一种自适应调整的空间学习型索引建立方法
本发明涉及空间索引,尤其涉及一种自适应调整的空间学习型索引建立方法。
背景技术:
1、在大数据时代,特别是在处理城市中店铺空间位置信息等大规模数据集时,传统的地理信息系统gis领域索引面临着一系列挑战,如传统索引结构在数据量达到pb级甚至百pb级时,由于其o(n)的空间复杂度,无法完全缓存进内存,严重影响查询性能。此外,传统索引结构的多次间接搜索机制,使得查找性能在大规模数据集上进一步受到制约。更为关键的是,传统索引结构通常忽略了数据的分布特征,导致次优的空间代价和查询性能。
2、在地理信息系统gis中,这些问题可能导致查询速度缓慢以及查询结果不准确等问题,查询速度慢可能导致实时决策和应用的延迟,而不准确的查询结果可能影响地理信息系统gis的可靠性和实用性。因此大规模的空间位置信息数据集需要更高效的索引机制来应对查询请求,而传统索引的限制使得这些需求难以满足。
3、因此,针对这些问题,引入学习型索引成为一种创新的解决方案。2018年sigmod会议上首次提出了学习型索引(learned index)的概念,学习型索引利用机器学习模型替代传统的索引结构,显著降低空间复杂度,提高查询性能。目前,针对于学习型索引大多是针对一维数据的,对于空间中高维数据还存在局限性,对空间数据的实用性不高,同时对于索引的更新操作缺少优化策略。
技术实现思路
1、本发明提供一种自适应调整的空间学习型索引建立方法,以克服在地理信息系统gis中,对于大规模的数据集的处理,现有的学习型索引结构大多数适用于一维索引,对于空间中高维数据还存在局限性,对空间数据的实用性不高,存在查询速度缓慢以及查询结果不准确的技术问题。
2、为了实现上述目的,本发明的技术方案是:
3、一种自适应调整的空间学习型索引建立方法,具体步骤包括:
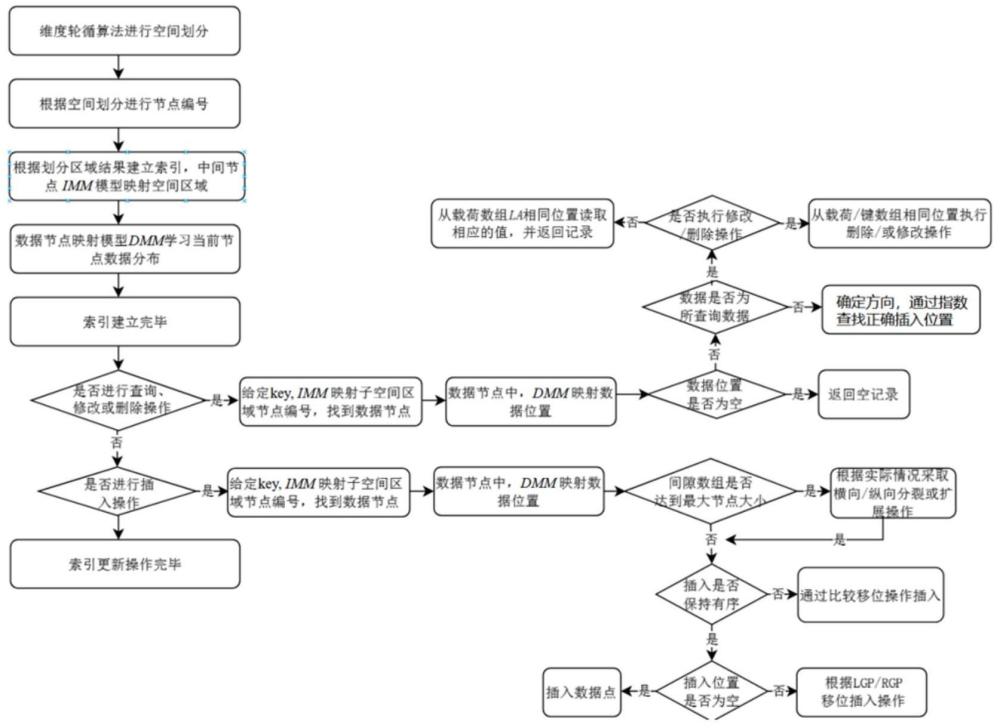
4、s1:获取与地理信息系统gis相关的数据集,并进行预处理,采用维度轮循算法dra对所述预处理后的数据集进行空间维度划分得到若干个子空间区域,并对每个所述子空间区域进行序列编号;
5、s2:基于若干个子空间区域及每个子空间区域的序列编号建立内部节点和数据节点的存储结构;
6、s3:通过内部节点将每个子空间区域的数据点批量加载到数据节点中,从而建立初始树状空间索引结构;
7、s4:基于所述初始树状空间索引结构进行更新操作,从而得到更新后的空间索引结构。
8、具体地,s1中,所述维度轮循算法dra对所述预处理后的数据集进行空间维度划分得到若干个子空间区域,并对每个所述子空间区域进行序列编号的过程为:
9、确定预处理后的数据集的维度,基于维度轮循算法dra对数据集进行划分,第一次划分后得到子空间区域a1,a2,…,ai,i=(1,2,…,2m),这2m个子空间区域对应树状空间索引结构的根节点即第一层内部节点,其中第一层内部节点的指针数组中包括2m个指针;
10、依次判断a1,a2,…,ai中的数据点的数目是否超出设定的数据节点大小从而判断是否进行循环划分步骤,若ai超出,则将ai基于维度轮循算法dra进行再次划分,否则,将ai中的数据点分配给一个数据节点,并使ai中的一个指针指向该数据节点;
11、所述循环划分步骤是指每一次划分后,都判断划分后得到的子空间区域中的数据点的数目是否超出设定的数据节点大小,并将每次划分后所有超出的子空间区域设置为一层内部节点,进行下一次划分;同时将每个未超出的子空间区域中的数据点分配给一个对应的数据节点,并对应使上一层指针指向该数据节点,直到划分后得到的子空间区域中的数据点的数目均小于设定的数据节点大小,则停止划分,此时由预处理后的数据集开始进行划分后得到了若干个子空间区域,基于每个子空间区域的坐标范围对其进行序列编号;
12、所述维度轮循算法dra包括,基于预处理后的数据集的维度d,从中选取m个维度,其中m=2,3,4,5,且m<d,共有种维度组合方式,依次轮循采用种维度组合方式中的一种,根据选取的每一个维度的范围中点对预处理后的数据集以及划分后超出的子空间区域进行划分。
13、具体地,s2中,所述内部节点的存储结构为:in=
14、(pa,imm,maxkey,minkey,insize,innum),其中in表示内部节点;pa表示指针数组,用于存储指向下一内部节点的指针;imm表示节点映射模型;maxkey表示当前内部节点的最大数据键的键值;minkey表示当前内部节点的最小数据键的键值;insize表示当前内部节点的最大节点大小;innum表示当前内部节点的序列编号;
15、所述数据节点的存储结构:dn=(ka,la,dmm,lgp,rgp,dsize),其中dn表示数据节点;ka表示键数组,用于存储数据键ki;la表示载荷数组,用于存储与数据键ki一一对应的有效载荷li,且键数组ka与载荷数组la均为间隙数组;dmm表示数据映射模型,用于学习当前数据节点中的数据点的分布以及映射出数据键ki的插入位置;lgp表示数据节点中最左侧间隙的位置;rgp表示数据节点中最右侧间隙的位置;dsize表示当前数据节点的最大数据节点大小。
16、具体地,s3中,通过内部节点将每个子空间区域的数据点批量加载到数据节点中的过程为:
17、s31:根据数据点的坐标,从第一层内部节点开始,通过第一层内部节点中的节点映射模型imm计算数据点在第一层内部节点中的指针数组pa中的位置,然后沿着指针指向第二层内部节点,重复该过程,从而在每一层内部节点中通过节点映射模型imm依次映射数据点在指针数组pa中的位置,直到找到存储该数据点的数据节点;
18、s32:在对应数据节点中,通过数据映射模型dmm映射数据点的数据键在键数组ka中的对应位置,如果对应位置为空,则将数据点直接插入,否则,使用指数查找找到插入后能够保证键数组ka有序性的位置,在进行插入。
19、具体地,s4中,基于所述初始空间索引结构进行更新操作,所述更新操作包括插入操作,所述插入操作包括:
20、查找待插入数据点所要插入的数据节点;
21、根据所要插入的数据节点为未满数据节点或已满数据节点执行相应的插入操作:
22、当所要插入的数据节点为未满数据节点时:
23、采用当前数据节点的数据映射模型dmm预测插入位置,如果插入位置是一个间隙,那么直接执行插入操作,否则,分别判断插入位置与lgp以及rgp之间的距离远近,选择距离近的方向,即靠近lgp的方向或靠近rgp的方向作为插入位置的数据键的移动方向,并设定一个临时变量,先使用临时变量存储插入位置的数据键,从而将待插入数据键进行插入,之后向距离近的方向移动一个元素位置,再使用临时变量存储该位置数据键,然后将上一次临时变量存储的数据键插入,重复该过程,直至遇到间隙,将临时变量存储的最后的数据键插入间隙,此时插入过程结束;
24、当待插入数据点所插入的数据节点为已满数据节点时,采用节点扩展或节点分裂机制进行插入:
25、若数据节点没有达到数据节点的最大空间大小时,则执行节点扩展操作:
26、首先,分配一个新的键数组,其元素容量为capacity=n/lbound,n为数据键的数目,lbound为键数组ka的密度下限,此时,根据新的键数组的容量对当前数据节点的数据映射模型dmm的参数进行按比例减小或者增大调整或重新训练,然后使用参数调整后或重新训练的数据映射模型dmm基于新的键数组预测插入位置,从而对待插入数据点进行插入;
27、若数据节点达到数据节点的最大空间大小,则执行节点分裂操作:
28、通过节点分裂操作,将该达到最大空间大小的数据节点平均分裂成两个新的数据节点,并将数据键平均分配给两个新的数据节点进行存储,然后根据新数据节点中的数据映射模型dmm在各自的键数组中进行映射插入。
29、具体地,所述节点分裂包括横向分裂和纵向分裂:
30、横向分裂包括两种情形:
31、1)若达到最大空间大小的数据节点的上一层的内部节点没有达到预先设定的最大节点大小,将达到最大空间大小的数据节点平均分裂成两个新的数据节点,如果上一层的内部节点存在冗余指针,则将冗余指针平均分配并指向两个新的数据节点;如果上一层的内部节点不存在冗余指针,则先将当前指针数组的大小加倍,然后为每个指针创建用于指向新的数据节点的冗余副本指针,并将冗余副本指针指向新的数据节点;
32、2)若达到最大空间大小的数据节点的上一层的内部节点即父内部节点达到预先设定的最大节点大小,则对上一层的内部节点进行横向分裂后,再对达到最大空间大小的数据节点进行横向分裂;
33、除横向分裂所述的两种情形外,其他情形采用纵向分裂进行处理:
34、首先将达到最大空间大小的数据节点转换成具有两个新的数据节点的内部节点,同时将数据键平均分配给两个新的数据节点。
35、具体地,s4中,所述插入操作包括越界插入:
36、当在当前空间索引中的最左侧或最右侧数据节点中进行越界插入时,对根节点即第一层内部节点进行节点扩展操作,包括对于指向现有数据节点的指针不做修改,同时在扩展后的第一层内部节点的指针数组中,为每个空位置创建一个新的指针,并指向新创建的数据节点,将越界插入的数据键插入新创建的数据节点中;若不能进行节点扩展操作,则进行越界插入纵向分裂操作,包括创建一个新的根节点即新的第一层数据节点,将新的根节点指针数组中第一个指针指向原有的根节点,并且为指针数组中其余每个空位置创建一个新的指针,并指向新创建的数据节点,此时,将越界插入的数据键插入新创建的数据节点中。
37、具体地,基于所述初始空间索引结构进行更新操作,所述更新操作包括数据键删除和数据键修改操作:
38、数据键删除:首先查找待删除数据键的位置,如果未找到,则返回为空,无需删除,若找到,则删除数据键以及对应的有效载荷;
39、数据键修改:首先查找待修改数据键的位置,如果未找到,则返回空,无需修改,若找到,则修改数据键对应有效负载的值,即在载荷数组相同位置上对数值进行修改。
40、有益效果:本发明所提出的自适应调整的空间学习型索引建立方法,采用维度轮循算法对空间区域划分得到若干个子区域空间,并对子空间区域进行序列编号,通过节点映射模型imm能够准确计算出子空间区域的序列编号,提高了内部节点的查询效率,且找到的子空间区域为准确的区域,无需验证。通过节点映射模型imm能够准确计算出子空间区域的序列编号,同时在数据节点通过数据映射模型dmm学习当前数据节点的数据分布,提高了查询效率,同时结合间隙数组对数据节点进行空间布局,使得插入操作的动态更新速度也变得更快,从而实现了索引的动态更新,且无需验证,综合来说,本发明所创建的索引结构可以实现高性能的写入操作以及查询操作。在实际应用中,采用本方法建立的学习型索引,能够使地理信息系统gis显著提高查询速度,减少查询不准确性问题,并更好地适应大规模数据的挑战。
- 还没有人留言评论。精彩留言会获得点赞!