融合预训练语言模型和图谱的变压器设备健康度评价方法
本发明涉及电力变压器设备图谱构建和健康度评价的分类领域,具体的涉及一种融合预训练语言模型和图谱的变压器设备健康度评价方法。
背景技术:
1、当前构建变压器或电力相关设备知识图谱的方法,通常采用先构建设备语料库,然后通过分词、去停词、将训练文本转化为词向量、计算词向量相似度方式等步骤构建图谱,非端到端的方法,这些方法限于构建局部的图结构,而且人工标注数据和训练成本较大。在获取文本向量关系方面,缺乏感知全局图结构的能力。
2、已有研究提出一种构建知识图谱库的方法来开展设备状态评价工作,但未提及基于各类生产领域系统所产生的实时告警和异常描述,构建实时的动态的面向设备部件健康度的动态状态评价方法。此外,当前大部分对于变压器等电力设备状态评价的方式,往往通过对部分采集数据经算法处理后获取单一的告警,根据单一告警内容通过系统自动地或人工推理出设备的健康状态,但并未实现量化客观地评价。此外评价忽视了设备本体及其配套部件已积累的健康情况,以及告警对于影响设备正常运行的严重程度,同时忽视了一种设备部件的故障可能引起另一部件功能异常即共模故障的影响。
3、随着电力生产领域的数字化转型,行业内对变压器运行健康度评价越来越重视,然而相对于变压器的年度状态评价,其动态状态评价次数过低。究其原因,一是当前待评价设备的数量众多且设备动态评价变化较频密,难以做到人工频繁上单,目前仅少部分的评价项目可通过已有系统模块自动关联生成动态评价单,其余大部分评价项目需人工新增,由于过于依赖人为上单的主动性,且设备状态变化人工维护成本较高,广泛存在漏上单漏扣分的情况,导致整体评价分数不能反馈设备运行真实健康状态,不利于制定有效的差异化运维策略;二是评价方式过于死板,未能实时反映设备部件分数与整体的关联性,未能揭示评价项之间的内在关联性以及影响实际运行的严重程度;三是评价流程冗余,一个评价单需要经过多个流程审批才可生效,延误了设备隐患处置的最佳时机;四是大量与变压器设备评价相关的信息被存储在各类系统的数据库中,这些数据对整体评价结果存在一定的信息关联性但未被充分挖掘;五是评价结果未能体系化统计和可视化展示,不利于设备相关管理人员开展深层次的分析决策工作。
技术实现思路
1、本发明为了克服以上技术的不足,提供了一种融合预训练语言模型和图谱的变压器设备健康度评价方法,采用大语言模型mt5进行信息抽取并实现端到端的图谱构建,且用了改良bert+cosent算法进行文本匹配,通过告警触发的量化扣分机制来动态评价设备健康度状态。
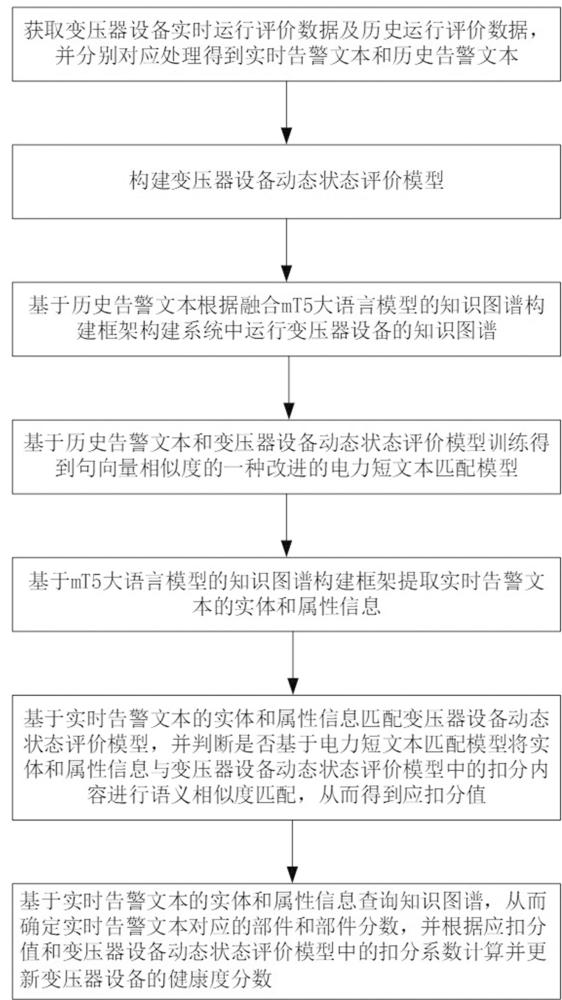
2、本发明克服其技术问题所采用的技术方案是:本发明提出的一种融合预训练语言模型和图谱的变压器设备健康度评价方法,包括获取变压器设备实时运行评价数据及历史运行评价数据,并分别对应处理得到实时告警文本和历史告警文本;构建变压器设备动态状态评价模型;基于历史告警文本根据融合mt5大语言模型的知识图谱构建框架构建系统中运行变压器设备的知识图谱;基于历史告警文本和变压器设备动态状态评价模型训练得到电力短文本匹配模型;基于mt5大语言模型的知识图谱构建框架提取实时告警文本的实体和属性信息;基于实时告警文本的实体和属性信息匹配变压器设备动态状态评价模型,并判断是否基于电力短文本匹配模型将实体和属性信息与变压器设备动态状态评价模型中的扣分内容进行语义相似度匹配,从而得到应扣分值;基于实时告警文本的实体和属性信息查询知识图谱,从而确定实时告警文本对应的部件和部件分数,并根据应扣分值和变压器设备动态状态评价模型中的扣分系数计算并更新变压器设备的健康度分数。
3、进一步的,所述实时运行评价数据及历史运行评价数据包括变压器相关的半结构化数据、结构化数据和非结构化数据的一种、几种的组合或全部。
4、进一步的,所述变压器设备动态状态健康度评价模型至少包括依次对应的设备大类,部件类型、状态量、扣分内容、应扣分数和扣分系数,变压器设备运行的整体分数基于各部件对应的扣分内容、应扣分数和扣分系数计算后叠加得到。
5、进一步的,所述扣分系数,为预设周期内同一个扣分内容对于同一个部件连续发生的发生次数,为预设第一部件的重要性系数;为累积故障率,为第一设备部件当前已累积的扣分项目数,若当前第一设备部件已扣分项目数为,总扣分项目数为η,其公式为。
6、综合考虑部件的重要程度、部件对应的累积已扣分项目、一段时间内连续发生的同一故障,综合评定变压器状态,创造性的提出了变压器设备动态状态评价模型的扣分系数。
7、进一步的,所述基于历史告警文本根据融合mt5大语言模型的知识图谱构建框架构建系统中运行变压器设备的知识图谱,包括知识图谱的节点生成和知识图谱的关系生成,所述知识图谱的节点生成具体包括:构建固定格式的生成式指令prompt文本,将其作为前缀与输入历史告警文本进行拼接得到输入文本,送入改进的mt5编码器;基于改进的mt5解码器对输入文本进行解码,生成输入文本的节点特征矩阵,其中所述改进的mt5解码器,将mt5解码器中的1组注意力掩码层改为1组多头注意力层;将节点特征矩阵送入至单层gru解码器,形成预设格式的文本序列,从而提取输入的历史告警文本对应的若干节点信息。
8、对传统的mt5大语言模型解码器进行改进,运用到了大语言模型mt5进行信息抽取并实现端到端的图谱构建。
9、进一步的,所述知识图谱的关系生成具体包括:将所述节点特征矩阵和节点特征阵转置的相乘得到节点特征邻接矩阵,并输入至bi-lstm模型从而提取输入历史告警文本的节点关系特征;以焦点损失作为损失函数从而输出节点间对应关系的类型。
10、进一步的,所述基于实时告警文本的实体和属性信息匹配变压器设备动态状态评价模型,并判断是否基于电力短文本匹配模型将实体和属性信息与变压器设备动态状态评价模型中的扣分内容进行语义相似度匹配,从而得到应扣分值,具体包括:基于正则化算法,将实体和属性信息对应的部件名称和状态量匹配变压器设备动态状态评价模型中的部件类型和状态量;若变压器设备动态状态评价模型中对应状态量的扣分内容项目数大于1,则将实时告警文本与状态量对应的扣分内容采用电力短文本匹配模型进行逐一匹配,否则直接确定扣分内容对应的应扣分值。
11、进一步的,所述基于历史告警文本和变压器设备动态状态评价模型训练得到电力短文本匹配模型,具体包括:将历史告警文本的描述内容与变压器设备动态状态评价模型的扣分内容,成对作为训练集的一个样本,并对每个样本赋予表示描述内容和扣分内容匹配程度的标签,所述标签取值为0或1;将一个训练样本的描述内容和扣分内容输入至chinese-bert-wwm-ext预训练语言模型中得到一次处理的句向量;将一次处理的句向量分别经过平均池化模型,得到二次处理句向量并基于标签取值计算余弦相似度;基于最小化的余弦相似度的损失函数为目标函数,更新chinese-bert-wwm-ext预训练语言模型和平均池化模型的参数,从而得到训练后的电力短文本匹配模型。
12、进一步的,所述基于电力短文本匹配模型将实体和属性信息与变压器设备动态状态评价模型中的扣分内容进行语义相似度匹配,具体包括:将实时告警文本的描述内容和对应变压器设备动态状态评价模型中的扣分内容分别输入至训练后的电力短文本匹配模型;并计算基于电力短文本匹配模型分别得到二次处理的句向量的余弦相似度;选择余弦相似度最大值对应的扣分内容作为最佳匹配结果。
13、通过告警触发的量化扣分机制来动态评价设备健康度状态,并采用了改进的bert+cosent算法进行文本匹配。
14、进一步的,所述基于实时告警文本的实体和属性信息查询知识图谱,从而确定实时告警文本对应的系统中运行变压器的部件和部件分数,并根据应扣分值和变压器设备动态状态评价模型中的扣分系数计算并更新系统中运行变压器设备的健康度分数,具体包括:基于实时告警文本的实体和属性信息,通过查询语句cypher查询知识图谱,从而得到知识图谱中对应的待评价的系统中运行变压器对应的部件和部件分数;基于变压器设备动态状态健康度评价模型中的扣分系数和应扣分数计算系统中运行变压器设备的整体分数。
15、本发明的有益效果是:
16、1、运用到了大语言模型mt5进行信息抽取并实现端到端的图谱构建,且采用了改良bert+cosent算法进行文本匹配,通过告警触发的量化扣分机制来动态评价设备健康度状态;
17、2、对传统的mt5大语言模型解码器进行改进,减少了位置编码positionalembedding,并把原来的一组注意力掩码层改为一组多头注意力层,解码器输出的隐含向量不受语义顺序的影响,即保证了后续生成的目标序列所对应的节点信息不受生成位置的约束,并确保最终生成的同一个图节点具有唯一性;
18、3、借助大语言模型在中文通用知识领域的预训练知识,充分运用了其在语义识别方面的强大能力和优秀的逻辑推理、文本生成能力,实现了对系统告警等短文本的语义向量高效提取;
19、4、创造性的提出了变压器设备动态状态评价模型的扣分系数,综合考虑部件的重要程度、部件对应的累积已扣分项目、一段时间内连续发生的同一故障,综合评定变压器状态;
20、5、借助知识图谱的可解释性和准确表述的能力,充分发挥知识图谱在知识存储特别是领域知识存储、检索、更新方面的优势,实现预训练语言模型和图谱二者的优势互补,达到对生产领域变压器相关运行评价数据的获取、更新和管理效果,进一步提升电力变压器运行状态动态评价的可用性和实用性。
- 还没有人留言评论。精彩留言会获得点赞!