视觉问答模型的训练方法、训练装置和视觉问答系统与流程
本发明涉及视觉问答,具体而言,涉及一种视觉问答模型的训练方法、训练装置、计算机可读存储介质和视觉问答系统。
背景技术:
1、视觉问答任务是指给定一张图片以及一个有关于该图片的问题,我们需要根据图片给出问题的答案。问题的种类是多样的,可以是多选题、也可以是问答题。
2、现有的技术多是用两个网络结构分别提取图像和文本的信息,然后再将两者的信息以某种方法做交互,从而得出答案。但是分别提取特征的方法难以将两种信息有效的融合,这导致的结果就是模型在回答问题的时候较少考虑图像信息。例如,模型的鲁棒性很差。对于某一个问题,模型总会选择训练集中出现次数多的答案来进行回答,从而在现实生活中很容易出错。这就表明,模型对训练集中的文本过拟合了,而很少关注到对应的图像。
3、clip模型是openai在2021年初发布的用于匹配图像和文本的预训练神经网络,在多模态研究领域的很多任务上取得了sota的结果。它采用对比学习的方式,拉近相近的图片和文本之间的距离,使用4亿的图片文本对进行训练,实现了图片和文本的对齐功能。但是clip模型不能直接用于视觉问答任务。它只是一个做图片文本对齐任务的预训练模型,没有做视觉问答任务的能力。
技术实现思路
1、本技术的主要目的在于提供一种视觉问答模型的训练方法、训练装置、计算机可读存储介质和视觉问答系统,以至少解决现有技术中视觉问答模型倾向于文本的拟合,对图像的拟合较低导致模型鲁本性较差的问题。
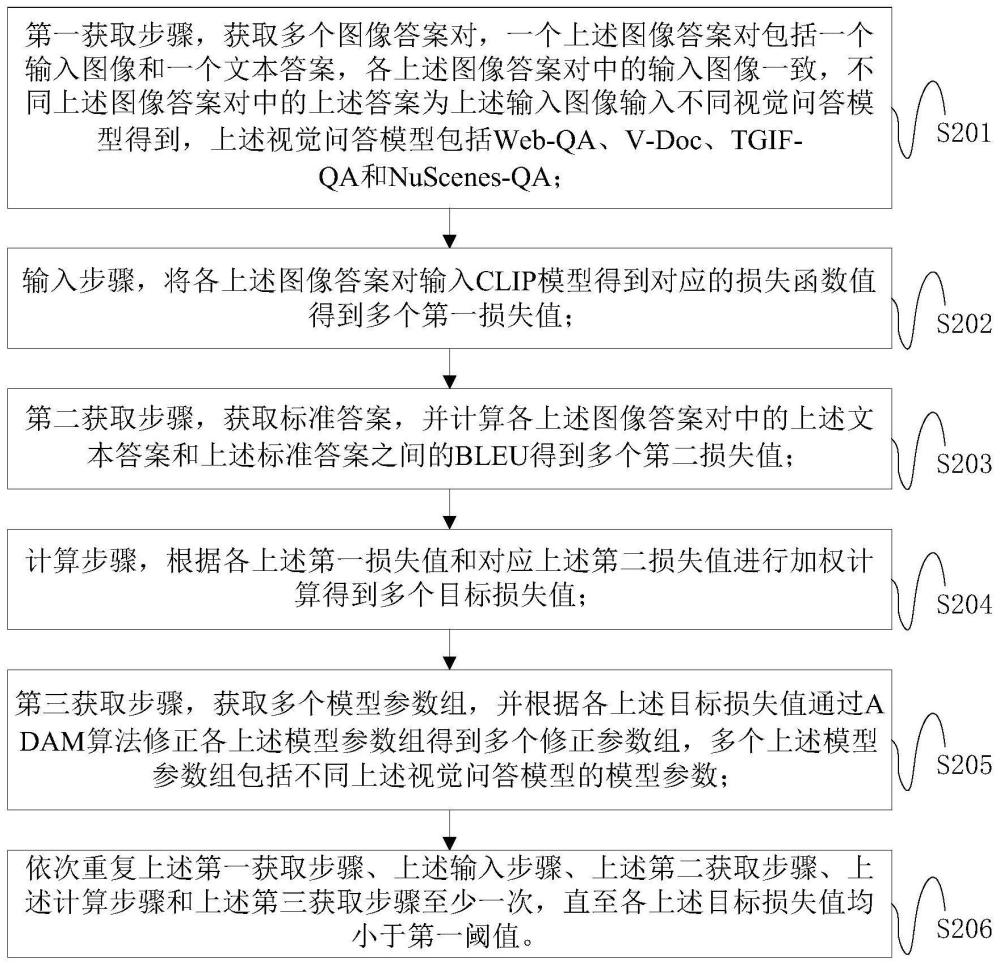
2、为了实现上述目的,根据本技术的一个方面,提供了一种视觉问答模型的训练方法,包括:第一获取步骤,获取多个图像答案对,一个所述图像答案对包括一个输入图像和一个文本答案,各所述图像答案对中的输入图像一致,不同所述图像答案对中的所述答案为所述输入图像输入不同视觉问答模型得到,所述视觉问答模型包括web-qa、v-doc、tgif-qa和nuscenes-qa;输入步骤,将各所述图像答案对输入clip模型得到对应的损失函数值得到多个第一损失值;第二获取步骤,获取标准答案,并计算各所述图像答案对中的所述文本答案和所述标准答案之间的bleu得到多个第二损失值;计算步骤,根据各所述第一损失值和对应所述第二损失值进行加权计算得到多个目标损失值;第三获取步骤,获取多个模型参数组,并根据各所述目标损失值通过adam算法修正各所述模型参数组得到多个修正参数组,多个所述模型参数组包括不同所述视觉问答模型的模型参数;依次重复所述第一获取步骤、所述输入步骤、所述第二获取步骤、所述计算步骤和所述第三获取步骤至少一次,直至各所述目标损失值均小于第一阈值。
3、可选地,在依次重复所述第一获取步骤、所述输入步骤、所述第二获取步骤、所述计算步骤和所述第三获取步骤至少一次,直至各所述目标损失值均小于第一阈值之后,所述方法还包括:获取第一目标图像,所述第一目标图像为待进行问答的所述输入图像;将所述第一目标图像分别输入各所述视觉问答模型得到对应的所述文本答案;根据各所述文本答案与所述第一目标图像构建所述图像答案对得到多个目标图像答案对;将各所述目标图像答案对输入所述clip模型,得到多个第一相似度,所述第一相似度为各所述目标图像答案对中所述第一目标图像与所述文本答案的余弦相似度;将对应所述第一相似度最大的所述目标图像答案对中的所述文本答案确定为目标答案并输出。
4、可选地,将各所述图像答案对输入clip模型得到对应的损失函数值得到多个第一损失值,包括:将所述图像答案对中的所述输入图像输入第一编码器得到第一向量,所述第一编码器用于对所述输入图像进行编码转换为向量表示;将所述图像答案对中的所述文本答案输入第二编码器得到第二向量,所述第二编码器用于对所述文本答案进行编码转换为向量表示;根据所述第一向量和所述第二向量计算余弦相似度得到目标相似度,并将所述目标相似度代入第一预设公式得到所述第一损失值。
5、可选地,将所述图像答案对中的所述输入图像输入第一编码器得到第一向量,包括:将所述图像答案对中的所述输入图像裁剪为预设尺寸得到第一图像;将所述第一图像中的各像素块的像素值进行归一化得到第二图像;对所述第二图像进行数据增强得到第三图像,所述数据增强至少包括随机裁剪、翻转和旋转;对所述第三图像进行编码,将所述第三图像转换为向量形式得到所述第一向量。
6、可选地,计算各所述图像答案对中的所述文本答案和所述标准答案之间的bleu得到多个第二损失值,包括:对所述文本答案和所述标准答案进行分词并进行组合得到多个子文本,每个所述子文本中的所述分词数量为预设数量;根据各所述子文本与所述文本答案进行匹配确定所述文本答案中各所述子文本的出现次数得到多个第一统计值,根据各所述子文本与所述标准答案进行匹配确定所述标准答案中各所述子文本出现次数得到第二统计值;根据所述文本答案确定第三统计值,计算各所述第一统计值和所述第三统计值的比值得到多个第四统计值,所述第三统计值为所述文本答案中包含的所述子文本的数量;将各所述第四统计值代入第二预设公式得到所述文本答案对应的备选bleu;根据所述标准答案确定第五统计值,所述第五统计值为所述标准答案中包含的所述子文本的数量;计算所述第三统计值和所述第五统计值的差值得到第六统计值,计算所述备选bleu的调和平均数得到第七统计值,计算所述第六统计值和所述第七统计值的乘积得到所述第二损失值。
7、可选地,根据各所述目标损失值通过adam算法修正各所述模型参数组,包括:根据所述目标损失值通过反向传播算法计算所述目标损失值对对应的所述视觉问答模型的所述模型参数组的梯度得到目标梯度;根据所述目标梯度通过adam算法更新所述模型参数组得到对应的所述修正参数组。
8、可选地,根据各所述第一损失值和对应所述第二损失值进行加权计算得到多个目标损失值,包括:获取第一权重和第二权重,所述第一权重为所述第一损失值对应的权重,所述第二权重为所述第二损失值对应的权重;计算所述第一损失值与所述第一权重的乘积和所述第二损失值和所述第二权重的乘积的和得到所述目标损失值。
9、根据本技术的另一方面,提供了一种视觉问答模型的训练装置,所述装置包括:第一获取单元,用于执行第一获取步骤,获取多个图像答案对,一个所述图像答案对包括一个输入图像和一个文本答案,各所述图像答案对中的输入图像一致,不同所述图像答案对中的所述答案为所述输入图像输入不同视觉问答模型得到,所述视觉问答模型包括web-qa、v-doc、tgif-qa和nuscenes-qa;第一输入单元,用于输入步骤,将各所述图像答案对输入clip模型得到对应的损失函数值得到多个第一损失值;第二获取单元,用于执行第二获取步骤,获取标准答案,并计算各所述图像答案对中的所述文本答案和所述标准答案之间的bleu得到多个第二损失值;计算单元,用于计算步骤,根据各所述第一损失值和对应所述第二损失值进行加权计算得到多个目标损失值;第三获取单元,用于执行第三获取步骤,获取多个模型参数组,并根据各所述目标损失值通过adam算法修正各所述模型参数组得到多个修正参数组,多个所述模型参数组包括不同所述视觉问答模型的模型参数;重复单元,用于依次重复所述第一获取步骤、输入步骤、第二获取步骤、计算步骤和第三获取步骤至少一次,直至各所述目标损失值均小于第一阈值。
10、根据本技术的再一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的程序,其中,在所述程序运行时控制所述计算机可读存储介质所在设备执行任意一种所述的方法。
11、根据本技术的又一方面,提供了一种视觉问答系统,包括:一个或多个处理器,存储器,以及一个或多个程序,其中,所述一个或多个程序被存储在所述存储器中,并且被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行任意一种所述的方法。
12、应用本技术的技术方案,在上述视觉问答模型的训练方法中,首先,执行第一获取步骤,获取多个图像答案对,一个上述图像答案对包括一个输入图像和一个文本答案,各上述图像答案对中的输入图像一致,不同上述图像答案对中的上述答案为上述输入图像输入不同视觉问答模型得到,上述视觉问答模型包括web-qa、v-doc、tgif-qa和nuscenes-qa;然后,执行输入步骤,将各上述图像答案对输入clip模型得到对应的损失函数值得到多个第一损失值;之后,执行第二获取步骤,获取标准答案,并计算各上述图像答案对中的上述文本答案和上述标准答案之间的bleu得到多个第二损失值;之后,执行计算步骤,根据各上述第一损失值和对应上述第二损失值进行加权计算得到多个目标损失值;之后,执行第三获取步骤,获取多个模型参数组,并根据各上述目标损失值通过adam算法修正各上述模型参数组得到多个修正参数组,多个上述模型参数组包括不同上述视觉问答模型的模型参数;最后,依次重复上述第一获取步骤、上述输入步骤、上述第二获取步骤、上述计算步骤和上述第三获取步骤至少一次,直至各上述目标损失值均小于第一阈值。本技术基于多个现有问答模型,分别根据输入图像给出视觉问答的答案,通过clip模型进行文本和图像的对齐,进而根据文本和图像两方面的损失值计算总的损失值,根据损失值更新各模型的模型参数,以提高各模型的精度,相比于现有技术中设置两个网络结构,分别用于处理图像和文本,本技术基于clip模型进行文本对齐,对文本和图像信息进行融合,解决了现有技术中视觉问答模型倾向于文本的拟合,对图像的拟合较低导致模型鲁本性较差的问题。
- 还没有人留言评论。精彩留言会获得点赞!