一种基于卷积自编码器-多时序通道卷积神经网络的软测量模型构建方法
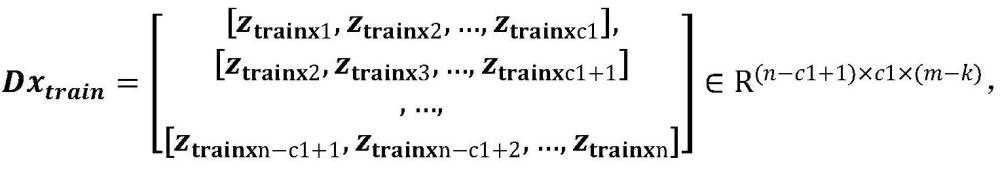
本发明涉及一种数据驱动的软测量方法,尤其涉及一种基于卷积自编码器-多时序通道卷积神经网络的软测量模型构建方法。
背景技术:
1、在工业生产中,先进的、智能的控制技术被广泛用于监控生产过程以换取最大的经济效益,这类方法广泛依赖于关键产品质量的实时监测。然而,这些质量指标往往难以实时采集,通过实验分析得到的质量指标,相对过程测量具有相当大的时间延迟。为了解决这些问题,研究者们开发了基于软测量的方法,通过易于测量的过程数据建立数学模型来间接估计那些难以测量的质量数据。随着传感器技术的发展,丰富的过程数据被采集和存储下来,基于数据驱动的软测量模型构建方法已经成为主流,其中最流行的方法有主成分回归、偏最小二乘回归、人工神经网络和支持向量回归等,然而这类方法大多使用低维人工特征进行建模,很难提取高维大数据中的代表性特征。
2、近年来,随着深度学习技术的发展,复杂、大规模系统中的大数据具有的高维、无关信息和高冗余信息等问题得到了很好的解决。其中,卷积神经网络(convolutionalneural network,cnn)和自编码器(autoencoder,ae)是两种典型的深度学习网络。cnn是一个由多层卷积层构成的深度网络,其二维卷积核可以在数据的时间维度进行滑动,从而提取数据的时序特征。ae则是一种网络框架,其结构分为编码器和解码器两部分,其中,编码器负责从输入数据提取隐藏特征,解码器负责使用提取的特征进行输入重构。通过最小化输入和重构输入的误差来训练网络得到包含输入数据特性的潜变量,潜变量可作为其它网络的输入以构建更强大和更准确的软测量模型。
3、随着工业规模的不断增长,越来越多的关键质量指标需要监测,这些关键质量指标对应的过程变量自身有着明显的时序关系。为了监测采样率低于过程测量的产品质量指标,对每个关键质量指标都训练一个模型进行预测将极大地损耗资源,且不利于后续对模型的调整。另外,这些关键质量指标根据不同的监测环境和指标特性,往往拥有不同的采样率,这些问题同时也对训练网络模型造成阻碍。此外,在考虑变量之间时序关系的前提下减少模型训练所用的时间也是待解决的问题。
技术实现思路
1、本发明所要解决的主要技术问题是:针对多采样率的多个质量变量,如何更快速地提取其共有特征并分别针对每个质量变量构建精度更高的软测量模型。具体来讲,本发明首先将不同传感器所采集的数据标准化并将其转换为时间窗形式的数据。将卷积层替代自编码器中的全连接层以构成卷积自编码器(convolutional autoencoder,cae)模块,去除池化层以保证重要信息不会在池化过程中被遗漏。将预处理的过程变量作为模型输入,通过最小化各个模块输入和输出的重构误差以完成该cae模型的训练过程。将已处理数据输入到完成训练的cae模型中以提取每个时间窗数据的一维特征。选择多时序通道的数量,根据通道数将提取的特征和质量变量标签转换为时间窗形式的特征。构建多时序通道卷积神经网络,先构建卷积层将时间窗特征降至一维的共享特征,再以质量变量数量和多时序网络通道数的乘积来构建神经网络输出全连接层的通道数。网络训练过程中,卷积核在二维数据时间窗上移动,当质量变量存在真实标签时,使用对应的通道反向传播,其余通道则不参加训练。在完成多时序通道卷积神经网络的训练后,网络提取到多质量变量的共享特征。最后针对每个质量变量,使用共享特征作为输入,对应的质量变量标签作为输出,训练各个子全连接网络从而完成工业过程多采样率质量变量的软测量模型构建。
2、本发明解决上述技术问题所采用的技术方案为:一种新的基于卷积自编码器-多时序通道卷积神经网络的软测量模型构建方法,包括以下所示步骤:
3、步骤(1):数据采集及数据预处理,具体的实施过程如下所示:
4、步骤(1.1):采集正常运行工况下的n个采样时刻m个传感器监测数据以组成数据集x=[x1,x2,...,xn]∈rn×m,其中n为数据集样本数,m为传感器测量变量数,r为实数集;
5、步骤(1.2):将采集的传感器数据使用z-score标准化方法进行数据预处理,具体计算公式如下:
6、
7、其中,μi表示数据集矩阵中单个传感器所有样本xi的均值,σi表示标准差,将所有传感器的均值u=[μ1,μ2,...,μm]和标准差φ=[σ1,σ2,...,σm]进行储存。对每一列的数据进行标准化后得到标准化数据集ztrain=[ztrain1,ztrain2,...,ztrainn]∈rn×m;
8、步骤(2):选取需要通过软测量模型拟合、预测的质量变量数据ytrain=[ztrainy1,ztrainy2,...,ztrainyn]∈rn×k及用来预测质量变量的过程变量xtrain=[ztrainx1,ztrainx2,...,ztrainxn]∈rn×(m-k);
9、步骤(3):构建卷积自编码器模块,设计训练器并设置网络超参数,具体的实施过程如下所示:
10、步骤(3.1):根据工业过程需求,选取时间窗大小c1;
11、步骤(3.2):对于卷积自编码器的编码器模块,使用c1-1层卷积层进行构建,卷积层的设置如下:卷积核大小kernel_size设置为2,填充大小padding设置为0,卷积步长stride设置为1,根据卷积层数大小计算公式:
12、
13、其中w和n分别为卷积层输入的层数大小和输出的层数大小。根据此卷积设置,可以在不经过池化层的前提下完成对数据维度的降维,没有池化层的特征压缩可以使整个编码器能够保留更多有用信息;
14、步骤(3.3):对于卷积自编码器的解码器模块,使用c1-1层反卷积层进行构建,反卷积层的设置如下:卷积核大小kernel_size设置为2,卷积步长stride设置为1,根据反卷积层数大小计算公式:
15、n=(w-1)*stride-2*padding+kernel_size (3)
16、其中w和n分别为反卷积层输入的层数大小和输出的层数大小。根据此卷积设置,可以完成对数据维度的增加以完成解码器功能;
17、步骤(3.4):对于卷积自编码器模块,根据mse损失函数以最小化输入与输出的重构误差,其公式如下:
18、
19、其中x表示输入过程变量,n表示输入样本数,h=f(x)表示编码器编码过程,h表示输入经过编码器后得到的隐藏层特征,y=g(h)表示解码器解码过程,y表示隐层数据经过解码器后得到的重构数据;
20、步骤(3.5):运用adam训练器对整个卷积自编码器模块进行训练优化,并使得在训练完成后,可以得到隐藏层特征h;
21、步骤(3.6):通过多次测试设置训练周期epoch,学习率lr等网络超参数;
22、步骤(4):将过程变量xtrain=[ztrainx1,ztrainx2,…,ztrainxn]∈rn×(m-k)转换为时间窗形式的数据其中c1表示时间窗的大小,k表示待测量质量变量数。将时间窗数据输入到卷积自编码器模块中,经过训练获得输入和输出重构误差最小情况下的隐藏层特征htrain=[htrain1,htrain2,...,htrainn-c1+1]∈r(n-c1+1)×h,其中h表示特征的维度大小;
23、步骤(5):构建多时序通道卷积神经网络模块,设计训练器并设置网络超参数,具体的实施过程如下所示:
24、步骤(5.1):根据工业过程需求,选取多时序通道数c2。一般而言,c2选取的值越大,模型的效果越好,训练所花费的时间越长;
25、步骤(5.2):构建a层卷积层,a可根据c1及c2自行选择,卷积层的设置如下:卷积核大小kernel_size设置为2,填充大小padding设置为0,卷积步长stride设置为1,卷积层的目的是将数据降至一维以提取共享特征hshare;
26、步骤(5.3):构建一层全连接层,全连接层的输入维度是卷积层的输出维度,而全连接层的输出维度为待测量质量变量数k与多时序通道数c2的乘积;
27、步骤(5.4):将a层卷积层及全连接层相连接构建完整的多时序通道卷积神经网络结构;
28、步骤(5.5):为了过滤出标签中的真实值,预先设置公式如下:
29、
30、其中yr表示标签中的真实值。
31、步骤(5.6):对于设置好的多时序通道卷积神经网络模块,根据改进的mse损失函数以最小化输出拟合值与输入所对应的实际质量数据的误差,其公式如下:
32、
33、其中x表示输入过程数据,y表示输入数据所对应的质量变量标签,n表示输入样本数,z表示样本中真实值的数量,c2表示多时序通道数,f(x)表示网络方程
34、步骤(5.7):运用adam训练器对整个多时序通道卷积神经网络模块进行训练优化,并使得在训练完成后,可以得到隐藏层特征hshare;
35、步骤(5.8):通过多次测试设置训练周期epoch,学习率lr等网络超参数;
36、步骤(6):将特征变量htrain=[htrain1,htrain2,...,htrainn-c1+1]∈r(n-c1+1)×h转换为时间窗形式的数据其中c1表示时间窗的大小,c2表示多时序通道数,h表示特征的维度大小。将质量变量标签ytrain=[ztrainy1,ztrainy2,...,ztrainyn]∈rn×k转换为时间窗形式的数据其中c1表示时间窗的大小,c2表示多时序通道数,k表示质量变量数。以dhtrain和dytrain分别作为输入和输出训练多时序通道卷积神经网络模块,经过训练获得共享特征hshare=[hs_trainc1+c2-1,hs_trainc1+c2,...,hs_trainn]∈r(n-c1-c2+2)×h_share,其中h_share表示共享特征的维度大小;
37、步骤(7):构建用于各个质量变量测量的各个子全连接神经网络模块,设计训练器并设置网络超参数,具体的实施过程如下所示:
38、步骤(7.1):构建两层全连接层网络,网络的输入维度为共享特征的维度大小h_share,输出维度为1,中间层维度则可根据工业过程自行设置;
39、步骤(7.2):对于各个子全连接神经网络模块,根据mse损失函数以最小化输入与输出的重构误差,其公式如下:
40、
41、其中x表示输入过程变量,y表示输入数据所对应的质量变量标签,n表示输入样本数,z表示样本中真实值的数量,f(x)表示网络方程;
42、步骤(7.3):运用adam训练器对整个卷积自编码器模块进行训练优化;
43、步骤(7.4):通过多次测试设置训练周期epoch,学习率lr等网络超参数;
44、步骤(8):将共享特征hshare=[hstrainc1+c2-1,hstrainc1+c2,...,hs_trainn]∈r(n-c1-c2+2)×h_share和每个质量变量ytraini=[ztrainy(i)c1+c2-1,ztrainy(i)c1+c2,...,ztrainy(i)n]∈rn×1作为输入和输出训练各个子全连接神经网络模块,最终完成软测量模型的构建。
45、上述步骤(1)至步骤(8)为本发明方法的离线建模阶段,如下所示步骤(9)至步骤(14)为本发明方法的在线分析的实施过程。
46、步骤(9):收集新采样时刻的带噪样本数据其中为n样本数,m为传感器测量变量数,r为实数集;
47、步骤(10):对得到的数据利用步骤(1.2)中得到的均值u=[μ1,μ2,...,μm]和标准差φ=[σ1,σ2,...,σm]进行处理,从而得到标准化后的测试样本数据
48、步骤(11):将数据按照步骤(2)的选取方法选取质量变量ytest=[ztesty1,ztesty2,...,ztestyn]∈rn×k及过程变量
49、步骤(12):按步骤(4)中的方式将过程变量转换为时间窗形式的数据dxtest并输入卷积自编码器模块,以得到隐藏层特征htest;
50、步骤(13):按步骤(6)中的方式将隐藏层特征变量htest转换为时间窗形式的数据dhtest并输入多时序通道卷积神经网络模块,以得到共享特征hshare;
51、步骤(14):将共享特征hshare输入到各个子全连接神经网络模块得到各个质量变量的预测值并与实际质变量数据ytest=[ztrainyc1+c2-1,ztrainyc1+c2,...,ztrainyn]∈r(n-c1-c2+2)×k进行对比测试。
52、与传统方法相比,本发明方法的优势在于:
53、首先,本发明方法在可以通过提取多个质量变量的共享特征,实现对多个不同采样率的质量变量的实时预测;其次,本发明方法还通过训练卷积自编码器,预先提取过程变量之间的时序特征,从而实现降低模型的整体训练时间。最后,本发明方法相较于其他传统的训练方法,可以更好地处理多采样率质量变量之间的时序关系,且能够更高效、稳定地对质量变量进行拟合、预测,并且能够获得更优的效果。可以说,本发明方法是一种更为优秀的软测量模型构建方法。
- 还没有人留言评论。精彩留言会获得点赞!