基于动态自适应分组的文本生成式隐写方法及装置
本技术涉及信息安全,特别涉及一种基于动态自适应分组的文本生成式隐写方法及装置。
背景技术:
1、隐写技术是对加密技术的有利补充,该技术通过将秘密信息隐藏到载体中从而使得信息传递过程不被第三方察觉,从而实现对个人隐私等关键信息的保护,在国防、隐私保护等方面有着广阔的应用前景。隐写技术的发展历史悠久,近年来,随着互联网和多媒体技术的快速发展和广泛应用,研究人员开始使用数字媒体做为隐写载体,如文本、图像、音视频等典型数字媒体。相比于图像、音视频等载体,文本具备在几乎所有场景均可使用的高自由度特性和不易受主动干扰而丢失信息的高鲁棒特性,使得相关的隐写方法具有极强的实用价值,受到了研究人员的广泛关注。
2、当今主流的文本隐写技术可以分为基于文本格式的隐写术和基于文本内容的隐写术。基于文本格式的隐写术主要利用文本在特定文档中的组织、排版和呈现时的特定规则实化,如通过修改pdf文档中字符间的位置信息来实现信息嵌入,该方法通常使用场景有限,且文字的重新录入、内容转移和格式变化都可能导致隐蔽信息的损失;基于文本内容的隐写术,又称为语言隐写术,主要利用文本中的语言特征实现隐蔽信息嵌入,该类方法主要有修改式、检索式和生成式三种隐写策略。检索式语言隐写术通过对大规模文本库中的样本进行特殊编码,然后根据待嵌入的秘密信息选择对应的语句进行传输,这种方式需要共享大规模语料库,并且隐藏容量低。修改式语言隐写术主要是对文本中的语义单元进行同义替换以嵌入隐蔽信息,如通过同义词替换来实现信息的嵌入,这类方式同样地难以实现较高的隐藏容量,难以传递大量信息。生成式语言隐写术则是根据待嵌入的秘密信息自动生成一段自然文本,同时在生成过程中对文本语义单元进行编码实现隐蔽信息嵌入,具体而言,基于语言模型预测生成下一个单词或者字符时的条件概率分布,然后基于该分布进行编码,通过选择不同的单词或者字符生成来实现秘密信息(通常为比特流)的嵌入,这种策略不需要事先给定嵌入秘密信息的载体,因此在嵌入信息过程中有更大的自由度,可以获得较高的信息隐藏容量。
3、然而,生成式隐写策略面临的挑战同样非常巨大,由于文本极高的表达自由度、秘密信息的随机性和不可控性,生成的隐写文本往往与自然文本存在较大的统计差异,隐蔽性较低,使得监听者很容易察觉到隐写文本的存在。
4、目前,现有技术可使用概率最高的前k个单词进行霍夫曼编码,在一定程度上提升了隐蔽性,但霍夫曼编码存在计算复杂度高、编码效率低的问题,导致实际应用时隐藏容量低;现有技术还可通过计算秘密信息即比特流分布与条件概率分布的kullback-leible(kl)散度,并设置一个阈值,仅当kl散度小于阈值时才使用霍夫曼编码嵌入信息,进一步提升了隐蔽性,但该方法会在实际应用时导致单个单词位置隐藏容量低,且由于仅部分单词位置能隐藏信息,使得整体隐藏容量低;现有技术还可使用一种对文本分布使用算术编码来嵌入秘密信息的方法,实现较高的嵌入率,并提升其隐蔽性,但该方法为了保障文本生成质量,仅能针对概率较高的若干单词进行编码,使得整体嵌入容量受限;此外,现有技术还可利用算术编码方法,对生成过程每一步的条件概率分布分别进行独立的算术编码,然而这种方式没有充分利用文本的熵,降低了隐藏容量。
5、综上所述,在实际应用中,现有技术会导致单个单词位置隐藏容量低,且由于仅部分单词位置能隐藏信息,使得整体隐藏容量低,且现有技术仅能针对概率较高的若干单词进行编码,没有充分利用文本熵,降低了隐写文本整体隐藏容量,导致整体嵌入容量受限,无法在保证高隐藏容量的情况下,提高隐写文本的高隐蔽性,亟待解决。
技术实现思路
1、本技术提供一种基于动态自适应分组的文本生成式隐写方法及装置,以解决现有文本生成式隐写技术中的高隐蔽性和高隐藏容量难以兼顾等问题。
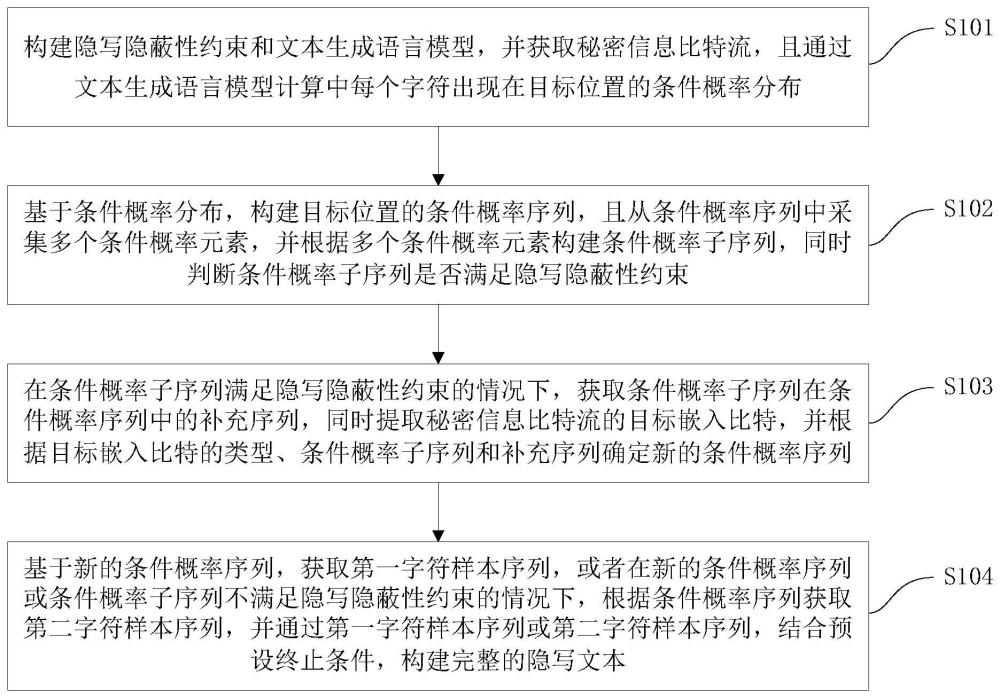
2、本技术第一方面实施例提供一种基于动态自适应分组的文本生成式隐写方法,包括以下步骤:构建隐写隐蔽性约束和文本生成语言模型,并获取秘密信息比特流,且通过所述文本生成语言模型计算每个字符出现在目标位置的条件概率分布;基于所述条件概率分布,构建所述目标位置的条件概率序列,且从所述条件概率序列中采集多个条件概率元素,并根据所述多个条件概率元素构建条件概率子序列,同时判断所述条件概率子序列是否满足所述隐写隐蔽性约束;在所述条件概率子序列满足所述隐写隐蔽性约束的情况下,获取所述条件概率子序列在所述条件概率序列中的补充序列,同时提取所述秘密信息比特流的目标嵌入比特,并根据所述目标嵌入比特的类型、所述条件概率子序列和所述补充序列确定新的条件概率序列;基于所述新的条件概率序列,获取第一字符样本序列,或者在所述新的条件概率序列或所述条件概率子序列不满足所述隐写隐蔽性约束的情况下,根据所述条件概率序列获取第二字符样本序列,并通过所述第一字符样本序列或第二字符样本序列,结合预设终止条件,构建完整的隐写文本。
3、可选地,在本技术的一个实施例中,所述基于所述条件概率分布,构建所述目标位置的条件概率序列,且从所述条件概率序列中采集多个条件概率元素,并根据所述多个条件概率元素构建条件概率子序列,同时判断所述条件概率子序列是否满足所述隐写隐蔽性约束,包括:通过每个字符出现在所述目标位置的条件概率,对所述每个字符的条件概率进行降序排列,构建所述条件概率序列;基于所述预设抽样策略和所述条件概率序列,构建所述条件概率子序列,并叠加所述条件概率子序列中的所有条件概率元素,得到条件概率元素和,且判断所述条件概率元素是否满足所述隐写隐蔽性约束。
4、可选地,在本技术的一个实施例中,所述根据所述目标嵌入比特的类型、所述条件概率子序列和所述补充序列确定新的条件概率序列,包括:当所述目标嵌入比特为第一预设值时,则将所述条件概率子序列作为所述新的条件概率序列;当所述目标嵌入比特为第二预设值时,则将所述条件概率子序列的补充序列作为所述新的条件概率序列;获取新的目标嵌入比特,并基于所述新的目标嵌入比特更新所述新的条件概率序列,迭代进行所述新的目标嵌入比特获取和所述新的条件概率序列更新操作,直到所述新的条件概率序列满足预设迭代结束条件,得到最终的新的条件概率序列。
5、可选地,在本技术的一个实施例中,所述基于所述新的条件概率序列,获取第一字符样本序列,或者在所述新的条件概率序列或所述条件概率子序列不满足所述隐写隐蔽性约束的情况下,根据所述条件概率序列获取第二字符样本序列,并通过所述第一字符样本序列或第二字符样本序列,结合预设终止条件,构建完整的隐写文本,包括:分别对所述新的条件概率序列或所述条件概率序列进行归一化处理,得到第一标准条件概率序列或第二标准条件概率序列;基于所述第一标准条件概率序列或所述第二标准条件概率序列,结合预设采样策略,构建所述第一标准条件概率序列对应的第一字符样本序列,或者所述第二标准条件概率序列对应的第二字符样本序列;提取所述第一字符样本序列或所述第二字符样本序列对应的待拼接字符,并将所述待拼接字符与当前隐写文本进行拼接处理,生成新的隐写文本;判断所述新的隐写文本是否满足所述预设终止条件,并在所述新的隐写文本满足所述预设终止条件的情况下,输出所述新的隐写文本,否则循环执行条件概率序列构建与待拼接字符生成和拼接操作,直至得到的隐写文本满足所述预设终止条件,生成所述完整的隐写文本。
6、本技术第二方面实施例提供一种基于动态自适应分组的文本生成式隐写装置,包括:计算模块,用于构建隐写隐蔽性约束和文本生成语言模型,并获取秘密信息比特流,且通过所述文本生成语言模型计算每个字符出现在目标位置的条件概率分布;判断模块,用于基于所述条件概率分布,构建所述目标位置的条件概率序列,且从所述条件概率序列中采集多个条件概率元素,并根据所述多个条件概率元素构建条件概率子序列,同时判断所述条件概率子序列是否满足所述隐写隐蔽性约束;确定模块,用于在所述条件概率子序列满足所述隐写隐蔽性约束的情况下,获取所述条件概率子序列在所述条件概率序列中的补充序列,同时提取所述秘密信息比特流的目标嵌入比特,并根据所述目标嵌入比特的类型、所述条件概率子序列和所述补充序列确定新的条件概率序列;构建模块,用于基于所述新的条件概率序列,获取第一字符样本序列,或者在所述新的条件概率序列或所述条件概率子序列不满足所述隐写隐蔽性约束的情况下,根据所述条件概率序列获取第二字符样本序列,并通过所述第一字符样本序列或第二字符样本序列,结合预设终止条件,构建完整的隐写文本。
7、可选地,在本技术的一个实施例中,所述判断模块包括:排列单元,用于通过所述秘密信息比特流中每个字符出现在所述目标位置的条件概率,对所述每个字符的条件概率进行降序排列,构建所述条件概率序列;叠加单元,用于基于所述预设抽样策略和所述条件概率序列,构建所述条件概率子序列,并叠加所述条件概率子序列中的所有条件概率元素,得到条件概率元素和,且判断所述条件概率元素是否满足所述隐写隐蔽性约束。
8、可选地,在本技术的一个实施例中,所述确定模块包括:第一分析单元,用于当所述目标嵌入比特为第一预设值时,则将所述条件概率子序列作为所述新的条件概率序列;第二分析单元,用于当所述目标嵌入比特为第二预设值时,则将所述条件概率子序列的补充序列作为所述新的条件概率序列;第一循环单元,用于获取新的目标嵌入比特,并基于所述新的目标嵌入比特更新所述新的条件概率序列,迭代进行所述新的目标嵌入比特获取和所述新的条件概率序列更新操作,直到所述新的条件概率序列满足预设迭代结束条件,得到最终的新的条件概率序列。
9、可选地,在本技术的一个实施例中,所述构建模块包括:处理单元,用于分别对所述新的条件概率序列或所述条件概率序列进行归一化处理,得到第一标准条件概率序列或第二标准条件概率序列;采样单元,用于基于所述第一标准条件概率序列或所述第二标准条件概率序列,结合预设采样策略,构建所述第一标准条件概率序列对应的第一字符样本序列,或者所述第二标准条件概率序列对应的第二字符样本序列;拼接单元,用于提取所述第一字符样本序列或所述第二字符样本序列对应的待拼接字符,并将所述待拼接字符与当前隐写文本进行拼接处理,生成新的隐写文本;第二循环单元,用于判断所述新的隐写文本是否满足所述预设终止条件,并在所述新的隐写文本满足所述预设终止条件的情况下,输出所述新的隐写文本,否则循环执行条件概率序列构建与待拼接字符生成和拼接操作,直至得到的隐写文本满足所述预设终止条件,生成所述完整的隐写文本。
10、本技术第三方面实施例提供一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序,以实现如上述实施例所述的基于动态自适应分组的文本生成式隐写方法。
11、本技术第四方面实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储计算机程序,该程序被处理器执行时实现如上的基于动态自适应分组的文本生成式隐写方法。
12、由此,本技术的实施例具有以下有益效果:
13、本技术的实施例可通过构建隐写隐蔽性约束和文本生成语言模型,并获取秘密信息比特流,且通过文本生成语言模型计算每个字符出现在目标位置的条件概率分布;基于条件概率分布,构建目标位置的条件概率序列,且从条件概率序列中采集多个条件概率元素,并根据多个条件概率元素构建条件概率子序列,同时判断条件概率子序列是否满足隐写隐蔽性约束;在条件概率子序列满足隐写隐蔽性约束的情况下,获取条件概率子序列在条件概率序列中的补充序列,同时提取秘密信息比特流的目标嵌入比特,并根据目标嵌入比特的类型、条件概率子序列和补充序列确定新的条件概率序列;基于新的条件概率序列,获取第一字符样本序列,或者在新的条件概率序列或条件概率子序列不满足隐写隐蔽性约束的情况下,根据条件概率序列获取第二字符样本序列,并通过第一字符样本序列或第二字符样本序列,结合预设终止条件,构建完整的隐写文本,从而充分利用条件概率分布,生成了具备严格数学证明的高容量和高隐蔽的隐写文本。由此,解决了现有文本生成式隐写技术中的高隐蔽性和高隐藏容量难以兼顾等问题。
14、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!