一种基于扩散模型数据增强的情感识别方法和系统
本发明属于情感识别领域,尤其涉及一种基于扩散模型数据增强的情感识别方法和系统。
背景技术:
1、在日常生活中,人类的情感可以包含于自己的言行中,基于音视频的情感识别技术可以通过分析输入的音视频信息进行情感识别。情感识别是自然语言处理(naturallanguage processing, nlp)和计算机视觉(computer vision, cv)等领域中的重要任务之一。传统的情感识别方法通常需要大量标记好的数据进行训练,缺乏数据量支撑会导致训练效果不佳,影响模型的情感识别性能,但标注数据的获取成本较高且耗时。关于音频数据增强方面,现有技术通常利用音频增强的方法对音频进行噪声添加、混响处理等操作,模拟真实世界中不同的环境和声音情况;此外还有数据扰动和音频剪切等方法来扩充数据集。关于视频数据增强方面,现有技术采用视频剪辑,对视频进行随机剪辑,截取其中的一部分或多个片段,以引入不同的情感表达、语境或背景;还有对视频进行帧采样,将采样出的图像数据进行处理以生成新的图像样本。
2、现有技术缺点:
3、现有技术存在数据量不足,模型所提取的特征对于情感表示不充分,生成的扩充数据质量不高,提取出的情感特征表征能力差等问题。影响最终实际应用的情感识别结果。
技术实现思路
1、为解决上述技术问题,本发明提出一种基于扩散模型数据增强的情感识别方法的技术方案,以解决上述技术问题。
2、本发明第一方面公开了一种基于扩散模型数据增强的情感识别方法,所述方法包括:
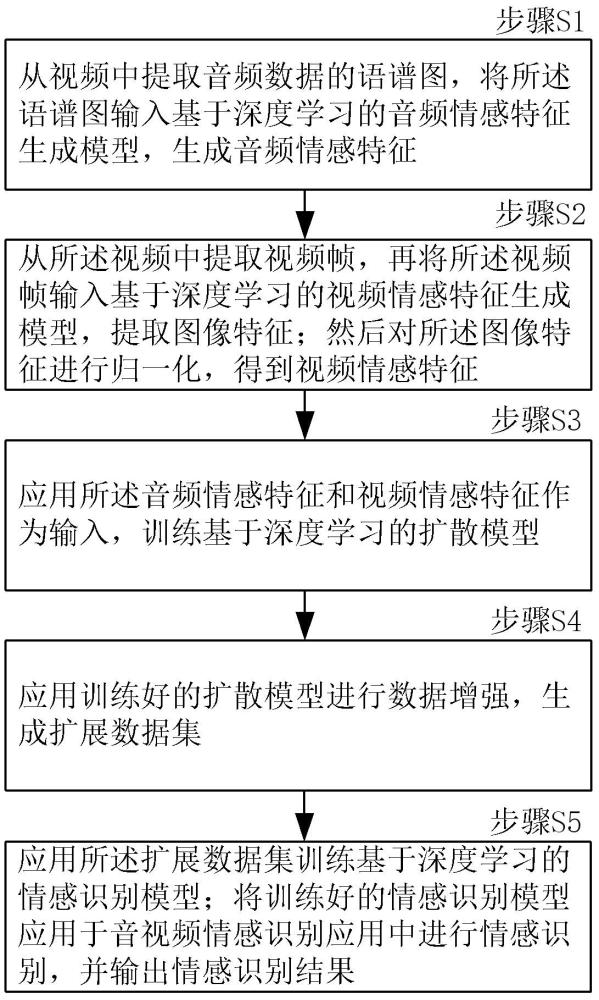
3、步骤s1、从视频中提取音频数据的语谱图,将所述语谱图输入基于深度学习的音频情感特征生成模型,生成音频情感特征;
4、步骤s2、从所述视频中提取视频帧,再将所述视频帧输入基于深度学习的视频情感特征生成模型,提取图像特征;然后对所述图像特征进行归一化,得到视频情感特征;
5、步骤s3、应用所述音频情感特征和视频情感特征作为输入,训练基于深度学习的扩散模型;
6、步骤s4、应用训练好的扩散模型进行数据增强,生成扩展数据集;
7、步骤s5、应用所述扩展数据集训练基于深度学习的情感识别模型;将训练好的情感识别模型应用于音视频情感识别应用中进行情感识别,并输出情感识别结果。
8、根据本发明第一方面的方法,在所述步骤s1中,所述基于深度学习的音频情感特征生成模型为对抗自编码网络。
9、根据本发明第一方面的方法,在所述步骤s2中,所述基于深度学习的视频情感特征生成模型为预训练的卷积神经网络。
10、根据本发明第一方面的方法,在所述步骤s3中,所述应用所述音频情感特征和视频情感特征作为输入,训练基于深度学习的扩散模型的方法包括:
11、应用所述扩散模型的输入层将所述音频情感特征和视频情感特征进行特征融合,得到音视频特征;应用所述音视频特征训练基于深度学习的扩散模型。
12、根据本发明第一方面的方法,在所述步骤s3中,在扩散模型训练过程中,使用情感标签作为监督信号,引导扩散模型学习音视频特征与情感之间的关系。
13、根据本发明第一方面的方法,在所述步骤s3中,训练基于深度学习的扩散模型的损失函数为:
14、,
15、其中, n表示样本的数量, yi表示真实标签,0或1,而表示生成音视频特征的预测标签;对于真实样本, yi等于1,而对于生成音视频特征 yi等于0。
16、根据本发明第一方面的方法,在所述步骤s4中,所述应用训练好的扩散模型进行数据增强,生成扩展数据集的方法包括:
17、应用训练好的扩散模型输出生成音视频特征数据,通过在扩散模型生成过程中引入随机噪声,并通过逐步扩散过程将噪声逐渐转化为具有目标情感的音视频特征数据,得到增强数据;再将所述增强数据与真实特征数据合并,得到扩展数据集。
18、本发明第二方面公开了一种基于扩散模型数据增强的情感识别系统,所述系统包括:
19、第一处理模块,被配置为,从视频中提取音频数据的语谱图,将所述语谱图输入基于深度学习的音频情感特征生成模型,生成音频情感特征;
20、第二处理模块,被配置为,从所述视频中提取视频帧,在将所述视频帧输入基于深度学习的视频情感特征生成模型,提取图像特征;然后对所述图像特征进行归一化,得到视频情感特征;
21、第三处理模块,被配置为,应用所述音频情感特征和视频情感特征作为输入,训练基于深度学习的扩散模型;
22、第四处理模块,被配置为,应用训练好的扩散模型进行数据增强,生成扩展数据集;
23、第五处理模块,被配置为,应用所述扩展数据集训练基于深度学习的情感识别模型;将训练好的情感识别模型应用于音视频情感识别应用中进行情感识别,并输出情感识别结果。
24、根据本发明第二方面的系统,所述第一处理模块,被配置为,所述基于深度学习的音频情感特征生成模型为对抗自编码网络。
25、根据本发明第二方面的系统,所述第二处理模块,被配置为,所述基于深度学习的视频情感特征生成模型为预训练的卷积神经网络。
26、根据本发明第二方面的系统,所述第三处理模块,被配置为,所述应用所述音频情感特征和视频情感特征作为输入,训练基于深度学习的扩散模型包括:
27、应用所述扩散模型的输入层将所述音频情感特征和视频情感特征进行特征融合,得到音视频特征;应用所述音视频特征训练基于深度学习的扩散模型。
28、根据本发明第二方面的系统,所述第三处理模块,被配置为,在扩散模型训练过程中,使用情感标签作为监督信号,引导扩散模型学习音视频特征与情感之间的关系。
29、根据本发明第二方面的系统,所述第三处理模块,被配置为,训练基于深度学习的扩散模型的损失函数为:
30、,
31、其中, n表示样本的数量, yi表示真实标签,0或1,而表示生成音视频特征的预测标签;对于真实样本, yi等于1,而对于生成音视频特征 yi等于0。
32、根据本发明第二方面的系统,所述第四处理模块,被配置为,所述应用训练好的扩散模型进行数据增强,生成扩展数据集包括:
33、应用训练好的扩散模型输出生成音视频特征数据,通过在扩散模型生成过程中引入随机噪声,并通过逐步扩散过程将噪声逐渐转化为具有目标情感的音视频特征数据,得到增强数据;再将所述增强数据与真实特征数据合并,得到扩展数据集。
34、本发明第三方面公开了一种电子设备。电子设备包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时,实现本公开第一方面中任一项的一种基于扩散模型数据增强的情感识别方法中的步骤。
35、本发明第四方面公开了一种计算机可读存储介质。计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时,实现本公开第一方面中任一项的一种基于扩散模型数据增强的情感识别方法中的步骤。
36、综上,本发明提出的方案能够对现有数据进行特征提取,利用扩散模型生成大量相似的特征信息进行训练,通过充分学习训练数据中包含的各种情感特征,提升模型的泛化性能,从而提高实际情感识别的效果。
- 还没有人留言评论。精彩留言会获得点赞!