一种融合知识图谱、知识库和大型语言模型的问答系统构建方法与流程
本发明属于自然语言处理,具体为一种融合知识图谱、知识库和大型语言模型的问答系统构建方法。
背景技术:
1、问答系统是人类从大规模数据中获取信息的重要手段。依托自然语言处理技术的问答系统使用户能够以直观、自然的方式提出问题,从而获取所需的信息。通常情况下,依据不同的知识存储媒介,知识来源可划分为知识图谱、知识库和一般文档。其中,知识库是一个广泛的概念,包括任何形式的知识存储,而知识图谱则是一种特定形式的知识库,强调实体之间的语义关系,易于查询和推理。不同垂直领域均拥有独立的知识图谱和文档库,针对这些知识图谱和文档库构建问答系统,不仅在科普、知识学习、决策支持方面具有重要意义,还可协助用户快速查找知识来源,发现不同知识对象之间的潜在联系。
2、但是现有的问答系统存在以下问题:水利行业知识图谱存在数据结构复杂,实体长度不一等特点,在特定条件下进行的多跳查询的场景比重较大,从而在实体抽取,实体链接和推理规则设计等方面存在了更高的要求。此外,深度学习自然语言处理模型很大程度上依赖于高质量的人工标注数据集,这是问答系统构建的最大困难。最后,现有的大部分问答系统都关注于某一具体技术的突破,例如实体抽取,图谱推理和整体建模,而往往忽略了系统本身的完整性。知识图谱大小有限,人工构建的规则也通常集中于部分最常见的问题类别,以这种方式构造出来的问答系统始终存在局限性,难以应用到实际的生活工作中。
技术实现思路
1、本发明的目的在于:为了解决上述提出的问题,提供一种融合知识图谱、知识库和大型语言模型的问答系统构建方法。
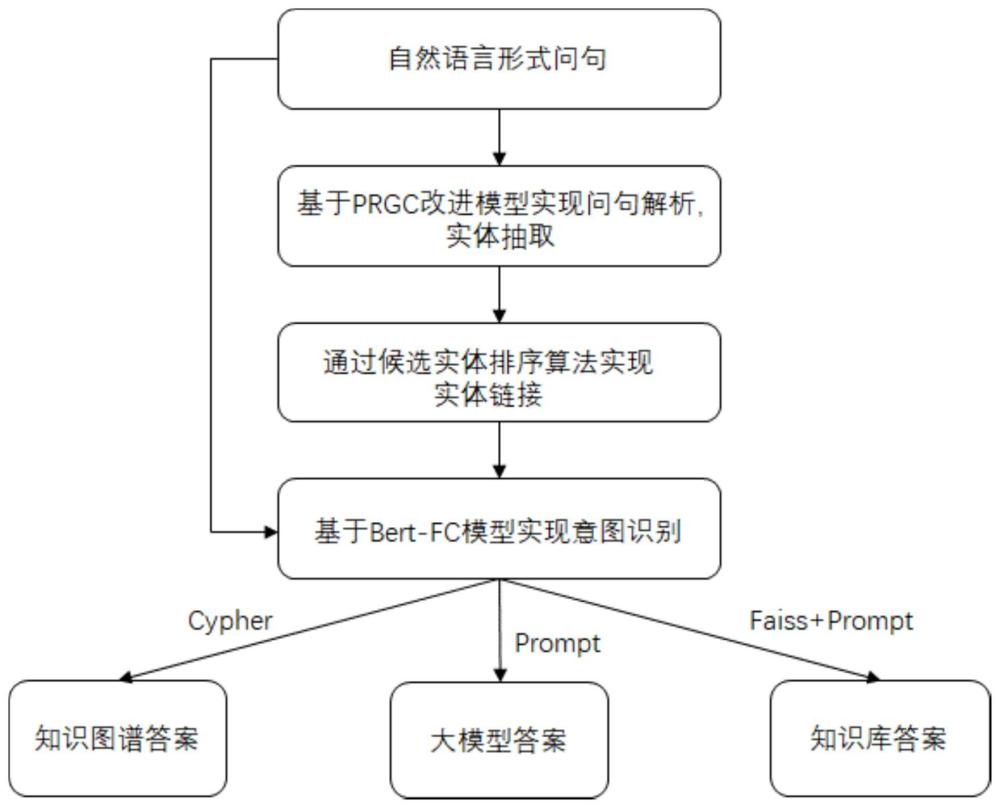
2、本发明采用的技术方案如下:一种融合知识图谱、知识库和大型语言模型的问答系统构建方法,所述包括以下步骤:
3、s1:获取用户输入问句,使用深度学习模型抽取问答系统问题中存在的所有实体提及;
4、s2:使用候选实体排序算法,在指定知识图谱中为每个实体提及寻找潜在的链接实体;
5、s3:使用预先设置的问句模板集合,对用户提出的问题进行问句分类,根据分类结果选择性地返回知识图谱答案、大语言模型答案或知识库答案之一。
6、在一优选的实施方式中,所述构建方法包括获取用户输入问句,即提取从接口传递过来的字符串形式自然语言问题。使用深度学习模型抽取问答系统问题中存在的所有实体提及,具体步骤包括模型训练和模型预测。
7、在一优选的实施方式中,所述步骤s1中,模型训练包括以下步骤:
8、s1.1:根据业务需求设计问题种子模板,并为每个模板设置一个类别标签。查找知识图谱中的所有实体,按实体类别随机填充到种子模板,并记录填充的位置索引,形成实体抽取数据集d。其中填充后的模板句子作为数据集样本,记录的位置索引作为标签。
9、s1.2:对实体抽取数据集d进行eda数据增强,具体包括随机遮盖(randommask,rm),随机删除(randomdelete,rd),随机插入(randominsertion,ri)和同义词替换(synonymreplacement,sr),得到增强数据集de-ner。
10、s1.3:使用增强数据集de-ner训练命名实体识别模型,命名实体识别模型使用prgc(potentialrelationandglobalcorrespondence)架构,其中encoder部分使用哈工大开源中文预训练roberta-wwm模型。
11、在一优选的实施方式中,所述步骤s1中,模型预测使用训练完成的prgc模型对用户输入的问句进行命名实体抽取,得到全部的实体提及。
12、在一优选的实施方式中,所述步骤s2中,具体步骤如下:
13、s2.1:遍历查找知识图谱中所有的实体,组成候选实体列表,使用faiss向量库存储该列表,文本向量化模型选择m3e-base模型。
14、s2.2:针对每个实体提及,使用faiss向量库按照l2相似度检索最相关的top-5个实体作为候选链接实体esim,并得到归一化的相似性值作为向量相似性得分ssim。
15、s2.3:针对esim中的每个候选链接实体,计算候选链接实体的流行度得分,具体计算公式为:
16、
17、其中:in-deg(e)是实体e的出度和入度之和,而α是一个超参数(一般为正整数,根据知识图谱复杂程度而不同)。
18、s2.4:检索得分为向量相似性得分与候选实体流行度得分之和,即:
19、
20、根据检索得分,重新排序候选链接实体esim,得到每个实体提及的最相关实体,完成实体链接。
21、在一优选的实施方式中,所述步骤s3中,模型训练包括以下步骤:
22、s3.1:使用s1.2得到的增强数据集de-ner进一步构建问句分类数据集:
23、s3.2:使用问句分类数据集de-cls训练问句分类模型。问句分类模型使用bert-fc架构,其中bert模型使用哈工大开源中文预训练roberta-wwm模型。
24、在一优选的实施方式中,所述步骤s3.1中,模型训练包括以下步骤:
25、s3.1.1:记问句为sentence,并从记录的实体填充位置中抽取出问句中的全部实体,记为e1、e2、…、en。
26、s3.1.2:使用特殊标记[cls]和[sep],将问句与全部实体拼接成如下形式:
27、q=[cls],sentence,[sep],e1,[sep],e2,[sep]……
28、其中,q作为样本,而种子模板的类别作为标签,得到问句分类数据集de-cls。
29、在一优选的实施方式中,所述步骤s3中,模型预测的步骤包括:
30、s3.3:根据用户输入的问题以及得到的候选链接实体,使用问句分类模型进一步分类,得到问题所属的类别,再对应返回知识图谱答案,大模型答案或知识库答案。具体描述如下:
31、s3.3.1:知识图谱答案:将链接实体结构化映射后,调用cypher查询语句进行查询和推理,返回特定实体或路径,作为知识图谱答案。
32、s3.3.2:大模型答案:将问题和链接实体的属性信息组建成prompt,进一步将该prompt输入到大模型,得到大模型答案。其中,大模型可以使用开放api,或者本地化私有部署。
33、s3.3.3:知识库答案:知识库答案包含大模型的总结性结果,还有问题相关背景知识以及背景知识出处。具体包含以下三个步骤:
34、s3.3.3.1:基于python的docx库或者pdfplumber库将本地文件(例如pdf文档)拆分成私有知识库,拆分规则有如下四种(通过正则表达式实现):
35、(1)将不在数字前后的中英文句号替换为换行符(\n)。
36、(2)在标点符号后出现(\d.\d)的情况中间插入换行符(\n)。
37、(3)中英文分号替换为\n。
38、(4)将中英文冒号(:)前的句子作为共享句子,添加到后续的每个分句中。
39、最后按照换行符(\n)拆分文档,组成知识库。
40、s3.3.3.2:使用faiss结合文本嵌入模型m3e-base,根据用户输入问题检索知识库中的知识作为背景知识,同时记录知识来源文件。
41、s3.3.3.3:将用户输入问题和知识库背景知识组成prompt,进一步将该prompt输入到大模型,得到大模型的总结性答案,作为知识库答案。使用的大模型和s3.3.2步骤一致。
42、在一优选的实施方式中,所述步骤s1中,抽取转化是指从自然语言文本抽取出可能存在的实体提及,识别问题文本所询问的关键对象,是为了进一步探索问答系统新范式而设计的;一方面基于自然语言处理模型提取出文本中可能存在的实体提及,能智能地实现关键词抽取,适应不断变化的提问语境;另一方面利用文本相似性算法抽取知识库中的相关知识,可以增强大语言模型回答的专业性,很大程度上减轻了大语言模型的幻觉问题;除此之外,本系统还实现了用户友好的交互服务。
43、在一优选的实施方式中,所述步骤s3中,系统交互流程如下:(1)用户向系统提出问题,问题经过预处理后,输入命名实体识别模块和实体链接模块完成问题与知识图谱候选实体的链接;(2)问题结合链接成功的候选实体,通过文本分类模型完成意图识别和模板匹配;(3)根据识别的意图和模板,系统自动选择对于该问题的回答方式,包括知识图谱查询、知识图谱推理、结合知识库与提示词询问大语言模型和单独询问大语言模型;(4)根据不同的回答方式返回不同类型的答案,并通过不同样式的界面将该答案返回给用户。
44、综上所述,由于采用了上述技术方案,本发明的有益效果是:
45、1、本发明中,提供了一套完善的问答系统构建方法。针对水利行业的数据特点,从多个维度对问答系统进行定制,给出了一套完善的问答系统构建方法,包括模型选择,训练策略和数据集构建方式等。在保证功能准确率的前提下,不仅强化了深度学习技术在问答系统中的能力,还充分发挥了知识图谱等技术在问答系统中的作用。
46、2、本发明中,针对知识图谱内的重要数据,问答系统利用规则模板和cypher查询语句给出知识图谱答案,用户可直观地查看知识脉络,并通过双击扩展等操作查看知识实体之间的联系;针对知识库内的一般数据,问答系统通过大语言模型给出总结性答案,不仅避免了用户阅读大量文件的繁琐工作,还同时给出了知识原文与来源文件,实现有理有据的问答效果;针对广泛的其他数据,问答系统通过大语言模型给出答案,确保用户询问的所有问题都能得到回答,改善了用户的使用体验。
- 还没有人留言评论。精彩留言会获得点赞!