一种基于统计特征和词图的轻量级中文关键词提取方法与流程
本发明涉及一种中文关键词提取方法,尤其涉及一种基于统计特征和词图的轻量级中文关键词提取方法,属于文本挖掘。
背景技术:
1、随着信息时代的快速发展,文本数据的量级呈现爆炸式增长。互联网上大多数文章缺少关键词标注,而关键词在对文本数据进行简洁描述、分类、检索等方面具有重要意义。对于检索等需要标注文档的工作,进行人工的标注耗时耗力。通过自动化的标注手段,可以实时地生成关键词列表;对于阅读文章的用户来说,读者通过关键词,无需阅读整篇文章便可了解文章的内容。此外,关键词可以吸引对特定方面感兴趣的用户阅读文章。
2、关键词提取技术分为无监督和有监督方法。其中无监督方法包括基于统计特征的方法和基于词图的方法。基于统计特征的方法基于文本构造出特征,根据特征生成关键词,如tf-idf(term frequency-inverse document frequency)方法通过词频和逆文档频率这两个特征来给词语评分,yake(yet another keyword extractor)通过多个特征给出词语得分。基于词图的方法按照pagerank的想法,将词语在特定窗口下的共现考虑成连接关系,为每个词分配一个得分。有监督的方法通过机器学习的方式,训练关键词提取模型。比如kea(keyphrase extraction algorithm)通过朴素贝叶斯方法来确定关键词,keybert基于bert(bidirectional encoder representation from transformers)模型来确定关键词。
3、现有的方法对文本关键词的自动标注有巨大的推动作用,它们在特定类型的文本上取得了一定的效果。但同样在应用上存在局限,比如tf-idf需要额外的语料,yake的特征设计更适用于欧美语言,在中文上效果欠佳,keybert方法需要专业的语料库训练模型等。我们需要一种轻量化、准确、适用于中文的关键词提取方法。它应当满足以下条件:
4、1.无监督方法:不需要在特定数据上训练专有模型。
5、2.与领域和语料库无关:可以从单篇文本检索信息,不需要使用特定领域的语料库。
6、3.适用于中文:按照中文文本的语言特点设计。
7、4.快速的轻量级方法:直接针对单篇文章快速给出结果。
8、5.精准的关键词得分和排序:不仅给出具体关键词,还要给出每个词的得分,并可以通过得分明显的区别出词的重要性程度。
技术实现思路
1、本发明的目的是:提供一种基于统计特征和词图的轻量级中文关键词提取方法。
2、为解决上述技术问题,本发明采用的技术方案是:
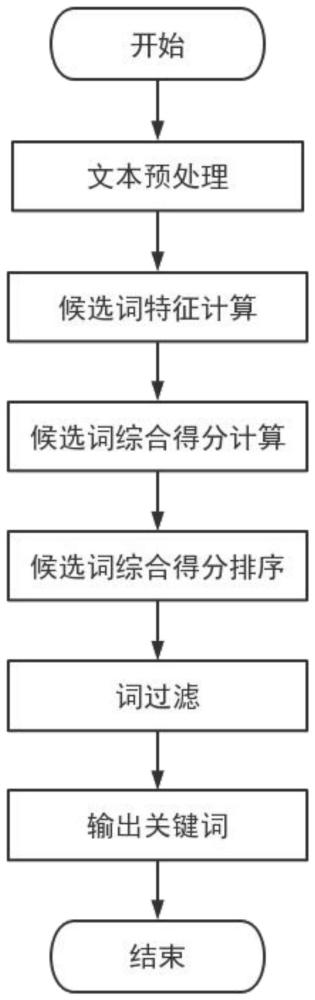
3、一种基于统计特征和词图的轻量级中文关键词提取方法,包括以下步骤:
4、步骤1:文本预处理,由以下具体步骤组成:
5、步骤1-1:根据设定的分句符号划分文本,形成文本单元;
6、步骤1-2:将各文本单元中的大写英文字母转换为小写英文字母。
7、步骤1-3:使用“结巴”分词将各文本单元划分为一个以上词,然后过滤掉各文本单元中出现在停用词表中的词;
8、步骤1-4:特殊词标记,按照预设规则标注文本单元中的特殊词;
9、步骤2:逐一计算各词的特征:由以下具体步骤组成:
10、假定n为文本单元数量,tf为当前词在各文本单元中出现次数之和,m为出现当前词的个文本单元数量,当前词出现的文本单元序号集合为{s1,s2,s3,……,sm},其中1≤s1<s2<s3<……<sm≤n。
11、步骤2-1:计算词频特征tf:
12、tf=tf
13、步骤2-2:计算位置特征pos:
14、
15、
16、其中,c为常数。
17、步骤2-3:计算分布跨度特征ds:
18、
19、步骤2-4:计算句子频率特征sf:
20、
21、步骤2-5:计算特殊词特征sw:
22、
23、
24、其中,a为常数。
25、步骤2-6:计算词图分数trs,由以下步骤组成:
26、步骤a-1:计算词邻连接矩阵,词邻连接矩阵的元素为两个词在预设窗口内同时出现的频次。
27、步骤a-2:根据词邻接矩阵构建无向图g,每个词作为无向图g的一个顶点,如两个词在一定预设窗口内同时出现过,两个顶点之间就存在边,两个词同时出现的频次作为边的权重。
28、步骤a-3:初始化各词的分数,并且按照以下公式进行迭代计算,直到收敛。
29、
30、其中wi表示第i个词,n各文本单元中的词的总数目,α为常数,e(g)表示图g的边,u(wi,wj)表示连接第i个词和第j个词对应顶点间的边的权重,tr(wi)为第i个词的分数。
31、步骤a-4:对各词语分数进行min-max标准化,得到词图分数trs。
32、
33、步骤3:计算各词综合得分s:
34、
35、
36、其中,表示文本单元中的各词的词频均值。
37、步骤4:排序和过滤
38、步骤4-1:对各词综合得分s进行排序。
39、步骤4-2:使用词典对词过进行滤,只保留存在于词典中的词。
40、步骤4-3:计算各词间的杰卡德距离:
41、
42、其中wi和wj表示第i个和第j个词,wi表示词wi中字的集合,wj表示词wj中字的集合,|wi∩wj|表示第i个和第j个词共同出现的字的数目,|wi∪wj|表示第i个和第j个词中所有出现的字的数目。
43、步骤4-4:判断各词间的杰卡德距离是否小于预设阈值,如果是,删除综合得分s低的词,保留下来的词及其得分作为关键词输出。
44、进一步,步骤-1-1中的分句符号包括中英文句号、问号、感叹号、省略号、分号。
45、进一步,步骤1-1使用“结巴”分词将各文本单元划分为一个以上词。
46、进一步,步骤1-3中停用词表中的词包括虚词和标点符号。
47、进一步,步骤1-4中预设规则为中文文本中出现的英文词或者是通过标点符号连接的英文词和数字。
48、采用上述技术方案,本发明的有益效果是:
49、1、本发明基于统计特征和词图信息,得到了准确的关键词提取结果和有区分度的关键词得分。
50、2、本发明有以下优势:适用于单篇中文文本;轻量级、无需模型训练和额外语料库;广泛的适用于不同领域的文本。
技术特征:
1.一种基于统计特征和词图的轻量级中文关键词提取方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于统计特征和词图的轻量级中文关键词提取方法,其特征在于,步骤-1-1中的分句符号包括中英文句号、问号、感叹号、省略号、分号。
3.根据权利要求1所述的基于统计特征和词图的轻量级中文关键词提取方法,其特征在于,步骤1-1使用“结巴”分词将各文本单元划分为一个以上词。
4.根据权利要求1所述的基于统计特征和词图的轻量级中文关键词提取方法,其特征在于,步骤1-3中停用词表中的词包括虚词和标点符号。
5.根据权利要求1所述的基于统计特征和词图的轻量级中文关键词提取方法,其特征在于,步骤1-4中预设规则为中文文本中出现的英文词或者是通过标点符号连接的英文词和数字。
技术总结
本发明公开一种基于统计特征和词图的适用于单篇中文文本的关键词提取方法,包括文本预处理、逐一计算各词的特征、计算各词综合得分、排序和过滤步骤。词的特征包括词频特征、位置特征、分布跨度特征、句子频率特征、特殊词特征和词图分数。本发明基于统计特征和词图信息,得到了准确的关键词提取结果和有区分度的关键词得分。本发明具有以下优势:适用于单篇中文文本;轻量级、无需模型训练和额外语料库;广泛的适用于不同领域的文本。
技术研发人员:郭奇,田立军
受保护的技术使用者:金叶天成(北京)科技有限公司
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!