多层次特征集成和脑电与人脸特征融合的情感识别方法
本发明属于情感识别领域,具体涉及多层次特征集成和脑电与人脸特征融合的情感识别方法。
背景技术:
1、近年来,在双模态情感识别领域中,以脑电(eeg)为代表的生理信号与以人脸图像为代表的物理信号的结合成为了研究热点,可以获得更为丰富、完备的特征信息,从而有效提高情感识别性能,并在安全驾驶、远程教育、医疗健康等多个领域得到了广泛应用。
2、在eeg信号和人脸图像的情感识别领域中,由于eeg信号具有非平稳性、低信噪比的特点,eeg特征学习相较于人脸图像特征学习更具挑战性,如何提取更具泛化性的eeg特征用于情感识别成为了该领域的研究重点。现有的eeg特征提取主要包括手工特征提取、脑电地形图、深度学习三种方法。然而,手工特征提取方法忽略了eeg信号通道间的相关性,使得模型性能受限;脑电地形图方法性能依赖于手工特征的质量;现有的深度学习方法通过简单的卷积操作从eeg信号中学习特征,忽视了eeg信号本质上是一种复杂的时间序列数据,导致模型难以充分建模eeg信号内部复杂的时空关系。其次,如何充分利用多模态信息捕捉情感语义的一致性与互补性同样是研究者的研究重点之一。其中,一致性是指各模态特征之间的共享语义信息,互补性是指各模态特征内部的特有语义信息。为此,特征级融合、决策级融合是最为常见的策略。然而,特征级融合方法无法克服模态间的语义鸿沟问题,难以充分挖掘模态间的语义一致性;决策级融合方法仅侧重于提取各模态的特有语义信息,而无法提取模态间的共享语义信息,导致模型性能受限。
3、由上可知,在该领域中,主要存在两个挑战:(1)对于eeg信号这种非线性多通道时间序列,如何从原始eeg信号中学习具有更显著的情感语义的特征用于情感识别;(2)如何充分利用多模态信息捕捉情感语义的一致性与互补性,从而提升情感识别模型的性能。这两个挑战直接影响到目前的情感识别模型的性能,使得模型在基于脑电和人脸图像的双模态情感识别任务上难以具备良好的性能表现,在实际应用中受到限制。比如,在临床心理诊断中,由于基于eeg信号与人脸图像的双模态情感识别模型的准确率有限,导致目前基于深度学习模型的实际应用受限。
4、为此,本技术提出了一种多层次特征集成和脑电与人脸特征融合的情感识别方法,即多层次时空特征自适应集成与特有-共享特征融合(mstfai-scff),用于提高eeg信号与人脸图像的双模态情感识别模型的性能。
技术实现思路
1、本发明的目的是提供多层次特征集成和脑电与人脸特征融合的情感识别方法,能有效地提高eeg信号与人脸图像双模态情感识别的准确率。
2、本发明所采用的技术方案是,多层次特征集成和脑电与人脸特征融合的情感识别方法,具体按照以下步骤实施:
3、步骤1、获取样本集,并将样本集中的每个样本划分为多个1s长的数据片段,得到的数据片段划分为5部分,取1部分为测试集,其余为训练集;
4、步骤2、搭建mstfai-scff模型;
5、步骤3、用训练集中数据片段训练mstfai-scff模型,得到训练好的模型;
6、步骤4、用测试集中的数据片段对训练好的模型测试,得到情感识别模型;
7、步骤5、用情感识别模型进行eeg信号以及图像样本情感识别。
8、本发明的特点还在于,
9、样本集通过公开的deap数据集和mahnob-hci数据集获取,样本集中的每个样本包含人脸图像视频及其对应的eeg信号及情感类别标签。
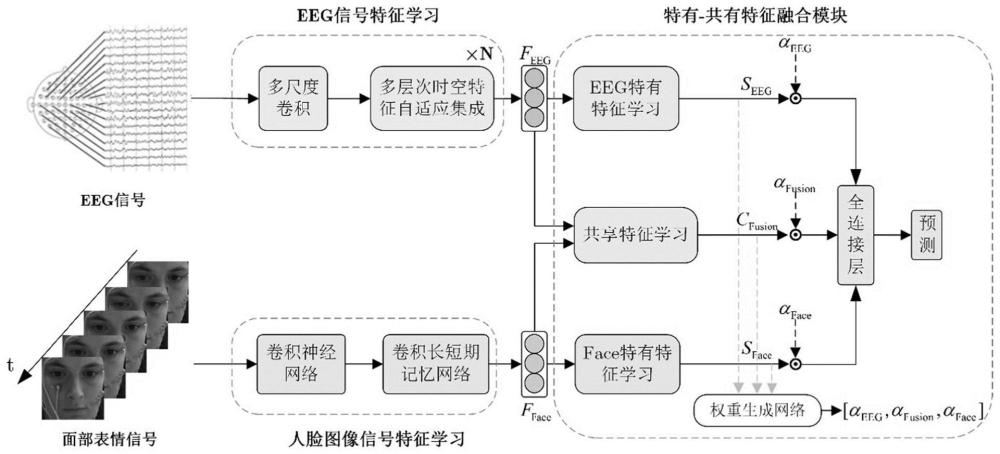
10、mstfai-scff模型包括eeg信号特征学习、人脸图像特征学习、特有-共享特征融合模块三部分,该mstfai-scff模型通过将eeg信号特征学习的输出特征、人脸图像特征学习的输出特征通过特有-共享特征融合模块进行融合,输出预测情感类别,实现情感识别。
11、eeg信号特征学习过程具体如下:
12、步骤4.1、搭建多尺度卷积模块:将样本集的eeg信号样本作为多尺度卷积的输入,通过将卷积核长度设定为与eeg采样率feeg相关的比例大小α以实现对eeg信号时间、频率特征的捕捉,得到eeg特征输出peeg;
13、多尺度时间卷积模块公式表示如下:
14、ei=conv1d(x,αifeeg) (1)
15、peeg=msconv(x)=concat(e1,e2,e3) (2)
16、其中,x表示输入的eeg信号,αifeeg表示一维卷积核长度,feeg为eeg采样率,且α∈[0.5,0.25,0.125],而ei表示一维卷积输出,concat(i)代表拼接操作,msconv(i)代表多尺度卷积模块,peeg为多尺度卷积模块输出;
17、步骤4.2、搭建多层次时空特征自适应集成模块,该模块由时空特征联合学习模块和多层次特征自适应集成模块组成;peeg作为第一层多层次时空特征自适应集成模块的输入特征,令peeg=p0,则第n层多层次时空特征自适应集成模块的输入特征为pn-1,计算第n层多层次时空特征自适应集成模块的输出特征pn;
18、步骤4.3、将第n层的多层次时空特征自适应集成模块的输出特征pn进行展平操作,结合全连接层进行维度压缩,生成最终的eeg特征表示feeg,完成eeg信号特征学习。
19、步骤4.2的具体过程如下:
20、步骤4.2.1、对第n层多层次时空特征自适应集成模块的输入pn-1进行维度变换,得到时间特征学习分支输入tn、空间特征学习分支输入sn;
21、tn=reshape(pn-1) (3)
22、sn=pn-1 (4)
23、其中,reshape(i)代表维度变换操作,tn为时间特征学习分支输入,sn为空间特征学习分支输入;
24、步骤4.2.2、搭建时间特征学习分支:采用一维卷积完成对eeg模态特征在时间尺度上进一步特征学习,接着采用自注意力机制,通过输入特征自身生成查询向量、键向量以及值向量,以实现对时间尺度上eeg特征序列内部相对重要信息的选择,得到eeg模态时间特征sa(tn′):
25、t′n=conv1d(tn) (5)
26、
27、其中,sa(i)代表自注意力操作,wq、wk、wv分别代表用于生成查询向量、键向量以及值向量的参数矩阵,dk代表缩放点积因子,softmax(i)代表softmax激活函数,用于对每列数据进行归一化,avgpool(i)代表全局平均池化操作,w′、w″代表权重矩阵,sa(tn′)为通过学习得到的eeg模态时间特征,t′n为时间特征学习分支中conv1d(i)的输出特征;
28、步骤4.2.3、搭建空间特征学习分支:采用一维卷积完成对eeg模态特征序列在空间尺度上的关系建模,以捕捉模态内部各通道之间关系,接着通过通道注意力机制以自适应地给予相对重要的特征通道更高的权重,得到eeg模态空间特征ca(s′n):
29、s′n=conv1d(sn) (7)
30、ca(s′n)=sigmoid(w″(w′(avgpool(sn))))isn (8)
31、其中,ca(s′n)为通过学习得到的eeg模态空间特征,s′n为空间特征学习分支中conv1d(i)的输出特征;
32、步骤4.2.4、对eeg模态时间特征sa(tn′)与空间特征ca(s′n)进行融合,得到第n层中的时空特征联合学习模块的输出特征pn:
33、pn=sa(tn′)+ca(s′n) (9)
34、其中,pn为第n层中的时空特征联合学习模块的输出特征,sa(tn′)为通过学习得到的eeg模态时间特征,ca(s′n)为通过学习得到的eeg模态空间特征;
35、步骤4.2.5搭建多层次特征自适应集成模块
36、首先,采用余弦相似度评估模型的先前的每个多层次时空特征自适应集成模块的输入特征p=[p0,...,pi,...,pn-1]与时空特征联合学习模块的输出特征pn的相似度,并对其归一化,从而获得不同层次相应特征的权重系数1-αi,进而得到多层次集成特征mn;
37、其次,采用门控机制对pn、多层次集成特征mn两个输入特征处理,得到第n层多层次时空特征自适应集成模块的输出特征pn;
38、具体过程如下:
39、cos_simi,n=(pi,pn) (10)
40、
41、
42、
43、
44、其中,cos_simi,n代表计算pi与pn的余弦相似度的操作,代表拼接操作,代表门控机制中的中间特征,sigmoid(i)代表sigmoid激活函数,tanh(i)代表tanh激活函数,⊙代表点乘操作,pn为第n层多层次时空特征自适应集成模块的输出特征,mn为多层次集成特征,1-αi为不同层次相应特征的权重系数。
45、人脸图像特征学习部分的搭建过程具体如下:
46、步骤6.1、随机选取任一1s数据片段中的5帧作为人脸图像数据输入预训练的卷积神经网络,预训练的卷积神经网络处理每帧人脸图像样本后得到每帧人脸图像样本对应的人脸图像特征;
47、步骤6.2、将步骤6.1得到的人脸图像特征依次送入卷积长短期记忆网络中,再将卷积长短期记忆网络的输出特征进行展平操作,并结合全连接层进行维度压缩,生成最终的人脸图像特征表示fface,完成人脸图像特征学习。
48、特有-共享特征融合模块的搭建过程具体如下:
49、步骤7.1、搭建特有-共享特征融合模块
50、对eeg模态特征feeg、人脸图像模态特征fface进行特有特征学习、共享特征学习,得到eeg特有特征学习输出特征seeg,eeg共享特征学习输出特征ceeg,人脸图像特有特征学习输出特征sface,人脸图像特有特征学习输出特征cface;其中,每个特征学习分支均由三层全连接层构成,eeg共享特征学习分支与人脸图像特有特征学习分支共享网络参数;
51、步骤7.2、加入损失函数对特有-共享特征融合模块输出特征进行约束
52、在eeg特有特征学习输出特征seeg与eeg共享特征学习输出特征ceeg之间、eeg特有特征学习输出特征seeg与人脸图像特有特征学习输出特征sface之间、人脸图像特有特征学习输出特征sface与人脸图像特有特征学习输出特征cface之间引入差异性损失,eeg共享特征学习输出特征ceeg与人脸图像特有特征学习输出特征cface之间引入中心距差异;
53、步骤7.3、将ceeg、cface送入全连接层进行生成cfusion;
54、步骤7.4、搭建权重生成网络,由参数矩阵和全连接层组成,将sface、seeg、cfusion送入权重生成网络生成相应权重,并加权后的特征送入全连接层,即完成mstfai-scff模型,公式如下:
55、αeeg=weegiconcat(seeg,cfusion,sface) (15)
56、αfusion=wfusioniconcat(seeg,cfusion,sface) (16)
57、αface=wfaceiconcat(seeg,cfusion,sface) (17)
58、predict=linear(concat(αeegseeg,αfusioncfusion,αfacesface)) (18)
59、其中,αeeg、αfusion、αface分别表示eeg特有特征学习输出特征seeg、模态间共享特征cfusion、人脸图像特有特征学习输出特征sface对应的权重,而concat(i)用于表示拼接操作,linear(i)用于表示全连接层,predict为模型输出,即预测情感类别。
60、步骤7.2差异性损失中引入了软子空间正交性约束与frobenius范数,具体如下:
61、
62、式中,用于表示frobenius范数的平方,seeg为eeg特有特征学习输出特征,ceeg为eeg共享特征学习输出特征、sface为人脸图像特有特征学习输出特征、cface为人脸图像特有特征学习输出特征;
63、所述中心距差异作为相似性损失约束,具体公式如下:
64、
65、
66、其中,k表示中心矩的最大阶数,||·||2表示l2范数,e(i)表示期望,c2(i)表示方差。
67、步骤3的具体过程如下:将训练集中的每个数据片段样本均带入步骤2搭建好的mstfai-scff模型,分别输出其预测情感类别,将每个数据片段样本的预测情感类别与其情感类别标签进行比较,并将两者之间的损失最小化,通过反向传播算法更新模型中的网络参数,直至模型在训练集上保持稳定的情感预测性能,保存模型,得到训练好的模型;
68、其中,损失最小化过程如下:
69、l=ltask+αlsim+βldiff (22)
70、其中,α、β分别为各损失函数的权重系数,l表示总损失,ltask表示用于计算预测情感类别与其情感类别标签之间的交叉熵损失函数,lsim表示相似性损失约束,ldiff表示差异性损失约束。
71、步骤4具体过程如下:用测试集对训练好的模型进行测试,并保存模型在该部分测试集上的实验结果,共测试五次,保证每次所使用的测试集中的数据片段不重叠,再将5次测试结果的平均值作为模型的最终测试结果;若测试结果达到预期要求,则保存模型,得到情感识别模型,若测试结果未达到预期要求,则对模型架构、参数进行调整,并重复步骤1到步骤4,直至测试结果达到预期要求,保存模型,得到情感识别模型。
72、本发明的有益效果是:
73、(1)多层次特征集成和脑电与人脸特征融合的情感识别方法,为提取更为完备的eeg特征表示,设计了mstfai模块,采用时空双流结构来捕捉eeg信号的时空特征,再基于多层次eeg特征之间的相似度来生成各层次特征的权重,并将集成后的多层次加权特征结合门控机制以自适应地保留相对重要的特征信息。通过mstfai模块的堆叠,模型可以捕获更为完备的eeg特征,为后续的特征融合提供更为强大的eeg特征表示,进而提高模型在情感识别任务上的识别精度;
74、(2)多层次特征集成和脑电与人脸特征融合的情感识别方法,为捕捉两模态的语义一致性与互补性,设计了scff模块,将各模态特征学习分为特有特征学习、共享特征学习两种方式,并结合损失对各特征之间进行相似性或差异性约束。通过这种方式,模型可以同时学习到各模态内部的特有语义信息以及共享语义信息,使得模型在保证对单模态特征学习能力的同时完成对模态间关系的捕捉,进而提高模型在情感识别任务上的识别精度;
75、(3)本发明多层次特征集成和脑电与人脸特征融合的情感识别方法,在deap数据集和mahnob-hci数据集上进行了大量实验,采用跨试验验证以及5折交叉验证两种实验方法展示了所提出方法的有效性以及可行性,克服了由于基于eeg信号与人脸图像的双模态情感识别模型的准确率有限,导致目前基于深度学习模型的实际应用受限的问题。
- 还没有人留言评论。精彩留言会获得点赞!