一种基于机器学习的高维数据降维方法及降维系统与流程
本发明涉及数据处理,尤其涉及一种基于机器学习的高维数据降维方法及降维系统。
背景技术:
1、在互联网高速发展的时代下数据处理的数据维度的范围也更加广泛,随着数据的维度增加,数据样本量需求的增长是指数级的,从而使得模型训练变得困难和计算密集。在高维数据空间中,数据点之间的距离变得几乎相等,削弱很多数据处理对于结果的判别力,并且庞大的数据量增加数据处理的压力,对高位数据进行数据降维可以揭示数据的内在结构,提高数据处理速度,减少资源消耗,并且有助于可视化和理解复杂数据集。然而,传统的高维数据降维方法对于高维数据的降维选取不够精准,并且降维后的高位数据中每个维度数据还是存在庞大的数据量,使降维效果较差。
技术实现思路
1、基于此,本发明提供一种基于机器学习的高维数据降维方法及降维系统,以解决至少一个上述技术问题。
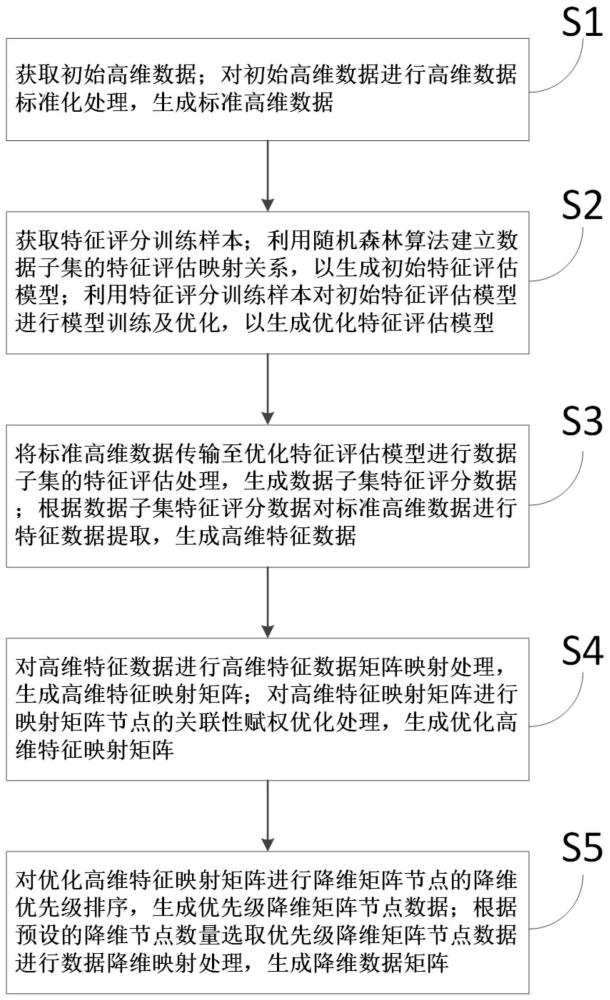
2、为实现上述目的,一种基于机器学习的高维数据降维方法,包括以下步骤:
3、步骤s1:获取初始高维数据;对初始高维数据进行高维数据标准化处理,生成标准高维数据;
4、步骤s2:获取特征评分训练样本;利用随机森林算法建立数据子集的特征评估映射关系,以生成初始特征评估模型;利用特征评分训练样本对初始特征评估模型进行模型训练及优化,以生成优化特征评估模型;
5、步骤s3:将标准高维数据传输至优化特征评估模型进行数据子集的特征评估处理,生成数据子集特征评分数据;根据数据子集特征评分数据对标准高维数据进行特征数据提取,生成高维特征数据;
6、步骤s4:对高维特征数据进行高维特征数据矩阵映射处理,生成高维特征映射矩阵;对高维特征映射矩阵进行映射矩阵节点的关联性赋权优化处理,生成优化高维特征映射矩阵;
7、步骤s5:对优化高维特征映射矩阵进行降维矩阵节点的降维优先级排序,生成优先级降维矩阵节点数据;根据预设的降维节点数量选取优先级降维矩阵节点数据进行数据降维映射处理,生成降维数据矩阵。
8、本发明获取初始高维数据,为数据降维提供了数据基础。对高维数据进行数据预处理有助于确保分析的数据质量和准确性,处理异常值可以避免模型受到异常数据的干扰,而填补缺失值则有助于充分利用数据,并且将不同的数据划分至不同类型,使得后续数据降维结果更为精准。获取特征评分训练样本,通过选择适当的训练样本,可以确保特征评估模型具有代表性和准确性,以便模型能够全面评估各个特征数据的重要性,随机森林通过集成多个决策树的结果,每个决策树代表每个维度数据的特征数据评估,能够捕捉数据中的非线性关系和交互效应。生成的初始特征评估模型为后续特征选择提供了基础,有助于筛选出最相关的特征。利用特征评分训练样本对初始特征评估模型进行模型训练及优化,在训练过程中,模型可以通过与评估样本的真实特征重要性进行比较,不断调整和改进自身的预测能力,通过调整树的深度、叶节点数等参数来实现,从而生成更具性能的特征评估模型。将标准高维数据传输至优化特征评估模型进行数据子集的特征评估处理,通过特征评估,确定了哪些特征的重要性更高,从而减少了数据计算复杂性,特征评估有助于识别并削减那些对任务没有显著贡献的特征,减少了噪音的影响。基于数据子集特征评分数据进行特征提取,可以生成更具信息量的高维特征数据,减少了冗余信息,每个维度的数据量减少的同时提高数据的利用率,减小了数据的复杂性,使得后续降维分析更加高效。通过高维特征数据矩阵映射处理,便于高维数据进行数据降维,并且使得高维数据更容易理解和呈现,通过关联性赋权优化,可以识别和强调高维特征数据中的相关性,更好地捕捉数据内在结构,优化高维特征映射矩阵有助于避免信息丢失,确保降维过程中保留了重要的特征和关联性,为高维数据的降维过程提供了更好的基础。通过排序降维节点,可以确定哪些节点最重要,使降维过程更可控,允许用户选择特定数量的节点以达到降维的目标,优先级排序可以用于指导特征选择,帮助确定哪些特征在降维中应该优先考虑,从而提高了降维的效果。数据降维映射通过选取优先级降维节点,实际地降低了数据的维度,减少了存储和计算成本,同时提高了模型训练和推理的速度,通过优先级降维节点,确保了在降维过程中保留了最关键的信息,有助于维持数据集的可解释性和预测性能。因此,本发明的基于机器学习的高维数据降维方法对于高维数据的降维选取通过选取较为稳定以及相关性较小的维度数据,从而时降维数据更为精准,并且降维后的高位数据中每个维度数据以选取出具有代表性的特征数据,使得数据降维效果更加优异。
9、优选地,步骤s1包括以下步骤:
10、步骤s11:获取初始高维数据;
11、步骤s12:对初始高维数据进行数据清洗处理,生成清洗高维数据;
12、步骤s13:对清洗高维数据进行维度类型分析,生成维度类型数据;
13、步骤s14:根据维度类型数据进行数据格式类型设计,生成数据格式类型;
14、步骤s15:根据数据格式类型对清洗高维数据进行高维数据格式标准化处理,生成标准高维数据。
15、本发明通过获取初始高维数据,为后续分析和处理提供数据源,原始高维数据可能包含大量信息,有助于挖掘潜在的关联和模式。数据清洗有助于识别并纠正数据中的错误、缺失值或异常值,提高了数据的质量和可用性,提高了后续数据降维效果及稳定性。维度类型分析有助于理解每个特征的类型,例如数值型、分类型、时间序列等,为后续处理提供了重要的信息,制定适合不同类型特征的数据预处理策略,提高了数据处理的针对性。数据格式类型设计有助于确保数据在整个流程中保持一致的格式,减少了数据处理中的混淆和错误,增强了数据的解释性和可理解性。高维数据标准化确保了数据的一致性,使高维数据间每个维度数据根据维度类型进行有效划分,将不同特征的值尺度调整到相似的范围,提高了后续分析和建模的稳定性以及数据的可用性和可重复性。
16、优选地,步骤s2包括以下步骤:
17、步骤s21:获取特征评分训练样本;
18、步骤s22:利用随机森林算法建立数据子集的特征评估映射关系,以生成初始特征评估模型;
19、步骤s23:将特征评分训练样本进行数据划分处理,分别获得特征评分训练集、特征评分验证集以及特征评分测试集;
20、步骤s24:利用特征评分训练集对初始特征评估模型进行模型训练,生成特征评估训练模型;
21、步骤s25:将特征评分验证集传输至特征评估训练模型进行特征评分验证处理,生成特征评分验证数据;
22、步骤s26:利用模型优选超参数评估算法对特征评分验证数据进行模型优选超参数计算处理,生成模型优选超参数,并根据模型优选超参数对特征评估训练模型进行模型超参数优化调整,生成优化特征评估训练模型;
23、步骤s27:利用特征评分测试集对优化特征评估训练模型进行模型测试,以生成优化特征评估模型。
24、本发明获取特征评分训练样本为建立特征评估模型提供了必要的训练数据,确保了模型的可用性和可训练性。随机森林算法用于建立特征评估模型,该模型可评估不同维度的数据特征的重要性,有助于识别哪些特征对任务的贡献最大,随机森林算法建立初始模型提供了一个初始的特征评估工具,为后续特征评估模型的训练和优化提供了基线。数据划分为训练、验证和测试集有助于评估特征评估模型的性能,确保模型的泛化能力和可靠性,将数据划分成不同集合可以帮助监控模型的过拟合情况,有助于提高模型的预测精度。将数据划分成不同集合可以帮助监控模型的过拟合情况,有助于模型的泛化到新数据,模型训练过程中,特征评估模型能够学习每个维度数据中哪些特征对任务的贡献较大,这为后续优化提供了信息。特征评分验证数据用于评估模型在新数据上的性能,确保模型的泛化性和可靠性,根据特征评分验证数据中的预测数据与实际数据中的比对结果可用于优化模型的超参数,提高模型的性能。通过计算特征评分验证数据中的预测数据与实际数据中的比对结果以及对应的模型超参数进行最优超参数优化,有望提高特征评估模型的性能,使其更适应特定任务,模型优选超参数计算和调优,可以更好地配置模型,以达到更好的预测性能。使用特征评分测试集对优化模型进行测试,评估模型的性能和泛化能力,确保模型在实际应用中的可靠性,生成优化特征评估模型,可以用于后续每个维度的数据特征提取。
25、优选地,步骤s26中的模型优选超参数评估算法如下所示:
26、
27、式中,表示为模型优选超参数,θ表示为模型初始超参数向量,表示为模型超参数为θ的损失函数,λ1表示为模型l1正则化项调整值,r1(θ)表示为模型超参数为θ的l1正则化项,λ2表示为模型l2正则化项调整值,r2(θ)表示为模型超参数为θ的l2正则化项,t表示为模型验证的结束时间,g(x,θ)表示为模型输入数据x和模型初始超参数向量θ与模型预测输出的函数关系,x表示为模型输入数据,表示为模型关于模型输入数据x的偏导数,表示为模型关于初始超参数向量θ的偏导数,y表示为模型输入数据对应的实际输出数据,表示为模型输入数据对应的预测输出数据,t表示为模型验证的时间范围。
28、本发明利用一种模型优选超参数评估算法,该算法充分考虑了模型初始超参数向量θ、模型超参数为θ的损失函数模型l1正则化项调整值λ1、模型超参数为θ的l1正则化项r1(θ)、模型l2正则化项调整值λ2、模型超参数为θ的l2正则化项r2(θ)、模型验证的结束时间、t模型输入数据x和模型初始超参数向量θ与模型预测输出的函数关系g(x,θ)、模型输入数据x、模型关于模型输入数据x的偏导数模型关于初始超参数向量θ的偏导数模型输入数据对应的实际输出数据y、模型输入数据对应的预测输出数据以及函数之间的相互作用关系,以形成函数关系式:
29、即,该函数关系式通过模型验证时的预测输出与实际输出做比较,找出预测输出最接近实际输出的结果以及对应的模型参数,并通过最小化损失函数以及调节正则化项对模型超参数进行优化,使得函数关系式可以优化模型的超参数。通过引入λ1r1(θ)+λ2r1(θ)函数关系式能够能够防止模型过度拟合训练数据,从而提高模型的泛化能力,有助于避免模型在未见数据上产生过多的误差,λ1以及λ2允许调整模型的复杂性,通过适当选择这些超参数,可以平衡模型的简单性和拟合能力。算法的积分项考虑了模型在时间上的偏导数和实际预测误差,有助于模型根据数据的梯度和误差来调整超参数,以更好地拟合数据。通过该函数关系式多个验证集的数据比对,使得允许模型通过该函数关系式自动优化超参数,而不需要手动调整,提高了模型训练的效率和可扩展性。
30、优选地,步骤s3包括以下步骤:
31、步骤s31:将标准高维数据传输至优化特征评估模型进行数据子集的特征评估处理,生成数据子集特征评分数据;
32、步骤s32:利用预设的特征评分阈值对数据子集特征评分数据进行数值比对,将低于预设的特征评分阈值的数据子集特征评分数据对应的标准高维数据剔除,将不低于预设的特征评分阈值的数据子集特征评分数据对应的标准高维数据标记为高维特征数据。
33、本发明通过将数据传输至特征评估模型,可以评估维度数据的子集特征的重要性,有助于识别哪些子集对任务的贡献最大,基于特征评分数据,可以选择保留最重要的数据子集,减少了数据计算量,提高了后续数据降维的精准度。利用特征评分阈值进行数据筛选,可以剔除每个维度数据不重要的数据子集,减少了数据的复杂性,提高了后续分析的效率,将数据子集的特征评分数据保留为高维特征数据,从而实现数据集的精简和优化。
34、优选地,步骤s4包括以下步骤:
35、步骤s41:根据维度类型数据建立高维数据映射矩阵架构;
36、步骤s42:将高维特征数据传输至高维数据映射矩阵架构进行高维特征数据映射处理,生成高维特征映射矩阵;
37、步骤s43:对高维特征映射矩阵进行映射矩阵节点的关联性赋权优化处理,生成优化高维特征映射矩阵。
38、本发明建立高维数据映射矩阵架构可以指导如何将高维特征数据映射到相同维度的空间,有助于降维过程的规划和执行。将高维特征数据传输至高维数据映射矩阵架构进行高维特征数据映射处理,使得将数据投影到一个更结构化的空间,有助于更好地捕捉数据的内在结构,以及便于每个维度数据进行降维重要性计算。通过关联性赋权优化,可以强调高维特征映射矩阵的内部结构中的相关性,有助于更好地捕捉数据的重要特征和关联关系,从而提高数据降维分析的精准度及效率。
39、优选地,步骤s43包括以下步骤:
40、对维度类型数据进行维度类型的关联性分析,生成维度关联性数据;
41、根据维度关联性数据对高维特征映射矩阵进行映射矩阵节点的关联性赋权,生成优化高维特征映射矩阵。
42、本发明维度关联性分析有助于理解不同维度之间的相关性和依赖关系,有助于确定哪些维度在映射中应该更加强调,多维数据之间的关联性较为冗余,一个维度数据与大部分关联维度数据相似,则选取该维度数据则可以代表关联维度数据,因此计算维度关联性数据可以作为降维点评判标准之一。根据维度关联性数据对高维特征映射矩阵进行映射矩阵节点的关联性赋权,强调映射矩阵节点之间的关联性,有助于更好地捕捉数据中的重要特征和关系,提高了映射的质量,选取关联度较低的优化高维特征映射矩阵有利于数据维度相似性降低,提高数据降维的精度。
43、优选地,步骤s5包括以下步骤:
44、步骤s51:对优化高维特征映射矩阵进行映射矩阵节点的数据熵值计算,生成映射矩阵节点熵值;
45、步骤s52:利用数据降维优先级算法对维度关联性数据以及映射矩阵节点熵值进行节点降维优先级得分计算,生成节点降维优先级得分数据;
46、步骤s53:根据节点降维优先级得分数据对高维特征映射矩阵进行矩阵节点的降维优先级排序,生成优先级降维矩阵节点数据;
47、步骤s54:根据预设的降维节点数量选取降维优先级得分数据靠前的优先级降维矩阵节点数据进行数据降维映射处理,生成降维数据矩阵。
48、本发明通过计算节点的数据熵值,可以评估每个节点的数据复杂度,帮助确定哪些节点包含了更多的信息,映射矩阵节点熵值可以用作后续降维优先级的评判标准之一,数据熵反映了数据的稳定性,选取稳定性较高的数据维度,保障数据降维的有效性。利用数据降维优先级算法对维度关联性数据以及映射矩阵节点熵值进行节点降维优先级得分计算,数据降维优先级算法可以根据维度关联性数据以及映射矩阵节点熵值对每个维度进行降维优先级计算,以选取每个维度数据中数据稳定性较高,且维度数据中关联性较低的数据作为降维数据标准,更全面地考虑哪些维度数据对整个数据集的贡献最大,有助于更好地保留有用的信息。通过降维优先级排序,可以确定哪些节点的维度数据先进行降维处理,以实现数据的高效降维。根据预设的降维节点数量选取降维优先级得分数据靠前的优先级降维矩阵节点数据进行数据降维映射处理,降维节点数量可以控制降维的数量和程度,确保满足预设的降维需求,基于优先级降维矩阵节点数据进行降维映射处理,可以更高效地将高维数据转换为低维数据,以满足后期相关数学模型所需的分析和建模的需求。
49、优选地,步骤s52中的数据降维优先级算法如下所示:
50、
51、式中,qi表示为第i个节点的降维优先级得分数据,wi表示为第i个节点的节点初始权重信息,vi表示为第i个节点的维度关联数据的数据量,aik表示为第i个节点的第k个维度关联数据,ai表示为第i个节点的维度关联数据标准化项,ki表示为第i个节点内部结构的数据熵数据量,bij表示为第i个节点内部结构的第j个数据熵,bi表示为第i个节点的节点熵值标准化项。
52、本发明利用一种数据降维优先级算法,该算法充分考虑了第i个节点的节点初始权重信息wi、第i个节点的维度关联数据的数据量vi、第i个节点的第k个维度关联数据aik、第i个节点的维度关联数据标准化项ai、第i个节点内部结构的数据熵数据量ki、第i个节点内部结构的第j个数据熵bij、第i个节点的节点熵值标准化项bi以及函数之间的相互作用关系,以形成函数关系式:
53、即,通过该函数关系式对高维特征矩阵中的节点进行降维优先级计算,有限考虑数据稳定性较高,即数据熵较低的数据,以及数据关联程度低,即更具代表性的数据,作为优先降维的数据,且加入设定节点降维初始权重信息,该圈子信息为根据用户喜爱度进行设定,如无特殊节点,则相应将节点初始权重信息设置为统一值,使得降维后的数据稳定性更高,并且使得在数据维度减少情况保留降维前的特征。第i个节点的节点初始权重信息,用来赋予不同节点不同的重要性;第i个节点的维度关联数据的数据量,用来考虑每个节点所关联的维度数据的数量;第i个节点的第k个维度关联数据,用于计算节点的维度关联性;第i个节点的维度关联数据标准化项,用来标准化维度关联数据的数量;第i个节点内部结构的数据熵数据量,用于考虑节点内部结构的复杂性;第i个节点内部结构的第j个数据熵,用于评估节点内部结构的多样性和复杂性;第i个节点的节点熵值标准化项,用于标准化节点内部结构的数据熵。该函数关系式引入了标准化项,有助于将不同节点的数据量和熵值进行标准化,以便进行比较,标准化项可以消除不同节点之间的尺度差异,使评估更加公平和准确,并且该函数关系式有助于确定高维数据中每个节点的降维优先级,以更好地了解数据的结构和重要性,允许用户灵活地考虑不同节点的权重、维度关联数据、内部结构和标准化项,从而更准确地评估节点的重要性,为高维数据的降维操作提供有力支持,这在降维等任务中都有重要应用,可以提高数据分析和建模的效率和准确性。
54、本说明书中提供一种基于机器学习的高维数据降维系统,用于执行如上述所述的基于机器学习的高维数据降维方法,该基于机器学习的高维数据降维系统包括:
55、高维数据预处理模块,用于获取初始高维数据;对初始高维数据进行高维数据标准化处理,生成标准高维数据;
56、优化特征评估模型建立模块,用于获取特征评分训练样本;利用随机森林算法建立数据子集的特征评估映射关系,以生成初始特征评估模型;利用特征评分训练样本对初始特征评估模型进行模型训练及优化,以生成优化特征评估模型;
57、高维特征数据分析模块,用于将标准高维数据传输至优化特征评估模型进行数据子集的特征评估处理,生成数据子集特征评分数据;根据数据子集特征评分数据对标准高维数据进行特征数据提取,生成高维特征数据;
58、高维特征数据关联映射模块,用于对高维特征数据进行高维特征数据矩阵映射处理,生成高维特征映射矩阵;对高维特征映射矩阵进行映射矩阵节点的关联性赋权优化处理,生成优化高维特征映射矩阵;
59、高维数据降维模块,用于对优化高维特征映射矩阵进行降维矩阵节点的降维优先级排序,生成优先级降维矩阵节点数据;根据预设的降维节点数量选取优先级降维矩阵节点数据进行数据降维映射处理,生成降维数据矩阵。
60、本技术有益效果在于,本发明获取初始高维数据,确保数据源的准确性和完整性,通过数据清洗,去除数据中的噪音和异常值,以确保数据的质量。维度类型分析有助于了解不同维度之间的关系,生成维度类型数据,而数据格式类型的设计有助于确定数据的合适结构,以满足后续分析的需要,高维数据标准化处理确保不同维度的数据在相同的尺度上,从而提高了数据的一致性和可比性,有助于提高数据质量,为机器学习和数据分析提供了可靠的数据基础,从而促进更准确的决策和洞察力的提升,为后续的任务提供了更好的基础。通过获取特征评分训练样本,为模型提供了训练数据,以学习数据特征的重要性,并且根据随机森林算法建立了初步的特征评估模型,该模型能够捕获数据子集中不同特征之间的映射关系,为特征评估提供了基础,模型训练利用训练集,使初始特征评估模型逐渐优化并适应数据特点,从而生成了特征评估训练模型。特征评分验证用于验证模型性能,并生成特征评分验证数据,为后续的超参数优化提供了基础。在模型优选超参数评估中,采用了复杂的算法,计算模型的最优超参数,从而提高了模型的性能和准确性,通过超参数优化调整,生成了优化特征评估训练模型,这一模型在特征重要性评估方面更为精确,通过特征评分测试集,对优化特征评估训练模型进行测试,生成了优化特征评估模型,可以准确评估不同数据子集中特征的重要性,有助于提高数据分析和决策的质量和效率,有效地提升了数据特征的评估能力,为后续的数据降维和分析提供了可靠的基础,通过综合应用机器学习算法和数据划分策略,构建了一个强大的特征评估模型,该模型能够准确评估不同数据子集中的特征的重要性,以减少无用冗余的数据子集。将标准高维数据传输至优化特征评估模型,利用先前建立的特征评估模型来对每个数据子集中的特征进行评估,生成了数据子集特征评分数据,根据预设的特征评分阈值对数据子集特征评分数据进行数值比对,低于预设的特征评分阈值的数据子集特征评分数据对应的标准高维数据被剔除,而不低于预设的特征评分阈值的数据子集特征评分数据对应的标准高维数据被标记为高维特征数据,实现了数据子集的筛选和高维特征数据的提取,有助于减少冗余信息,提高数据处理效率以及数据降维时的降维结果精度,并确保所保留的高维特征数据是最具代表性和有价值的。将高维特征数据传输至高维数据映射矩阵架构,实施了高维特征数据的映射处理,将每个维度的数据映射至预建的矩阵节点,从而建立出结构化的高维特征映射矩阵,有助于将高维数据转化为更易于理解和分析的形式。对高维特征映射矩阵进行了映射矩阵节点的关联性赋权优化处理,有助于识别和加强不同节点之间的关联性,从而生成了一个更有结构的优化高维特征映射矩阵,有助于减少数据的维度,提高数据的可解释性,同时保留了数据之间的重要关联性,这对于进一步的数据分析和建模工作非常有益。计算高维特征映射矩阵中每个节点的数据熵值和节点降维优先级得分,数据熵值表示了每个节点的数据的稳定程度,节点降维优先级得分考虑了节点之间的关联性,这些计算帮助我们识别哪些节点包含更有用的信息,哪些节点可以降维或移除,从而减少数据的维度。利用节点降维优先级得分对高维特征映射矩阵进行了降维节点的排序,有助于确定哪些节点是最重要的,应该被保留,而哪些节点可以被降维,通过排序可以更有针对性地降低数据的维度,同时保持数据的结构完整性。根据预设的降维节点数量,选取了降维优先级得分高的节点数据,进行数据降维映射处理,生成了降维数据矩阵。这个降维后的数据集具有更低的维度,但仍然包含了原始数据中最重要的信息,从而提高了数据的可解释性,减少了冗余信息,同时加快了后续数据分析和建模的速度。
- 还没有人留言评论。精彩留言会获得点赞!