基于双支路GAN和SwinTransformer的PET和MRI图像融合方法
本发明涉及图像处理,具体为基于双支路gan和swin transformer的pet和mri图像融合方法。
背景技术:
1、现如今,医学图像在临床疾病的诊断和治疗中发挥着举足轻重的作用。随着传感器与成像技术的不断发展,多种多样的医学成像设备随之产生。不同类型的医学成像设备通过不同的成像机理采集人体信息,从而产生各种不同类型(模态)的医学图像。现有的医学图像总体上可以分为两类,即结构型图像与功能型图像。磁共振成像(magneticresonance image,mri)作为一种结构型图像,能够提供人体的软组织信息,呈现为纹理细节和致密结构信息丰富的图像。正电子发射断层(positron emission tomography,pet)图像作为一种功能型图像,能够反映人体新陈代谢等情况,通常以伪彩色的形式呈现。mri图像的空间分辨率高,结构信息丰富,但缺少能够反映人体新陈代谢情况的功能信息;pet图像具有体现人体新陈代谢的功能信息,但其空间分辨率低,结构信息匮乏。
2、因此,在实际的临床应用中,仅使用单一模态的医学图像通常无法较为完整地获得所需的人体信息,这就要求在临床应用中同时使用多种模态的医学图像。然而,同时获取不同模态的医学图像势必会耗费更多的人力、财力和时间等。为此,通过采用一定的技术手段将pet与mri图像进行融合,从而使得一幅融合图像能够同时体现pet与mri图像中的人体结构与功能信息,以便能够更好地在临床应用中提供客观的人体参考信息,进而有助于临床医生做出更加精准的诊断;
3、针对pet与mri图像各自的特性,现有技术提供了不同的融合策略和方法,这些方法总体上可以分为传统的融合方法和基于深度学习的融合方法。传统的融合方法在过去几十年中虽然取得了较好的图像融合效果,但该类方法往往需要人工设计融合规则,而且融合规则的设计随着融合性能需求的逐步提高而变得的越来越复杂。深度学习由于其强大的特征提取能力等,近年来在计算机视觉等领域得到了广泛的应用。相较于传统的图像融合方法,基于深度学习的图像融合方法在一定程度上能够避免传统图像融合方法所面临的复杂的融合规则设计问题等,从而有效地降低图像融合的计算复杂度。因此,基于深度学习的图像融合方法近年来倍受关注,并已发展成为当下主流的图像融合方法。
4、目前,用于医学图像融合的深度学习方法主要包括基于卷积神经网络(convolutional neural network,cnn)的方法,基于生成对抗网络(generativeadversarial network,gan)的方法,以及基于transformer的方法等。基于cnn的方法相较于传统方法提高了局部信息的提取能力和泛化能力,但该类方法提取图像全局特征的能力欠佳,致使图像融合结果中整体结构信息受损等。此外,基于cnn的融合方法是一种监督的融合方法,然而,实际的图像融合任务并不存在真实值(ground truth),因此作为监督的cnn方法在图像融合任务中受到限制。相对地,基于gan的方法是一种端到端的通过对生成器和判别器两个网络进行对抗训练来获得融合图像的非监督算法,其中生成器旨在生成具有pet图像组织信息并附加mri图像结构信息的图像,而判别器旨在迫使生成的图像具有更多的mri结构细节信息,从而使得融合得到图像既具有pet图像显著的功能信息(以伪彩色呈现)又包含mri图像丰富的结构信息。简言之,基于gan的融合方法是通过生成器与判别器之间的对抗博弈来进行无监督的训练,从而不断地提升融合图像的效果。
5、相较于基于cnn的融合方法,基于gan的方法取得了更好的融合效果。然而,现有的基于gan的融合方法中,其网络主干仍然为聚焦于局部特征提取的cnn网络。不同于仅聚焦于提取局部特征的cnn,基于transformer的方法借助多头自注意机制来捕获长距离依赖关系,从而能够提取图像中的全局特征信息,一定程度上克服了cnn只能提取局部特征的局限性,使得融合结果具有更好的全局视觉效果,从而改善了图像融合的性能。
6、transformer模型由vaswani等提出,该模型在自然语言处理(natural languageprocessing,nlp)领域得到了成功应用。dosovitskiy等提出了用于图像分类任务的视觉transformer(vision transformer,vit),该模型将图像分成16×16的图像块并输入到标准的transformer编码器中,然后利用多头自注意力机制对全局特征进行建模,取得了很好的效果。vit的提出,促进了transformer在计算机视觉领域的广泛应用。然而,由于图像的维数较高和不同尺度的问题,致使将transformer从自然语言处理领域应用到图像领域存在着一些挑战。为此,liu等提出了一种在不重合的窗口区域内做多头自注意力计算的swintransformer,并通过移动窗口的操作达到提取全局特征的目的。与标准的transformer相比,swin transformer的计算复杂度与图像的尺寸大小呈线性关系,具有较高的计算效率。vs等将transformer引入图像融合领域,提出了一种基于transformer的两阶段图像融合策略,即在第一阶段训练一个自编码器以提取源图像中的多尺度深度特征,在第二阶段采用空间transformer融合网络融合特征信息。现有的基于transformer的图像融合方法取得了优异的融合效果,但依然有进一步提升的空间,特别是将无监督、端到端的gan模型和捕获全局特征的transformer进行有效结合,从而取得更好的融合效果。
7、综上可知:目前分别基于gan和transformer的pet和mri图像融合存在以下问题,一方面gan网络的主干为聚焦于提取局部特征的cnn,从而不利于提取图像的全局特征信息;而另一方面,标准的transformer网络计算复杂度高等,本发明针对pet图像和mri图像各自的特性,为了在模型中将transformer较好的全局信息提取能力和cnn较强的局部信息提取能力进行有效结合,以达到更好的融合效果,为此提供基于双支路gan和swintransformer的pet和mri图像融合方法。
技术实现思路
1、本发明的目的是针对现有技术的缺陷,提供基于双支路gan和swin transformer的pet和mri图像融合方法,以解决上述背景技术提出的问题。
2、为实现上述目的,本发明提供如下技术方案:基于双支路gan和swin transformer的pet和mri图像融合方法,具体步骤如下:
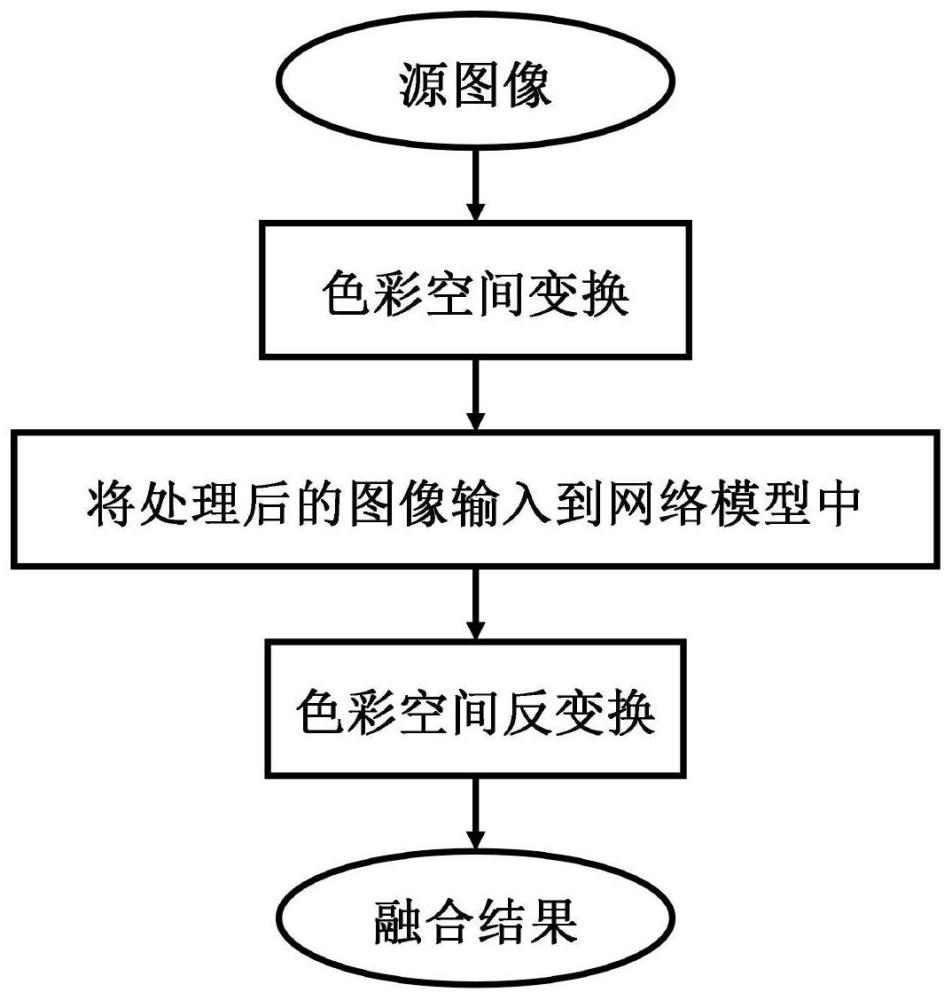
3、s1:ycbcr色彩空间转换,得到pet图像的y分量;
4、将pet图像ip进行rgb彩色空间到ycbcr彩色空间的变换,分别得到ip的y,cb,cr三个通道的分量图像ip-y,ip-cb和ip-cr,其中y分量图像包含能够反映pet图像整体结构与亮度变化的亮度信息;pet图像由rgb彩色空间至ycbcr彩色空间的具体变换过程如下式(1):
5、
6、s2:将pet图像的y分量和mri图像在通道维进行“联结”,然后输入到双支路生成对抗网络中并对网络模型进行训练;
7、将pet图像的y分量ip-y与mri图像im在通道维进行“联结”,然后输入到生成器g的两个支路中,两个支路为:cnn支路和transformer支路;生成器的两个支路分别提取所输入图像的局部特征信息和全局特征信息,然后融合生成pet图像的y分量if-y;
8、s3:利用训练好的网络模型生成融合后的pet图像的y分量;
9、在测试或应用阶段,将mri图像im和pet图像的y分量ip-y经联结后输入到训练好的生成器g中,从而生成融合图像,即融合的pet图像的y分量if-y;
10、s4:将融合所得的if-y,连同式(1)中变换得到的pet图像的cb,cr分量ip-cb、ip-cr进行从ycbcr彩色空间到rgb彩色空间的逆变换,从而得到最终的融合结果,即融合的pet图像if。
11、作为本发明的一种优选技术方案,步骤s2中需要在融合前完成网络模型的训练,所述网络模型为生成器-判别器网络模型,所述生成器-判别器网络模型的训练过程为:
12、s2-1:将经由ip-y和im联结得到的图像输入到生成器g,生成器g采用两条不同的支路分别进行图像特征信息的提取,其中两条支路分别为基于cnn的局部细节支路和基于swin transformer的全局结构支路;接着,对不同支路提取的特征进行融合,并重构出融合图像,即融合的pet图像的y分量if-y;
13、s2-2:将mri图像im和生成器所生成的图像if-y输入到mri判别器dm中,将pet图像的y分量图像ip-y和生成器所生成的图像if-y输入到pet判别器dp-y中,并利用dm和dp-y与生成器g建立对抗训练,当生成器g与判别器dm、dp-y之间的对抗训练趋于平衡时,即判别器无法区分输入的图像是生成器生成的融合图像还是原图像时,终止训练。
14、作为本发明的一种优选技术方案,步骤s2中的网络模型为生成器-判别器网络模型,所述网络模型利用生成器总损失和判别器损失组成损失函数;
15、生成器总损失:
16、在gan模型中,生成器不仅用来欺骗判别器,同时还需要约束生成的融合图像与源图像之间的内容相似性,因此,生成器总损失lg由两部分构成,分别为对抗损失ladv和内容损失lcontent,生成器总损失lg的定义如下式(2):
17、lg=ladv+λlcontent (2)
18、其中λ为用以控制ladv和lcontent两项损失之间平衡的权重系数;
19、判别器损失:
20、采用pet判别器dp-y和mri判别器dm与生成器g建立起对抗训练,分别用来迫使生成器g在生成融合图像时,同时保留尽可能多的全局结构信息和丰富的纹理细节信息,具体地,判别器损失ldp-y和ldm的定义如下:
21、
22、
23、其中,pet判别器dp-y的输入为pet图像的y分量ip-y或融合图像if-y;mri判别器dm的输入为mri图像im或融合图像if-y。
24、作为本发明的一种优选技术方案,所述生成器总损失由对抗损失ladv和内容损失lcontent组成,对抗损失ladv将判别器的判断结果反馈给生成器,用于引导生成器生成更接近真实数据分布的融合图像if-y,对抗损失ladv的定义如式(5):
25、ladv=e[log(1-dm(if-y))]+e[log(1-dp-y(if-y))] (5)
26、其中,d(·)为判别器对输入图像是来自真实图像或是来自融合图像进行判断的概率;e[·]为数学期望,即每个训练批次判别器输出的平均值;
27、式(2)中生成器总损失的第二项lcontent表示融合图像的内容损失,具体定义如下式(6)所示:
28、lcontent=αlint+βlgrad+γlssim (6)
29、其中lint为强度损失,lgrad为梯度损失,lssim为结构相似性损失;α、β、γ为平衡三者的权重系数,lint的定义如式(7)所示:
30、
31、其中,h、w为输入图像的高、宽,||·||f为f范数,a为权重系数;
32、式(6)中内容损失lcontent的第二项梯度损失lgrad的具体定义如式(8)所示:
33、
34、其中,▽为梯度运算符,b为权重系数。
35、式(6)中内容损失lcontent的第三项结构相似性损失lssim的具体定义如式(9)所示:
36、lssim=(1-lssim(if-y,ip-y))+(1-lssim(if-y,im)) (9)
37、其中lssim(·)表示两项的结构相似性。
38、作为本发明的一种优选技术方案,所述步骤s2中的网络模型的结构包括生成器的网络结构和判别器的网络结构;
39、所述生成器的网络结构包括:cnn支路、transformer支路与图像重构部分;其中,cnn支路为局部细节支路,是采用cnn提取输入图像的局部细节特征;transformer支路为全局结构支路,是采用swin transformer提取输入图像的整体结构特征信息;图像重构部分是对两条支路提取的深层特征进行融合、并重构得到融合图像,即融合后的pet图像的y分量if-y;
40、所述判别器的网络结构由六层网络构成,其中前五层为卷积块,最后一层为全连接层,mri判别器dm和pet判别器dp-y为相同的网络结构;
41、判别器用于区分pet图像的y分量ip-y、mri图像im和生成器生成的融合图像if-y,通过与生成器之间的对抗训练使得融合图像if-y的数据分布既接近于图像ip-y又接近于图像im。
42、作为本发明的一种优选技术方案,所述生成器的cnn支路:
43、生成器cnn支路主要提取输入图像中的清晰纹理信息,故采用卷积神经网络进行特征提取,为了更充分地提取输入图像中的空间纹理细节信息,cnn支路采用密集连接的四层卷积结构,即每个卷积层的输入与之前所有卷积层输出的特征图在通道上联结,四层卷积的输入特征图通道数分别为16、8、16、24个,输出特征图通道数都为8个,每层卷积由卷积核大小k为3×3、步长s为1、填充p为1、填充方式为反射填充的卷积层,bn,以及leakyrelu激活层构成;在cnn支路的末端,将四层卷积输出的特征图在通道上联结,通道数为32个,特征图尺寸大小保持不变。
44、作为本发明的一种优选技术方案,所述生成器的transformer支路由两个convblock和三个transformer block组成;
45、第一层为cnn卷积块,由卷积核大小k为3×3、步长s为1、填充p为1的卷积层,批归一化层(batchnormalization,bn),以及leakyrelu激活层构成,输出通道数n为64,用于提取输入图像中的浅层特征信息;
46、第二至四层为swin transformer层(swin transformer layer,stl),用于进一步地提取输入图像中的深层特征,并在多层stl之间采用残差连接结构,以提升网络的收敛速度、增强网络的表达能力并改善梯度消失的问题;
47、第五层为cnn卷积块,该卷积块由卷积核大小k为3×3、步长s为1、填充p为1的卷积层,bn,以及leakyrelu激活层构成,输出通道数n为64,用于对stl层输出的全局特征图进行降维,使其与局部细节支路输出的通道数保持一致;
48、swin transformer将图像划分为多个小窗口,在窗口内部计算多头自注意力,并通过移动窗口的方式进行跨窗口信息交互来达到全局建模的目的,在cnn提取浅层特征信息之后采用stl提取输入图像中的深层全局特征信息,多层stl之间采用残差连接的方式,其中每层stl由基于窗口的多头自注意力计算(window-based multi-head self-attention,w-msa)和多层感知机(multi-layer perceptron,mlp)构成,并在msa和mlp之前进行层归一化处理(layer normalization,ln),在之后加入残差连接;连续两层stls之间的区别在于第二层stl为基于移动窗口做多头自注意力计算(shifted window-basedmulti-head self-attention,sw-msa);
49、在基于窗口的多头自注意力计算中,通过将窗口大小设置为n×n把输入划分成hw/n2个不重叠的局部窗口,对于局部窗口特征图φw,其相对应的查询、键、值特征矩阵q、k、v分别为:
50、q=φwmq,k=φwmk,v=φwmv (10)
51、其中,mq、mk和mv为在不同窗口中共享的可训练参数矩阵,基于窗口的多头自注意力计算表述为:
52、
53、其中,d表示q、k的维度大小,b表示可训练的相对位置偏置,接着将多头自注意力输出的注意力矩阵送入层归一化中,然后送入到多层感知机中进行位置编码与特征映射的非线性变换,最终得到具有全局特征的特征图。
54、作为本发明的一种优选技术方案,所述图像重构部分:
55、在transformer支路与cnn支路提取到输入图像的特征后,将输入图像的特征基于通道维度联结起来,输入到图像重构部分中,图像重构部分对联结的高维特征进行降维、重构,生成融合图像if-p,即融合的pet图像的y分量;图像重构部分由一个卷积层和tanh激活层构成;卷积层采用卷积核大小k为1×1、步长s为1、填充p为0的卷积对数据进行降维,经过tanh激活层对计算结果进行归一化,生成融合图像if-p。
56、本发明的有益效果是:为了进一步提高pet和mri图像的融合效果,本发明提出了基于双支路gan和swin transformer的pet和mri图像融合方法,所提出的网络模型采用单生成器-双判别器结构,具体地,生成器采用双支路结构,不同的支路提取不同层面的图像信息,即在transformer支路(全局结构支路)中,采用swin transformer提取输入图像中的全局特征信息;在cnn支路(局部细节支路)中,采用cnn提取输入图像中的局部细节信息。其次,为了进一步约束生成器的优化方向,从内容损失、对抗损失等方面设计损失函数;在公开的数据集上的实验结果表明,本发明提出的方法不仅能充分地保留pet图像中的功能信息(以伪彩色呈现),还能够有效地重现mri图像中丰富的结构纹理等信息。
57、本发明的方法采用一种端到端的网络模型,无需设置复杂的图像融合规则,模型整体由一个生成器与两个判别器组成,利用公开的数据集进行实验的结果表明,相较于现有方法,在定性的主观视觉效果方面,本发明方法得到的融合结果对比度更高,整体视觉效果更好。再者,在定量的客观评价指标方面,本发明的方法总体较优,进而说明了本发明的方法在有效地保留pet图像功能信息(以伪彩色呈现)的同时,能够有效地融合mri图像的解剖结构信息,从而提升了pet和mri图像融合的性能。
- 还没有人留言评论。精彩留言会获得点赞!