基于弱监督的农业社会化销售服务用户评价数据分析方法
本发明属于自然语言处理,具体涉及一种基于弱监督的农业社会化销售服务用户评价数据分析方法。
背景技术:
1、在当下的农业生产模式中,生产主体大多以家庭为单位。在农业生产的各个环节遇到的情况、发生的问题都需要农户独立解决,生产风险需要农户独立承担。这种传统的家庭农场模式往往会导致投身农业生产的农户面临劳动强度高、收入回报低等困境。为了分担广大农户的农业生产压力,有必要推动农业社会化服务体系的发展和完善。农业社会化服务是指农业合作社、涉农企业等机构对以家庭为单位的农户提供产前、产中、产后的一系列服务。它可以分为生产作业服务、农资服务、信息服务、农技服务、销售服务五个方面。其中,销售服务是产后服务中最关键的一环,它是指社会化服务提供者为农户代为销售农产品的过程。农产品受季节、温度等因素影响,价格会出现波动,对于农户而言,在独立出售农产品时可能会遇到缺乏市场导向、出现价格波动带来的损失,因此当下越来越多社会化服务组织为农户提供线上销售服务,同时各大电商平台也纷纷开展了助农直播且设置了地产销对接专区,逐渐形成了一种农业社会化销售服务模式。这种模式可以帮助农民提高销售收入,减少中间的利润抽取,同时也可以让消费者购买到更加优质、安全的农产品。然而,当下农业社会化销售服务正处于不断发展的阶段,农产品社会化销售提供者需要了解顾客满意度,收集顾客反馈,以便于及时调整策略,而目前尚且缺乏一种能够对农业社会化销售服务用户评价数据进行分析的方法。
技术实现思路
1、本发明的目的是提出一种基于弱监督的农业社会化销售服务用户评价数据分析方法,本发明通过增量式爬虫从一些电商平台之上获取农产品信息以及用户评价数据,并对用户评价数据进行分析得出顾客在品质、口感等评价维度上的满意度,以便于社会化销售服务提供者了解消费者需求和偏好,了解当前农产品销售情况存在的不足,以及确定市场定位和制定营销策略。针对用户评价数据无标签这一情况,本发明采用句法依存与基于情感词典的情感值判断方法相结合,得到每一个用户评价在各个评价维度上的满意度。然而这种方式生成的标签准确一般,其中存在大量谬误,因此把其称为伪标签。为了提高准确情况,本发明构建了一种粗细粒度联合分析多标签多分类的农业社会化销售服务分析模型,在伪标签数据集之上进行弱监督学习,从而得到一个更加精准的预测各评价维度满意情况的农业社会化销售服务分析模型。本发明还引入了dsc损失,使农业社会化销售服务分析模型能够避免在处理样本极度不平衡的数据集时,出现多数类样本淹没少数类样本,导致无法预测的情况。
2、本发明通过下述技术方案来实现。
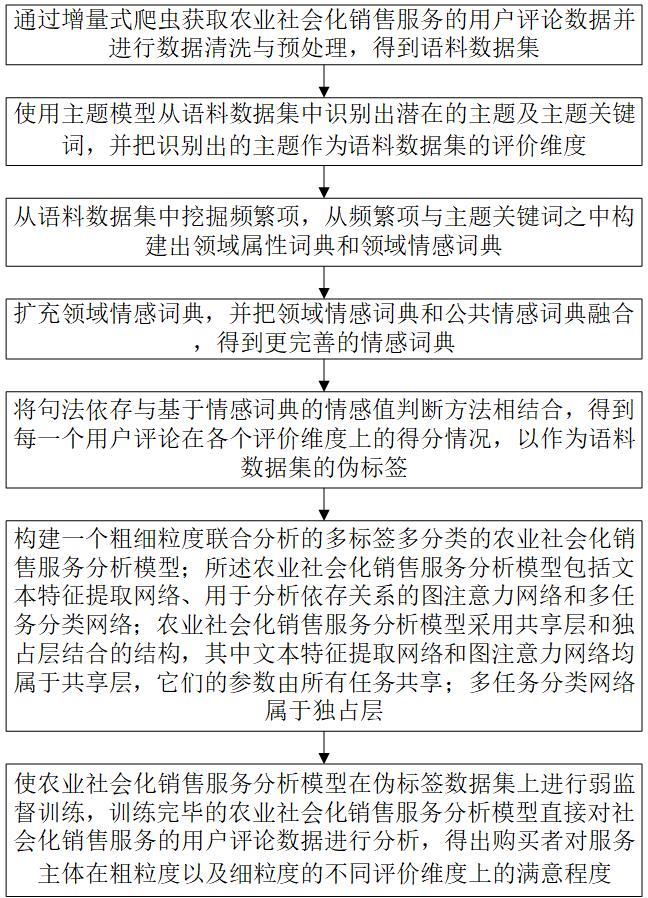
3、一种基于弱监督的农业社会化销售服务用户评价数据分析方法,步骤如下:
4、步骤一:通过增量式爬虫获取农业社会化销售服务用户评价数据并进行数据清洗与预处理,得到语料数据集;
5、步骤二:使用主题模型从语料数据集中识别出潜在的主题及主题关键词,并把识别出的主题作为语料数据集的评价维度;
6、步骤三:从语料数据集中挖掘频繁项,从频繁项与主题关键词之中构建出领域属性词典和领域情感词典;
7、步骤四:扩充领域情感词典,并把领域情感词典和公共情感词典融合,得到更完善的情感词典;
8、步骤五:将句法依存与基于情感词典的情感值判断方法相结合,得到每一个用户评价在各个评价维度上的得分情况,以作为语料数据集的伪标签;
9、步骤六:构建一个粗细粒度联合分析的多标签多分类的农业社会化销售服务分析模型;所述农业社会化销售服务分析模型包括文本特征提取网络、用于抽取标签间关联的图注意力网络和多任务分类网络;农业社会化销售服务分析模型采用共享层和独占层结合的结构,其中文本特征提取网络和图注意力网络均属于共享层,共享层的参数由所有任务共享;多任务分类网络属于独占层;
10、步骤七:使农业社会化销售服务分析模型在伪标签数据集上进行弱监督训练,训练完毕的农业社会化销售服务分析模型直接对社会化销售服务的用户评价数据进行分析,得出购买者对服务主体在粗粒度以及细粒度的不同评价维度上的满意程度。
11、进一步优选,所述文本特征提取网络对用户评价进行字粒度拆分和词粒度拆分,分别对字与词进行嵌入,得到字向量与词向量,把字向量与词向量拼接之后输入到双向简单循环网络中,从而得到用户评价的表征。
12、进一步优选,所述图注意力网络抽取出标签之间的联系,首先它将每个标签视作一个节点,构建出节点描述矩阵,这是一个n行d列的二维矩阵,其中n表示标签数,d表示维度;其次,再根据样本的标签分布情况得到n行n列的节点邻接矩阵;最后把节点描述矩阵和节点邻接矩阵输入到图注意力网络中,从而来捕获标签之间的关联与依赖;将双向简单循环网络输出的用户评价的表征与图注意力网络提取的标签间关联进行拼接融合得到融合特征,把融合特征输入到多任务分类网络中,多任务分类网络内包含多个独立的线性层,每个线性层分别对融合特征进行降维,最后得到农业社会化销售服务分析模型对用户评价在各评价维度上满意情况的预测结果。
13、进一步优选,所述图注意力网络把每个标签都视为图中的一个节点,其中图注意力网络的每一层中节点对应的注意力系数表示为:
14、;
15、其中,表示第层中节点j对节点i的重要程度;f是注意力函数;表示第层中节点i的特征,由-1层的节点i聚合自身以及领域节点之后得到;表示第层中节点j的特征,由-1层的节点j聚合自身与领域节点后得到;表示第层的卷积权重。
16、进一步优选,所述图注意力网络中,节点2在第层的特征向量为:
17、;
18、其中relu是激活函数,、、、分别是在第层上节点2、节点1、节点3、节点4对节点2的注意力系数;、、、分别为第层中节点1、节点2、节点3、节点4的特征。
19、进一步优选,首先从整个伪标签数据集中抽取部分样本进行人工更正标签,把人工更正标签的样本作为纯净训练集,使用纯净训练集训练农业社会化销售服务分析模型;把其余伪标签数据集划分为5等分,使用fasttext模型进行五折交叉验证,从而得到每个样本的预测值;求得每个标签类别的预测值的均值,以此作为阈值,仅在某标签类别上的预测值大于阈值时,fasttext模型预测伪标签是属于这个标签类别的;
20、进一步得到估计噪声标签和真实标签的联合分布:
21、;
22、;
23、其中i表示样本编号,m表示伪标签的标签类别总数,j表示其中一个标签类别;若伪标签的情感极性分为积极、消极、矛盾三种,则表示该伪标签下有三种标签类别,m=3;是m行m列的计数矩阵,计数矩阵的值是从样本中统计得到的,列表示伪标签在标签类别j上的个数,行表示fasttext模型预测值为标签类别j的个数;该矩阵使用下标与来指定矩阵中的一个值,若,,则表示伪标签为1,fasttext模型预测的标签也为1的样本个数;表示伪标签为i的样本总个数;是标定计数矩阵,对标定计数矩阵进行正则化,正则化之后得到估计噪声标签和真实标签的联合分布矩阵;然后即选取联合分布矩阵中最大的概率对应的下标与人工标签不一致的样本作为低置信度样本;fasttext、农业社会化销售服务分析模型、事先定义的标签函数三者将对低置信度样本进行重新预测,三者的预测值可能并不一致,因此把三者预测值均送入标签模型中,标签模型会输出最终的预测结果,把最终预测结果作为低置信度样本的矫正标签;矫正标签之后的低置信度样本将与高置信度样本一起从伪标签数据集中抽取出,放入到纯净数据集中训练农业社会化销售服务分析模型,持续这个过程,直到伪标签数据集中的数据全部进入了纯净训练集为止。
24、进一步优选,使用textrank算法从语料数据集中挖掘频繁项。
25、进一步优选,通过so-pmi算法扩充领域情感词典。
26、进一步优选,采用dsc损失来训练农业社会化销售服务分析模型。
27、进一步优选,所述主题模型是基于伪文档的主题模型(ptm)。
28、进一步优选,使用t-sne算法对农业社会化销售服务分析模型中的多任务分类网络的输出向量进行降维。
29、本发明还提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现所述基于弱监督的农业社会化销售服务用户评价数据分析方法。
30、本发明提供了一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现所述基于弱监督的农业社会化销售服务用户评价数据分析方法。
31、本发明把句法依存与基于情感词典的情感值判断方法相结合,对通过增量式爬虫爬取到的语料数据构建伪标签,还构建了一个农业社会化销售服务分析模型,使农业社会化销售服务分析模型在伪标签数据集中进行弱监督学习,从而建立更精确的社会化服务销售评价模型,具有以下优点:
32、1.当前中文的有标注语料数据集极少,许多其他专利中的方法在验证效果时均使用了英文数据集。一般的深度学习方法均依赖于一个强标注数据集,然而目前不存在公开的关于农业社会化销售服务的语料数据集,更无标注信息。此外,对语料数据集进行人工标注工作量极大,并不现实。基于此本发明提出一种针对无标签文本的深度学习方法,该方法不依赖于有标注的数据集,而是从收集数据开始构建自己的数据集。该方法先使用句法依存和基于情感词典的情感值判断法结合,为语料数据生成伪标签,再在伪标签之上进行弱监督学习,训练深度农业社会化销售服务分析模型。农业社会化销售服务分析模型训练时虽然基于伪标签,然而它的预测效果会优于句法依存和基于情感词典的情感值判断法结合生成的伪标签。
33、2.一个用户评价中可能涉及了对不同维度的评价,比如“柚子味道不错,但是价格太贵了”。如果仅使用粗粒度情感分析对句子整体的情感倾向进行判断就难以把握用户在不同维度上的满意程度。因此本发明构建粗细粒度联合分析的社会化服务销售评价模型。它属于多标签多分类网络,对于一个样本,它将会有多个标签,且每一个标签下有多种分类。该社会化服务销售评价模型在预测各个评价维度的满意度时可以很好的把握不同的标签之间的关联。该社会化服务销售评价模型不仅可以预测细粒度上各个维度的情感极性,同时还能预测粗粒度,即评价整体的情感极性。
34、3.引入dsc损失提高在样本不平衡数据集上网络模型的鲁棒性。对于正负比例极端的样本数据集,容易出现少数类样本被多数类样本淹没的情况,对此采用dsc损失、动态权重调整,增加少数类样本的损失值权重来提升网络性能。且相较于焦点损失,dsc损失不会过于关注难分样本和离群值,在弱监督学习中有着更好的效果。
- 还没有人留言评论。精彩留言会获得点赞!