一种基于连通系数的多密度聚类方法
本发明涉及密度聚类,具体而言,尤其涉及一种基于连通系数的多密度聚类方法。
背景技术:
1、聚类是一种机器学习领域内重要的无监督学习方法,其旨在将数据集中的对象划分成聚类相似特征的组,划分到同一组的对象之间用于较高的相似性,而不同组的对象之间具有较大的差异性。聚类被广泛应用在数据挖掘、市场分析、生物信息学、推荐系统、自然语言处理等领域。例如聚类在数据挖掘中被用来发现数据中的潜在模式和结构,以及识别隐藏在数据背后的规律;在基因组学和蛋白质组学中,聚类可用于发现基因表达模式、研究疾病分类和诊断等;在推荐系统中,聚类可以用于用户分群,帮助推荐系统更精准地向用户推荐感兴趣的产品或内容;在文本数据处理中,聚类可用于文档分类、主题提取、情感分析等。
2、聚类可以大致分为划分聚类,分层聚类,密度聚类,基于图的聚类等几种类别。密度聚类领域主要的方法包括dbcsan方法,optics方法,密度峰值聚方法。近些年密度聚类的改进大多是基于2014发表在science上的密度峰值聚类算法进行改进。
3、密度峰值聚类算法主要思想是寻找数据点的密度峰值(density peaks),并根据峰值之间的距离和密度差异来划分簇。其关键步骤包括:1、密度距离的定义:使用何种方式定义密度;2、寻找密度峰值:遍历所有数据点,计算每个数据点的密度和相对于其他点的最小距离。密度大于某一阈值的点,且其偏移距离值也较大,则被认为是密度峰值点。3、簇分配:将非峰值点分配到与其最近的密度峰值点所在的簇中。
4、dpc算法的优点在于对簇的形状和大小没有假设,且不需要预先指定簇的数量。但也存在一些挑战:首先是如何稳定且自动化从决策图中选择出最佳的簇中心,其次是如何保证在分配时不会产生错误的关联(因为一旦某个对象被错误分配后,被分配到当前对象下的对象们都将被错误分配)。
5、目前流行的密度聚类方法大多采用先搜索密度峰值点,再根据度量距离分配剩余点的方法完成聚类,虽然这种方式在一定程度上解决了划分聚类无法处理非凸簇与流形数据的问题,但是其仍存在以下方面的缺陷:
6、1.无法处理多种密度结构数据共存的情况:现有密度聚类方法会更多关注高密度区域,从而无法很好地捕捉低密度区域的结构。这一点在低密度区域包围高密度区域时会更加明显,即使密度差异很大,低密度区域也会被忽视。
7、2.需要手动选择聚类中心:现有密度聚类方法需要根据偏移距离与密度绘制决策图,然后在图中手动选择合适的点作为初始点,虽然也有方法利用决策图的横纵坐标的乘积进行自动选择,但其鲁棒性差,非常容易选择错误。
8、3.标签错误传播:剩余点分配过程中其要选择密度比其大且距离最近的点。使得其忽视簇内密度结构,过度关注高密度区域。
技术实现思路
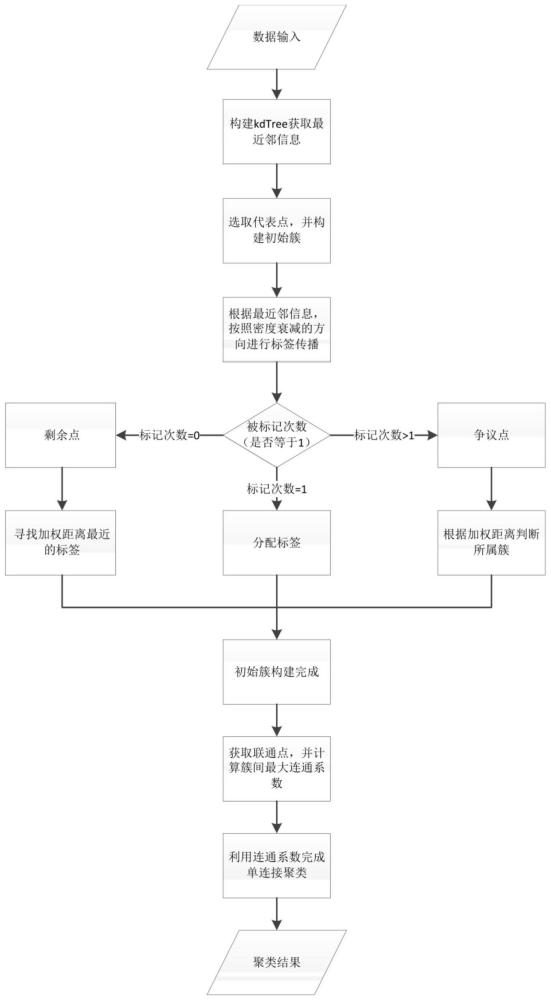
1、根据上述提出的技术问题,提供一种基于连通系数的多密度聚类方法。本发明主要利用代表点与连通系数的概念,将数据集先划分出初始簇骨干,然后使用密度衰减的策略进行初始标签传播,最终利用连通系数合并初始簇。
2、本发明采用的技术手段如下:
3、一种基于连通系数的多密度聚类方法,包括:
4、s1、获取真实聚类任务数据集,并对数据进行处理,得到每个点的最近邻信息与最近邻距离;
5、s2、根据得到的最近邻信息,计算当前对象的密度;
6、s3、基于计算得到的当前对象的密度,计算每个点的反向最近邻个数;
7、s4、选取反向最近邻个数大于平均值的点作为代表点,利用代表点与互近邻结构生成初始簇骨架;
8、s5、利用密度衰减概念对代表点标签向外拓展;
9、s6、计算加权距离,根据加权距离判定存在多个标签值的最终标签,并分配剩余点到最近存在标签的近邻对象中;
10、s7、计算当前簇内所有数据对象的平均密度;
11、s8、获取连接点,计算每一对连接点的连通系数,并通过连接点计算两簇之间的连通系数;
12、s9、根据连通系数将初始标签进行合并,直到符合预定的簇数。
13、进一步地,所述步骤s1,具体包括:
14、s11、获取真实聚类任务数据集,并对数据进行处理最大最小归一化处理;
15、s12、构建kd树,加速最近邻的搜索过程,得到每个点的最近邻信息与最近邻距离。
16、进一步地,所述步骤s2中,根据得到的最近邻信息,计算当前对象的密度,其计算公式如下:
17、
18、其中,k是最近邻参数,nk(xi)是样本xi的最近邻集合,d(xi,xj)是样本xi,xj之间的欧氏距离。
19、进一步地,所述步骤s3,具体包括:
20、s31、设xi,xj是数据集中的样本对象,xk是xi第k个近邻,则定义xi的最近邻集合,如下:
21、
22、s32、将样本xi视为最近邻的样本集合称为xi的反向最近邻,设xi,xj是数据集中的样本对象,nk(xi)是样本xi的最近邻集合,则定义样本xi的反向最近邻集合,如下:
23、
24、进一步地,所述步骤s4,具体包括:
25、s41、选取反向最近邻个数大于平均值的点作为代表点,定义代表点集合的公式,如下:
26、rep={xi||rk(xi)|>k}
27、s42、从代表点集合中,提取一个未经遍历的代表点,加入遍历队列;
28、s43、从遍历队列中,提取一代表点,并探索其互近邻中是否有代表点,如果存在则为其赋予相同标签并将其加入遍历队列;
29、s44、直至队列为空,则重复步骤s42,对新的子簇进行子簇核心生成;
30、s45、直至代表点序列为空,此时已生成若干个子簇核心结构。
31、进一步地,所述步骤s5,具体包括:
32、s51、将一个子簇核心结构入队,提取队首样本;
33、s52、遍历队首样本的最近邻,如果存在一个最近邻密度小于其当前点,则为其赋予相同标签,同时入队,重复执行步骤s52,直至队列为空;
34、s53、将另一个子簇核心入队,重复执行步骤s51和步骤s52,如果拓展时,存在一个点已经拥有标签,将其标签标记为-1,同时加入争议点序列,记录哪些点同时向该点进行拓展。
35、进一步地,所述步骤s6,具体包括:
36、s61、计算加权距离,计算公式如下:
37、
38、其中,xi是当前争议点,d(xi,xj)是欧式距离;
39、s62、将争议点分配到其加权距离最短的对象中;
40、s63、循环遍历尚未分配标签的剩余点,查询其是否有最近邻存在标签,且判断二者加权距离是否超过k近邻的欧氏距离,公式如下:
41、label(xi)={label(xj)|xj∈nk(xi)∩dw(xi,xj)<d(xi,xk)}
42、其中,xk是xi的第k近邻。
43、进一步地,所述步骤s8,具体包括:
44、s81、获取连接点,已知两个数据对象xi,xj,二者互为最近邻,且二者的标签结果不同,则二者构成的稳定结构为连接点,公式表示如下:
45、(xi,xj)={(xi,xj)|xi∈nk(xj)∩xj∈nk(xi)∩label(xi)≠label(xj)}
46、s82、计算当前一对连接点的连通系数:
47、
48、其中,ρi是xi的密度,分别是xi、xj所在子簇,分别是子簇的平均密度;
49、s83、由两簇内元素构成的连接点元组,其连通系数的最大值为两簇之间的连通系数,公式如下:
50、ψ(ci,cj)=max(ξ(xm,xn)|label(xm)=ci∩label(xn)=cj)。
51、进一步地,所述步骤s9,具体包括:
52、s91、获取最大的簇间连通系数
53、s92、将两簇内所有对象的标签修改为同一个标签;
54、s93、移除已经合并完成的连通系数;
55、s94、重复执行步骤s91至步骤s93,直至簇数符合预期,得到聚类标签。
56、较现有技术相比,本发明具有以下优点:
57、1、本发明提供的基于连通系数的多密度聚类方法,不依赖单个密度峰值,使用骨架结构提升了初始结构的稳定性与鲁棒性。
58、2、本发明提供的基于连通系数的多密度聚类方法,其距离度量与连通系数均充分考虑了密度分层的概念,所以在多密度数据分布的数据集中,展示出了更好的聚类效果。
59、3、本发明提供的基于连通系数的多密度聚类方法,在nmi与ari两种指标的衡量下,提高了原本算法的聚类精度。
60、基于上述理由本发明可在密度聚类等领域广泛推广。
- 还没有人留言评论。精彩留言会获得点赞!