一种多模态数据集自动标注的方法与流程
本申请涉及数据标注,尤其涉及一种多模态数据集自动标注的方法。
背景技术:
1、视觉定位(visual grounding)任务涉及图片与文本两个模态,输入图片和实例文本描述后,先分别理解图片和文本描述,再融合图片与文本信息,最后利用融合特征进行定位预测,输出实例描述对应的矩形框。视觉定位数据集的标注分为文本描述与矩形框两部分,其标注复杂度高,人工标注效率低,因此,亟需一种高效的自动标注方法。
2、随着大模型技术的快速发展,为数据集的自动标注提供了强大的支持。视觉文本多模态模型可生成图片的文本描述,但由于幻觉现象的存在影响了标注效率,幻觉指的是文本描述与图片实际内容不符合。如何对文本描述进行优化,从而提高标注效率有待解决。
技术实现思路
1、本申请提供了一种多模态数据集自动标注的方法,其技术目的是实现多模态数据集的自动标注,提高标注效率。
2、本申请的上述技术目的是通过以下技术方案得以实现的:
3、一种多模态数据集自动标注的方法,包括:
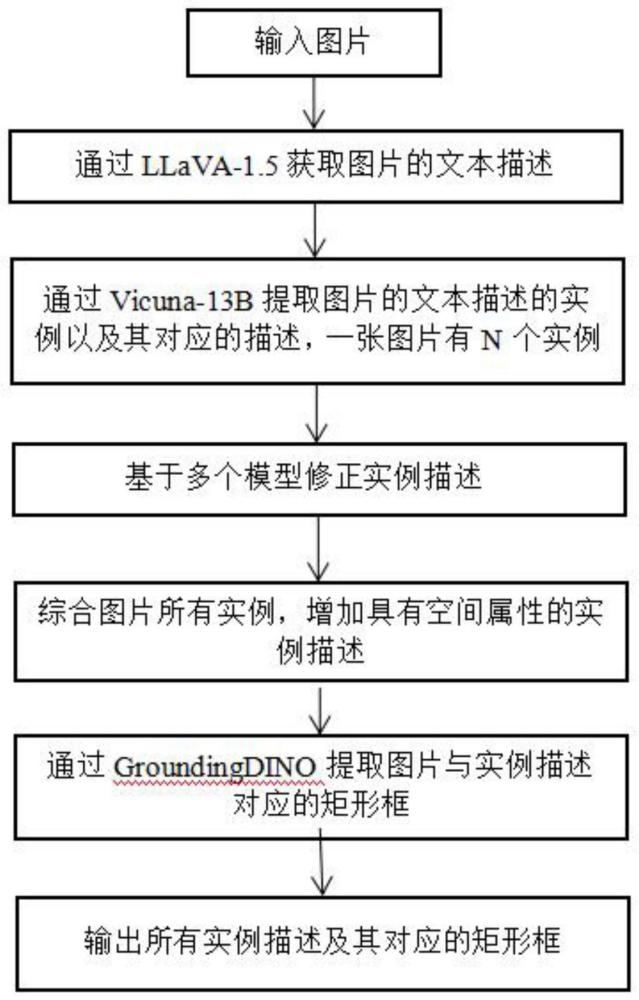
4、步骤s1:将图片输入到多模态模型llava-1.5,对图片的文本描述进行获取;
5、步骤s2:将图片的文本描述输入到大语言模型vicuna-13b,对文本描述中的实例及其对应的描述进行获取,得到多个第一实例描述;
6、步骤s3:通过检测模型grounding dino对第一实例描述进行修正,得到第二实例描述;
7、步骤s4:对第二实例描述的空间属性进行增加,得到第三实例描述;
8、步骤s5:通过检测模型grounding dino对图片与第三实例描述对应的矩形框进行提取,并输出第三实例描述及其对应的矩形框,完成多模态数据集的自动标注。
9、进一步地,所述步骤s3包括:
10、步骤s31:将图片和第一实例描述输入至检测模型grounding dino后,对检测模型grounding dino是否输出检测框进行判断,若是转至步骤s32,若否则说明该第一实例描述不存在于图片,将该第一实例描述删除;
11、步骤s32:采用blip-2算法对图片与第一实例描述的相似度进行计算;
12、步骤s33:对相似度是否高于预设阈值进行判断,若是则保留该第一实例描述作为第二实例描述,否则转至步骤s34;
13、步骤s34:对第一实例描述中的实例是否为人物进行判断,若是转至步骤s35,否则转至步骤s36;
14、步骤s35:通过人物属性模型对人物属性进行获取,然后通过大语言模型vicuna-13b将人物属性描述成句,将该句添加到第一实例描述中,得到第二实例描述;
15、步骤s36:生成物体颜色提问句,通过blip-2算法的视觉问答功能得到实例的物体颜色属性,然后将物体颜色属性添加到第一实例描述中,得到第二实例描述。
16、进一步地,所述步骤s4包括:
17、步骤s41:对图片的所有第二实例描述行中是否包括空间属性的关键词进行判断,若是则保留该第二实例描述作为第三实例描述,若否转至步骤s42;
18、步骤s42:对第二实例描述的检测框与其他所有第二实例描述的检测框的中心点欧式距离进行计算;
19、步骤s43:将中心点欧氏距离小于阈值的检测框对筛选出来;
20、步骤s44:根据中心点的x轴坐标对检测框对的左右关系进行确定,得到各检测框的空间属性;
21、步骤s45:在检测框对应的第二实例描述中加入检测框的空间属性,得到第三实例描述。
22、进一步地,所述步骤s44中,所述空间属性包括:x轴坐标较小的检测框在左边,x轴坐标较大的检测框在右边。
23、本申请的有益效果在于:本申请所述的多模态数据集自动标注的方法,通过多模态模型llava-1.5获取图片的文本描述,通过大语言模型vicuna-13b提取文本描述中的实例,再基于多个模型修正实例描述,且新增具有空间属性的实例描述,最后根据检测模型grounding dino获取图片与实例描述对应的矩形框,完成多模态数据集的自动标注,显著提高了标注效率。
技术特征:
1.一种多模态数据集自动标注的方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,所述步骤s3包括:
3.如权利要求1所述的方法,其特征在于,所述步骤s4包括:
4.如权利要求3所述的方法,其特征在于,所述步骤s44中,所述空间属性包括:x轴坐标较小的检测框在左边,x轴坐标较大的检测框在右边。
技术总结
本发明公开了一种多模态数据集自动标注的方法,涉及数据标注技术领域,解决了多模态数据集标注效率较低的技术问题,其技术方案要点是通过多模态模型LLaVA‑1.5获取图片的文本描述,通过大语言模型Vicuna‑13B提取文本描述中的实例,再基于多个模型修正实例描述,且新增具有空间属性的实例描述,最后根据检测模型Grounding DINO获取图片与实例描述对应的矩形框,完成多模态数据集的自动标注,显著提高了标注效率。
技术研发人员:杨帆,朱莹,张凯翔
受保护的技术使用者:小视科技(江苏)股份有限公司
技术研发日:
技术公布日:2024/4/7
- 还没有人留言评论。精彩留言会获得点赞!