一种基于GNN策略空间强化的舆情事件处置人推荐方法与流程
本发明涉及知识图谱,具体涉及一种基于gnn策略空间强化的舆情事件处置人推荐方法。
背景技术:
1、在社会矛盾调节工作中,群众经常通过网格员、线上app等方式上报婚姻纠纷、宅地纠纷、非法施工、打架斗殴等各类涉法事件,工作人员需要将这些事件分派给司法、公安、社区等部门的专业人员进行处置,及时化解社会矛盾。事件推荐系统的目标是在海量信息中找到最有效的处置人,并对处置人精准排序后输出。为了更好的解决推荐过程中的数据稀疏、冷启动数据匮乏等问题,近些年一般基于人工或自动构建知识图谱,结合协同过滤、逻辑回归、因子分解、组合模型、深度学习等技术手段实现图谱推荐和预测。常见的知识图谱推荐方法有基于节点/边向量表示的方法、基于图谱路径的方法、基于路径与向量融合的方法,其中,基于路径与向量融合的方法,既可以使用深度学习技术挖掘隐藏的特征以提升算法性能,在产业界受到普遍认同。
2、在基于路径与向量融合的方法中,目前比较流行的是图神经网络(gnn)推荐算法,其最大的问题是可解释性差,这主要是因为推荐模型仅在参数空间中进行优化(如adam优化算子),这种参数优化方法所产生的结果可能与人们的期望不一致。人们所期望的推荐路径的概率分布,在强化学习中被称为策略空间,策略空间优化一般采取人工反馈奖励模型来反作用于参数优化过程,从而使得推荐结果与人类意图一致。
技术实现思路
1、本发明为了克服以上技术的不足,提供了一种推荐过程更加符合人类意图的基于gnn策略空间强化的舆情事件处置人推荐方法。
2、本发明克服其技术问题所采用的技术方案是:
3、一种基于gnn策略空间强化的舆情事件处置人推荐方法,包括如下步骤:
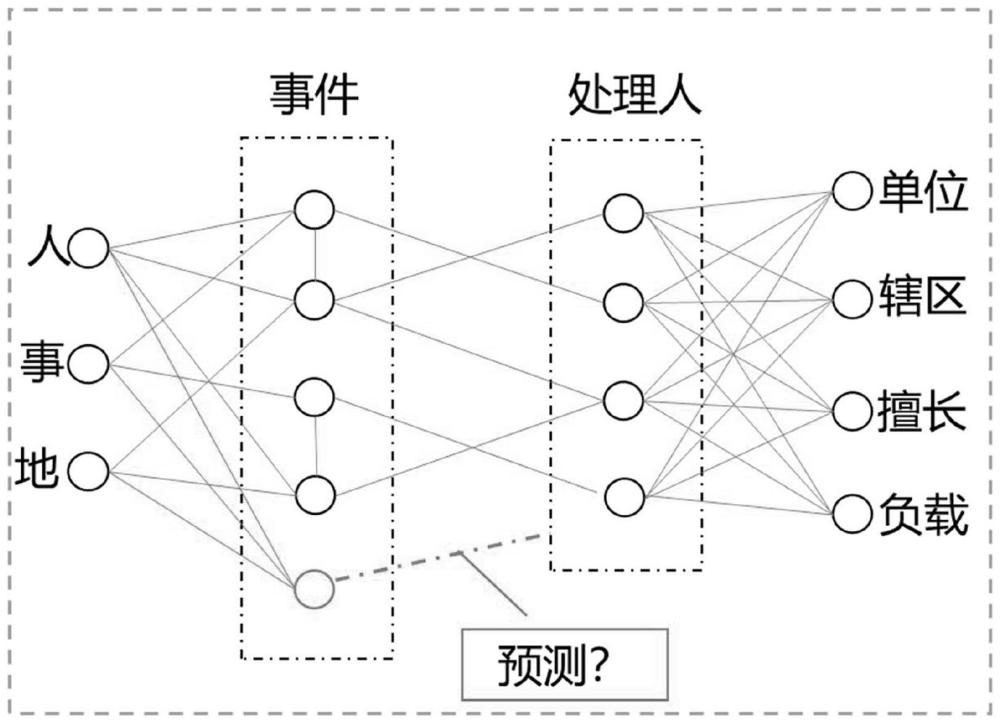
4、a)根据政务系统构建基于历史信息的知识图谱g(v,ε),其中v为节点集合,ε为边集合,节点集合v中包括事件节点、属性节点和处置人节点;
5、b)将节点集合v中第v个节点的文字信息转化为文本特征向量,得到第v个节点初始特征向量
6、c)将到第v个节点经过k层聚合操作,得到特征向量
7、d)训练图神经网络,得到推荐模型init-graph-model;
8、e)将一事件节点输入到推荐模型init-graph-model中得到该事件节点的特征向量e,计算该事件节点与各个处置人节点特征向量之间的余弦距离,选择q个处置人节点的特征向量{y1,y2,...,yi,...,yj,...,yq},yi为第i个处置人节点的特征向量,yj为第i个处置人节点的特征向量,i∈{1,...,q},j∈{1,...,q},i≠j;f)训练奖励模型,得到训练后的奖励模型init-reward-model;
9、g)采用联合训练的方式训练推荐模型init-graph-model,得到推荐模型active-graph-model,采用联合训练的方式训练奖励模型init-reward-model,得到奖励模型active-reward-model;
10、h)在知识图谱中加入新的事件节点u″,得到知识图谱g(v′,ε′),重复执行步骤b)至步骤c)得到节点集合v′中事件节点u″的特征向量将特征向量输入到推荐模型active-graph-model中,计算事件节点u″与各个处置人节点特征向量之间的余弦距离,得到推荐处置人排序。
11、进一步的,步骤a)中事件节点与事件节点之间的链接关系以及事件节点与处置人节点之间的链接关系构成边集合ε。
12、进一步的,属性节点包括:人、主诉、地点、发生时间、上报时间,处置人节点包括:所在部门、所辖区域、擅长技能、当前负载。
13、进一步的,步骤b)中节点集合v中各个节点的文字信息通过bert模型转化为文本特征向量。
14、进一步的,步骤c)中将初始特征向量xv输入到k层的graphsage图卷积神经网络中,输出得到特征向量graphsage图卷积神经网络第k层输出的嵌入特征向量为进一步的,步骤d)包括如下步骤:
15、d-1)通过公式计算得到损失函数ltriplet(u),式中m为正则超参数,t为转置,为第ui1个节点经过k层聚合操作得到的特征向量,为第ui2个节点经过k层聚合操作得到的特征向量,ui1,ui2∈v;
16、d-2)使用adam优化器通过损失函数ltriplet(u)训练graphsage图卷积神经网络,得到推荐模型init-graph-model。
17、进一步的,步骤f)包括如下步骤:
18、f-1)构造节点特征向量对{(e,y1),(e,y2),...,(e,yi),...,(e,yj),...,(e,yq)};
19、f-2)建立奖励模型,奖励模型由bert的输出的第一个token[cls]连接至多层感知机构成;
20、f-3)通过公式
21、计算得到损失函数lreward,式中为排列组合函数,sigmoid(·)为sigmoid函数,rψ(e,yi)为将节点特征向量对(e,yi)输入到奖励模型中输出得到的奖励值,rψ(e,yj)为将节点特征向量对(e,yj)输入到奖励模型中输出得到的奖励值;
22、f-4)使用adam优化器通过损失函数lreward训练奖励模型,得到训练后的奖励模型init-reward-model。
23、进一步的,步骤g)包括如下步骤:
24、g-1)通过公式lgraph=lppo-clip-c1rψ(e,yi)+ltriplet(u)计算得到推荐模型损失函数lgraph,式中lppo-clip为ppo-clip损失,ppo-clip损失中计算ppo散度所采用概率空间为m为处置人节点的个数,c1为超参数,t为转置;
25、g-2)使用adam优化器通过推荐模型损失函数lgraph训练推荐模型init-graph-model,得到推荐模型active-graph-model;
26、g-3)将第u个事件节点输入到推荐模型active-graph-model中得到该事件节点的特征向量e′,计算第u个事件节点与各个处置人节点特征向量之间的余弦距离,选择q个处置人节点的特征向量{y′1,y′2,...,y′i,...,y′q},y′i为第i个处置人节点的特征向量,i∈{1,...,q},构造节点特征向量对{(e′,y′1),(e′,y′2),...,(e′,y′i),...,(e′,y′q)};
27、g-4)通过公式lvf=(rψ(e′,y′i)-rψ(e,yi))2计算得到奖励模型损失函数lvf,式中rψ(e′,y′i)为将节点特征向量对(e′,y′i)输入到奖励模型中输出得到的奖励值;
28、g-5)使用adam优化器通过奖励模型损失函数lvf训练奖励模型init-reward-model,得到奖励模型active-reward-model。
29、本发明的有益效果是:采用深度学习模型参数空间优化和策略空间优化相接合的方式设计一种新型图神经网络架构和奖励模型-策略空间协同优化方法,使得推荐过程更加符合人类意图。
- 还没有人留言评论。精彩留言会获得点赞!