一种基于大模型的本地知识库智能问答方法、系统、设备及可读存储介质与流程
本发明涉及一种基于大模型的本地知识库智能问答方法、系统、设备及可读存储介质,属于人工智能领域。
背景技术:
1、随着互联网和人工智能技术的快速发展,智能问答系统越来越广泛地应用于客户服务、在线咨询等场景,为了提供更好的用户体验,智能问答系统需要不断优化以生成更准确、满足客户需求的回答。现今常用的智能问答系统还存在一些弊端,智能问答还有可提升空间。
2、最近,大型语言模型(llm)在多个任务上表现出卓越性能。然而,llm的庞大规模和计算需求带来的挑战却给模型发展带来了巨大难题。llm需要大量的计算资源进行训练和推理,这使得训练和推理过程变得十分耗时。训练过程中,llm需要进行大量的矩阵运算,例如转置、矩阵乘法等操作,这些操作需要大量的gpu计算资源。
3、基于大模型的本地知识库问答系统是一种基于强大的语言模型进行问题理解的问答系统,它将大量的知识数据存储在本地数据库中,提供快速准确的答案,系统使用自然语言处理和机器学习技术,将用户问题与知识库中的信息进行匹配,从而找到最合适的答案。该系统的缺点是需要大量的计算资源和存储空间来支持大模型和知识库,同时需要花费较多的时间和精力来构建和维护本地知识库。
4、基于以上情况,当前一种被称为模型压缩的方法可以成为解决方案。这种方法可以将大型、资源密集型模型转换为适合存储在受限移动设备上的紧凑版本,同时优化模型以最小的延迟更快执行,或实现这些目标之间的平衡。量化是将大模型转化为适合部署的小模型的一种技术,可以减少模型的存储空间、内存占用和计算资源消耗。量化处理会对模型参数进行压缩,降低精度,从而减小模型。
5、对大模型做量化处理后,可以将其与本地知识问答系统结合,以提供更快速、更高效的问答服务。这种结合方式可以通过量化处理,加快问答系统的响应速度。这对用户来说是非常有益的,因为他们可以更快地获得所需答案。另一方面,通过对大模型的量化处理,可以进一步增强本地知识库的质量和深度,这使得问答系统能够更全面地覆盖各个领域,并提供更准确、更详细的答案。
6、量化处理时,先确定一个合适的激活值范围,再选用relu函数,因为该函数能够有效提高神经网络的非线性表达能力。该函数对激活值进行截断,将负的激活值设为0,正的激活值保留。然而,relu函数也存在一些问题:对于那些小于0的激活值,它们会被直接设置为0,导致信息的丢失。尤其是在一些需要保留细节和微小信息的任务中,可能会对模型的性能产生负面影响。
技术实现思路
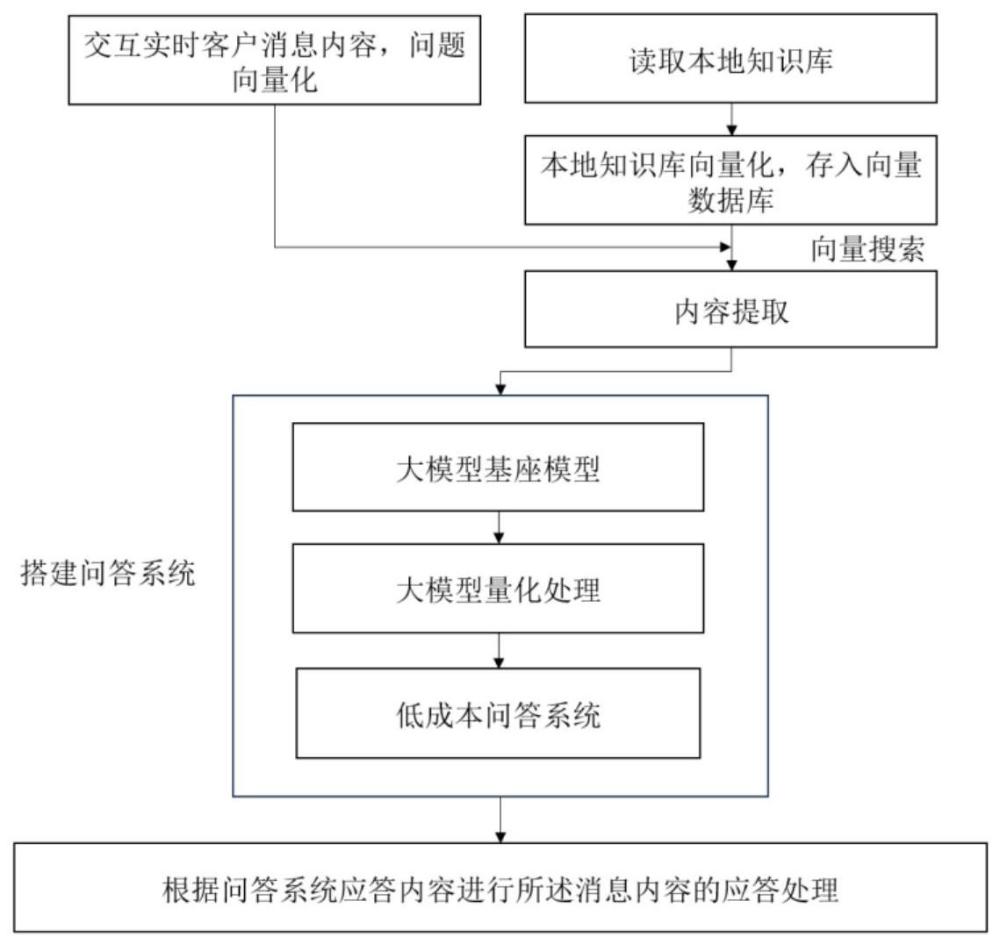
1、为解决现有技术存在的问题,本发明提出一种大模型的本地知识库智能问答系统,该系统包括以下模块:
2、(1)本地向量数据库搭建模块,该模块在本地建立一个知识库,将文本转化为表征文本语义的向量,使用向量存储技术将其分解成块并存储在向量数据库中;同时实时获取网页交互中的客户消息内容,对问题进行向量化处理,得到向量;
3、(2)大模型量化处理模块,根据任务需求选择合适的基座模型,对大型模型进行量化处理;
4、(3)低成本问答系统构建模块,将实时获取网页交互中的客户消息内容向量化与本地向量数据库模块进行匹配,最后通过索引搜索得到相似度最高的内容,对向量检索得到的内容进行处理,将其输入到大模型中完成问答过程。
5、进一步地,将文本转化为表征文本语义的向量时采用其中,jcbow(θ)为损失函数,θ为模型参数,σ为sigmoid函数,v′c为实际中心词的词向量,为上下文词向量的平均,v′i为负采样得到的负样本词的词向量,k为进行负采样的负样本数量,τ为温度参数。
6、进一步地,在大模型量化处理模块中,量化操作可采用权重量化、权重激活量化或动态量化。
7、进一步地,权重激活量化时,确定一个合适的激活值范围,选用reluα(x)函数激活值进行截断,其中α为预设阈值。
8、基于上述系统,本发明又提出一种大模型的本地知识库智能问答方法,该方法包括以下步骤:
9、(1)在本地建立一个知识库,将文本转化为表征文本语义的向量,使用向量存储技术将其分解成块并存储在向量数据库中;实时获取网页交互中的客户消息内容,对问题进行向量化处理,得到向量;基于本地知识向量数据库与向量化处理后的问题进行匹配,通过搜索得到相似度最高的内容。
10、(2)根据任务需求选择合适的基座模型,对大型模型进行量化处理;
11、(3)将实时获取网页交互中的客户消息内容向量化与本地向量数据库模块进行匹配;最后通过索引搜索得到相似度最高的内容,对向量检索得到的内容进行处理,将其输入到大模型中完成问答过程。
12、进一步地,将文本转化为表征文本语义的向量时采用其中,jcbow(θ)为损失函数,θ为模型参数,σ为sigmoid函数,v′c为实际中心词的词向量,为上下文词向量的平均,v′i为负采样得到的负样本词的词向量,k为进行负采样的负样本数量,τ为温度参数。
13、进一步地,在大模型量化处理时,量化操作可采用权重量化、权重激活量化或动态量化。
14、进一步地,权重激活量化时,确定一个合适的激活值范围,选用reluα(x)函数激活值进行截断,其中α为预设阈值。
15、通过调整阈值α的大小,可以平衡信息的保留和最大值的异常消除。x≥α时,reluα(x)函数对输出结果进行限制,这个限制可以根据实际需求的精度自定义α的值,在移动端低精度情况下,也能有较好的数值分辨率;当0<x<α时,输出结果为xe-x,与relu函数相比,reluα(x)导数不连续且相对较小,这使得输入值的正负对权值参数的更新影响更大,能增大输入正负值的区分度;x≤0时,输出结果为0,保证该函数的稀疏性,使稀疏后的模型能够更好地挖掘相关特征,拟合数据。
16、本发明又提供了一种设备,所述设备包括:数据采集装置、处理器和存储器;所述数据采集装置用于采集数据;所述存储器用于存储一个或多个程序指令;所述处理器,用于执行一个或多个程序指令,用以执行上述任一项方法。
17、本发明又提供了一种计算机可读存储介质,所述计算机存储介质中包含一个或多个程序指令,所述一个或多个程序指令用于执行上述任一项方法。
18、文本转化为表征文本语义的向量过程采用的是word2vec算法的cbow模型,其本质是通过背景词来预测目标词。该损失函数的目标是最小化给定上下文的情况下预测正确中心词的概率,同时将负样本的概率最大化,通过调整词向量使得损失函数达到最小值。同时引入温度参数τ调整函数的尖锐度,较大的温度值会使函数分布更加平滑,产生更均匀的概率分布;而较小的温度值会使分布更加尖锐,产生更集中的概率,这有助于控制模型输出的尺度。相比较于奇异值分解向量表示等算法,本发明采用的算法能够捕捉语义相似的词汇关系,使用上下文的背景词来预测目标词,可以更好的表达它们之间的语义关联。通过word2vec算法,智能问答系统在查询时快速检索相似的词汇,生成的向量对上下文感知性能较好,有助于提高问答系统的查询效率,用户能够更快地获取相关信息。
19、通过以上激活函数,可以加速模型训练,避免梯度消失,提高模型稀疏性,提升模型收敛速度。本发明得到的问答系统高效、准确、可靠,可以满足各种实际应用场景的需求。同时,该问答系统的成本和存储需求相对较低,可以更好地适应各种资源和预算的限制。
- 还没有人留言评论。精彩留言会获得点赞!