元组采样概率的影响程度,当α=0时,优先级不发挥任何作用,经验池采样变成均匀采样,α越大其优先级发挥的作用越大;k是采样的批量数。
13、s23、根据目标q值与当前q值的差值计算δ,根据δ的值决定优先采样的优先级。
14、pi=|δ(i)|+ε
15、
16、式中ytarget为目标q值,qθi(s,a)为计算得出的当前q值;i表示数据的序号,ε是个很小的数,防止抽样概率接近零,用于保证所有的样本都以非零的概率被抽到。
17、s24、使用优先采样会带来偏差,使系统不稳定,导致神经网络的训练过程出现无法收敛的状况。为了解决这一问题,设置样本重要性权重来纠正偏差:
18、
19、式中,wi表示权重系数,n代表经验池大小,β表示非均匀概率补偿系数,当β=1时就完全补偿了pi。优先采样增加了网络向有较大学习价值的样本进行学习的概率,也保证了每个经验数据被选到的概率是不同的,提升训练速度,使网络更快收敛。
20、步骤s3的具体过程为:
21、s31、本文在使用adam优化算法更新参数时给学习率添加一个修正因子,以下降趋势的幂指数学习率为基础,利用上一阶段的梯度值对其进行调节,达到自适应调节的要求,进而加快算法的收敛速度和提高算法的稳定性。
22、幂指数学习率为:
23、η=η0m-k
24、式中:η0表示初始学习率,本文取η0=0.1;m表示迭代中间量,由迭代次数和最大迭代次数确定;
25、s32、计算超参数k,其计算公式为:
26、
27、式中:λi表示第i次迭代过程中的步长变化率;q为固定常数,一般取值为0.75。
28、s33、结合梯度更新变化公式,在第t次迭代学习率的更新过程如式所示。
29、
30、
31、
32、式中,r为最大迭代次数;lt为第t次迭代的梯度值lt和t-1次迭代的梯度值lt-1的平方和;α为adam算法的衰减因子,默认取值0.999;k为常数项,取值为1。
33、s34、将自适应学习率代入adam优化算法中,adam优化器的基本算法可以描述如下。
34、设目标函数为ft(θ),使用随机性描述小批量样本函数噪声来减小该函数的期望大小,计算参数为θ的目标函数梯度:
35、
36、s35、计算一阶矩估计ot和二阶矩估计et的公式如下:
37、ot=β1·ot-1+(1-β1)·gt
38、
39、式中,参数β1,β2是一阶矩估计和二阶矩估计的指数衰减率。在迭代初期,衰减率很小的情况下,矩估计值容易偏向0,会产生偏差。
40、s36、为了消除初始化偏差,需要对ot和et的偏差进行修正,修正后的一阶矩估计和二阶矩估计如下所示:
41、
42、
43、为信噪比(signal noise ratio,snr),表示系统中信号与噪声的比值,当snr取较小的值,δt趋向于无穷小时,目标函数将收敛到极值。
44、s37、令二阶矩估计et的初始值为0,则et在第t个迭代周期更新方法如式所示:
45、
46、s38、每迭代一个周期,都要更新参数θ,其更新表达式为:
47、
48、式中,ε=10-8表示一个常数参量。通过参数更新迭代,使目标函数向最优解方向收敛。
49、本方法的优点在于:(1)采用基于td误差的优先采样,因为以往td3算法在经验回放池中随机抽取一批数据作为训练数据。该方法有利于打破样本之间的关联性,但是,使用随机抽样抽取的样本数据质量参差不齐,可能会出现大量无用样本的情况,影响训练,学习效率不高,因此,采用基于td误差的优先采样,优先采样增加了网络向有较大学习价值的样本进行学习的概率,也保证了每个经验数据被选到的概率是不同的,提升了训练速度,使网络更快收敛。(2)选择使用adam优化算法更新参数,以往的梯度下降算法由于其本身的局限性,在梯度迭代求最优解的过程中,极值点附近其收敛速度会极大地减缓,导致参数优化过程变慢,而本文选取adam优化算法并为学习率添加修正因子,可以很好的提高算法收敛速度及稳定新。本方法具有良好的实用性及实时性。
- 还没有人留言评论。精彩留言会获得点赞!